













使用LlamaIndex和ChatGPT的無代碼檢索增強生成(RAG)
譯文譯者 | 李睿
審校 | 重樓
檢索增強生成(RAG)是使用大型語言模型(LLM)的關鍵工具。RAG使LLM能夠將外部文檔合并到它們的響應中,從而更緊密地與用戶需求保持一致。這個功能在傳統上使用LLM猶豫不決的領域尤其有益,尤其是在事實很重要的時候。
自從ChatGPT和類似的LLM推出以來,出現了大量的RAG工具和庫。以下是需要了解的關于RAG如何工作以及如何開始使用它與ChatGPT、Claude或選擇的LLM。
RAG提供的好處
當開發人員與大型語言模型交互時,它會利用其訓練數據中嵌入的知識來制定響應。然而,規模龐大的訓練數據往往超過模型的參數,導致響應可能不完全準確。此外,訓練中使用的各種信息可能會導致LLM混淆細節,可能提供看似合理但不正確的答案,這種現象被稱為“幻覺”。
在某些情況下,開發人員可能希望LLM使用未包含在其訓練數據中的信息,例如最近發布的新聞文章、學術論文或專有公司文檔。這就是RAG發揮重要作用的地方。
RAG通過在LLM生成響應之前為其提供相關信息來解決這些問題。這包括從外部源檢索文檔(因此得名),并將其內容插入到對話中,以向LLM提供場景。
這一過程增強了模型的準確性,并使其能夠根據提供的內容制定響應。實驗表明,RAG能顯著減少“幻覺”。在需要最新或客戶特定信息的應用程序中,它也被證明是有益的,這些信息不包括在訓練數據集中。
簡單地說,標準LLM和支持RAG的LLM之間的區別可以比喻成兩個人回答問題。標準LLM就像一個人根據記憶做出回應,而支持RAG的LLM則像獲得文件的另一個人,可以根據文件內容閱讀和回答問題。
RAG是如何工作的
RAG的工作原理很簡單。它標識與查詢相關的一個或多個文檔,將它們合并到提示中,并修改提示以包含模型基于這些文檔的響應的說明。
開發人員可以手動實現RAG,其方法是將文檔的內容復制粘貼到提示中,并指示模型根據該文檔制定響應。
RAG管道將這一過程實現自動化以提高效率。它首先將用戶的提示與文檔數據庫進行比較,檢索與主題最相關的提示。然后,RAG管道將它們的內容集成到提示符中,并添加指令以確保LLM符合文檔的內容。
RAG管道需要什么?
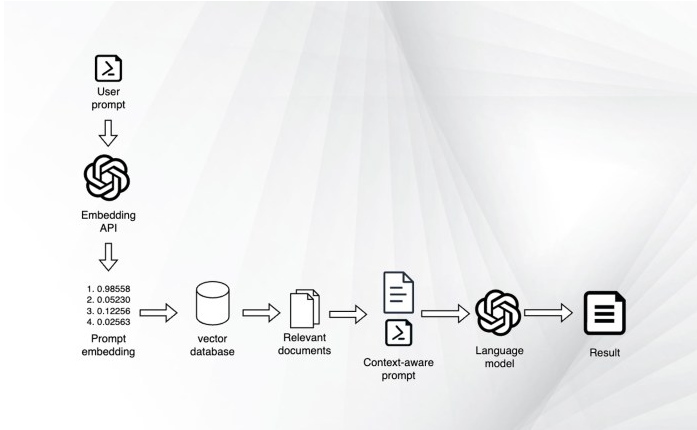
圖1 使用嵌入和矢量數據庫檢索相關文檔
雖然RAG是一個直觀的概念,但它的執行需要多個組件的無縫集成。
首先,需要生成響應的主要語言模型。除此之外,還需要一個嵌入模型將文檔和用戶提示編碼為表示其語義內容的數字列表或“嵌入”。
接下來,需要一個矢量數據庫來存儲這些文檔嵌入,并在每次收到用戶查詢時檢索最相關的文檔嵌入。在某些情況下,排序模型還有助于進一步細化向量數據庫提供的文檔的順序。
對于某些應用程序,開發人員可能希望合并一種額外的機制,將用戶提示分為幾個部分。這些部分中的每一個都需要自己獨特的嵌入和文檔,從而提高所生成響應的準確性和相關性。
如何在無代碼的情況下開始使用RAG
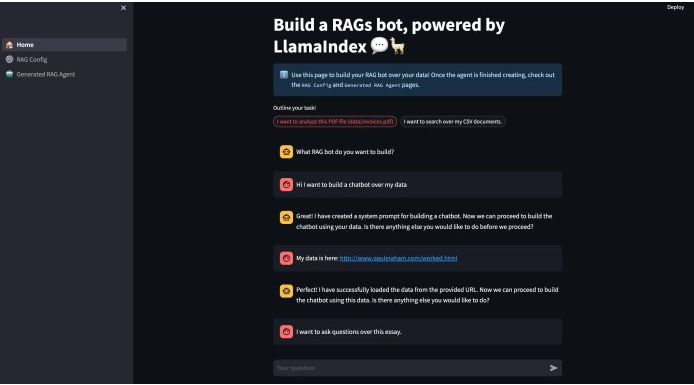
圖2 無代碼RAG與LlamaIndex和ChatGPT
LlamaIndex最近發布了一個開源工具,它允許開發人員開發基本的RAG應用程序,幾乎不需要編寫代碼。雖然目前僅限于單個文件的使用,但未來的增強功能可能包括對多個文件和矢量數據庫的支持。
這個名為RAG的項目建立在Streamlit web應用程序框架和LlamaIndex之上,LlamaIndex是一個強大的Python庫,對RAG特別有用。如果開發人員熟悉GitHub和Python,其安裝很簡單:只需克隆存儲庫,運行安裝命令,然后將OpenAI API令牌添加到自述文檔中指定的配置文件中。
目前,RAG被配置為與OpenAI模型一起工作。但是,可以修改代碼以使用其他模型,例如Anthropic Claude、Cohere模型或服務器上托管的開源模型(如Llama 2)。LlamaIndex支持所有這些模型。
應用程序的初始運行需要設置RAG代理。這涉及到確定設置,包括文件、將文件分成塊的大小,以及為每個提示檢索的塊的數量。
塊在RAG中起著至關重要的作用。當處理一個大文件時,例如一本書或一篇多頁的研究論文,有必要把它分解成可管理的塊,例如500個令牌。這允許RAG代理定位文檔中與提示相關的特定部分。
在完成這些步驟之后,應用程序將為RAG代理創建一個配置文件,并用它來運行代碼。RAG是一個有價值的工具,可以從增強檢索開始并在此基礎上進行構建。人們可以在相關網站上找到完整的指南。
原文標題:No-code retrieval augmented generation (RAG) with LlamaIndex and ChatGPT,作者:Ben Dickson
鏈接:https://bdtechtalks.com/2023/11/22/rag-chatgpt-llamaindex/





























