Adaptive-RAG:讓檢索增強生成更智能

在人工智能領域,檢索增強生成(Retrieval-Augmented Generation,RAG)一直是研究熱點。它通過結合檢索和生成技術,為問答系統帶來了更強大的性能。然而,現有的RAG方法并非完美無缺。它們在處理多跳推理或多步驟推理問題時可能力不從心,而且往往缺乏對檢索到的信息的有效利用能力。
今天,就來聊聊一種全新的方法,來自韓國科學技術院發表在2024 NAACL上的一篇工作:自適應檢索增強生成(Adaptive Retrieval-Augmented Generation,Adaptive-RAG)。

1、研究動機
在實際應用中,不難發現,并非所有問答場景都是復雜請求。有些問題簡單到直接使用語言模型(LLM)就能輕松回答,而有些問題則需要從多個文檔中綜合信息并進行多步推理。這就導致了一個問題:如果對所有問題都采用復雜的RAG策略,無疑會造成資源浪費;而如果對復雜問題只使用簡單的LLM方法,又無法得到準確的答案。那么,如何在效率和準確性之間找到一個平衡點呢?Adaptive-RAG應運而生。
2、方法介紹
現有LLMs問答策略
在深入探討Adaptive-RAG之前,先來了解一下現有的LLM問答策略。
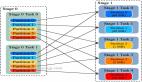
- 非檢索方法(Non-Retrieval for QA):對于一些簡單的查詢,LLM可以直接生成答案,無需進行額外的文檔檢索。不過,當問題涉及到需要精確或最新的知識時,如特定人物、事件或其他超出 LLM 內部知識范圍的主題,這種方法就顯得有些力不從心了。
- 單步檢索方法(Single-step Approach for QA):當LLM無法直接回答問題時,可以利用外部知識執行一次檢索操作,然后根據檢索到的信息生成答案。這種方法能夠為LLM缺乏內部知識提供補充上下文,從而提升問答的準確性和時效性。
- 多步檢索方法(Multi-step Approach for QA):在多步方法中,LLM與檢索模型進行多輪交互,逐步完善對查詢的理解,直到最終形成答案。這種方法能夠為LLM構建更全面的知識基礎,特別適合處理復雜的多跳查詢,但是會有更大的計算和資源開銷。

Adaptive-RAG
在實際應用中,并非所有用戶的查詢都具有相同的復雜程度,因此需要針對每個查詢定制處理策略。換句話說,對于復雜查詢,如果只使用最基本、不帶檢索的 LLM 方法(LLM(q)),則會無效;相反,對于簡單查詢,如果采用更復雜的多步驟方法(LLM(q, d, c)),則會導致資源浪費。因此,Adaptive-RAG 試圖找到一個平衡點,以提高效率和準確性。
- 查詢復雜度評估
Adaptive-RAG 的關鍵步驟是確定給定查詢的復雜度,從而選擇最合適的回答策略。為了實現這一點,本文訓練了一個小型的語言模型作為分類器,用來預測即將到達的查詢的復雜度級別。
具體來說,對于給定的查詢 q,分類器可以被公式化為:o = Classifier(q),其中 Classifier 是一個小的語言模型,它被訓練用來分類三個不同的復雜度等級,而 o 則是其對應的類別標簽。
在設計中,有三個類別標簽:
a.'A' 表示查詢 q 直接且可以用 LLM(q) 自身回答。
b. 'B' 表示查詢 q 具有中等復雜度,至少需要單步方法 LLM(q, d) 來解決。
c. 'C' 表示查詢 q 復雜,需要最全面的方法 LLM(q, d, c) 來解決。
- 訓練策略
使用T5-Large(770M)模型作為查詢復雜性分類器,對于分類器的訓練,關鍵步驟是如何準確預測查詢 q 的復雜度 o。然而,現實中并不存在帶有查詢復雜度標注的數據集。因此,本文提出了兩種特定策略來自動構建訓練數據集:
通過這兩種方式,可以在無需人工標注的情況下構造出適合訓練分類器的數據集。這種自動化收集標簽的方法不僅減少了人力成本,還確保了數據集的一致性和客觀性,使得分類器能夠學習到不同類型的查詢特征,并準確地對新查詢進行復雜度分類。
a.基于模型預測結果的自動標注:如果最簡單的非檢索方法 LLM(q) 能正確生成答案,則將對應的查詢標記為 'A'。
如果多步驟方法 LLM(q, d, c) 能正確生成答案,而非檢索方法 LLM(q) 不能,則將查詢標記為 'B' 或 'C',具體取決于是否還有更復雜的查詢未被標記。
b.利用數據集中的固有歸納偏見:一些數據集本身已經設計成包含用于單步或多重推理的問題,這些信息可以作為輔助來幫助標注查詢的復雜度。對于那些初次標注后仍未獲得標簽的查詢,如果它們來自單跳數據集,則標記為 'B';如果是多跳數據集,則標記為 'C'。
3、實驗配置
數據集
單跳問答數據集(Single-hop QA):用于模擬簡單查詢的場景,包括以下三個基準數據集:
- SQuAD v1.1:由標注者根據文檔編寫問題而創建的數據集。
- Natural Questions:由Google搜索的真實用戶查詢構建的數據集。
- TriviaQA:包含來自各種問答網站的瑣事問題。
多跳問答數據集(Multi-hop QA):用于模擬復雜查詢的場景,包括以下三個基準數據集:
- MuSiQue:通過組合多個單跳查詢來形成2-4跳查詢的數據集。
- HotpotQA:由標注者創建的問題鏈接多個維基百科文章。
- 2WikiMultiHopQA:從維基百科及其相關知識圖譜路徑派生而來,需要2跳。
指標
- 有效性指標:
F1:預測答案與真實答案之間重疊詞匯的數量。
EM(Exact Match):預測答案與真實答案是否完全相同。
Accuracy(Acc):預測答案是否包含真實答案。 - 效率指標:
Step:檢索和生成步驟的數量。
Time:相對于單步方法,回答每個查詢所需的平均時間。
4、實驗結果
主要結果
整體性能:表1展示了所有數據集的平均結果,驗證了簡單檢索增強策略的有效性低于復雜策略,而復雜策略的計算成本顯著高于簡單策略。Adaptive-RAG在保持高效的同時,顯著提高了問答系統的整體準確性和效率。

