













超越同級7B模型! 中國團隊開源大規模高質量圖文數據集ShareGPT4V,大幅提升多模態性能
OpenAI在九月份為ChatGPT添加了圖像輸入功能,允許用戶使用上傳一張或多張圖像配合進行對話,這一新興功能的背后是一個被OpenAI稱為GPT4-Vision的多模態(vision-language)大模型。
鑒于OpenAI對「閉源」的堅持,多模態開源社區如雨后春筍般涌出了眾多優秀的多模態大模型研究成果,例如兩大代表作MiniGPT4和LLaVA已經向用戶們展示了多模態對話和推理的無限可能性。
在多模態大模型(Large Multi-modal Models)領域,高效的模態對齊(modality alignment)是至關重要的,但現有工作中模態對齊的效果卻往往受制于缺少大規模的高質量的「圖像-文本」數據。
為了解決這一瓶頸,近日,中科大和上海AI Lab的研究者們最近推出了具有開創性意義的大型圖文數據集ShareGPT4V。

論文地址:https://arxiv.org/abs/2311.12793
Demo演示:https://huggingface.co/spaces/Lin-Chen/ShareGPT4V-7B
項目地址:https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V
ShareGPT4V數據集包含120萬條「圖像-高度詳細的文本描述」數據,囊括了了世界知識、對象屬性、空間關系、藝術評價等眾多方面,在多樣性和信息涵蓋度等方面超越了現有的數據。

表1 ShareGPT4V和主流標注數據集的比較。其中「LCS」指LAION, CC和SBU數據集,「Visible」指明了圖片在被標注時是否可見,「Avg.」展示了文本描述的平均英文字符數。
目前,該數據集已經登上了Hugging Face Datasets Trending排行第一。
數據
ShareGPT4V來源于從先進的GPT4-Vision模型獲得的10萬條「圖像-高度詳細的文本描述」數據。
研究者們從多種圖片數據源(如COCO,LAION,CC,SAM等)搜集圖片數據,接著使用各自數據源特定的prompt來控制GPT4-Vision產生高質量的初始數據。
如下圖所示,給GPT4-Vision模型一張《超人》劇照,其不僅可以準確地識別出《超人》劇照中的超人角色以及其扮演者Henry Cavill,還可以充分分析出圖像內物體間的位置關系以及物體的顏色屬性等。