詳細結果:表2提供了使用FLAN-T5-XL模型在各個單跳和多跳數據集上的更詳細結果,與表1中的觀察結果一致。Adaptive-RAG在處理復雜查詢時表現出色,尤其是在多跳數據集上,能夠有效地聚合多個文檔的信息并進行推理。

理想情況下的性能:通過使用理想分類器(Oracle)的Adaptive-RAG,展示了模型在完美分類查詢復雜性情況下的性能上限。結果表明,它在效果上達到了最佳表現,同時比沒有理想分類器的Adaptive-RAG更加高效。這些結果支持了根據查詢復雜度自適應選擇檢索增強LLM策略的有效性和重要性。
分類器性能
分類準確性:圖3展示了Adaptive-RAG的分類器在不同復雜性標簽上的性能,其分類準確性優于其他自適應檢索方法。這表明Adaptive-RAG能夠更準確地將查詢分類為不同復雜性級別,從而為選擇合適的檢索策略提供依據。
混淆矩陣:圖3中的混淆矩陣揭示了一些分類趨勢,例如“C(多步)”有時被錯誤分類為“B(單步)”,“B(單步)”有時被錯誤分類為“C(多步)”。這為未來改進分類器提供了方向。

分類器效率分析
查詢處理時間:表3提供了Adaptive-RAG每條查詢的精確處理時間以及分類器預測標簽的分布情況。結果表明,通過有效識別簡單或直接的查詢,可以顯著提高效率。

分類器訓練數據分析
訓練策略對比:表4展示了不同訓練策略對分類器性能的影響。作者提出的訓練策略(結合模型預測結果和數據集偏見)在效率和準確性方面均優于僅依賴數據集偏見或僅使用銀標準數據的策略。這表明,結合多種信息源可以提高分類器的性能。

分類器大小分析
模型大小對性能的影響:表6顯示了不同大小分類器的性能。結果表明,即使在分類器規模較小、復雜度較低的情況下,性能也沒有顯著差異。這表明Adaptive-RAG可以在資源受限的環境中使用較小的分類器,而不影響整體性能。

案例研究
簡單查詢處理:對于簡單的單跳問題,Adaptive-RAG能夠識別出僅使用LLM的參數知識即可回答,而無需檢索外部文檔。相比之下,其他自適應方法可能會檢索額外的文檔,導致處理時間延長,并可能因包含部分不相關信息而產生錯誤答案。
復雜查詢處理:面對復雜問題時,Adaptive-RAG能夠尋找相關的信息,包括LLM中可能未存儲的細節,如“John Cabot的兒子是誰”,而其他自適應方法可能無法從外部源請求此類信息,從而導致不準確的答案。

5、總結
Adaptive-RAG是一種非常有意思的方法。它通過一個小模型輔助LLM判斷是否需要單步檢索或多步檢索,相比一些直接微調LLM的方法(如Self-RAG),不僅更高效,而且性能也更優。
但是如果要在檢索推理性能上扣細節的話,這種策略還是有很多優化空間,比如在2023 ACL上的一篇文章《When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories》評估了LLM檢索哪些類型的知識對模型性能的提高更有益,哪些類型的知識可能會損害模型性能,這些皆是可以使用小模型輔助LLM判斷的參考信息。
這種方法為普通玩家提供了一個可行的解決方案,也為RAG方法的優化提供了新的思路。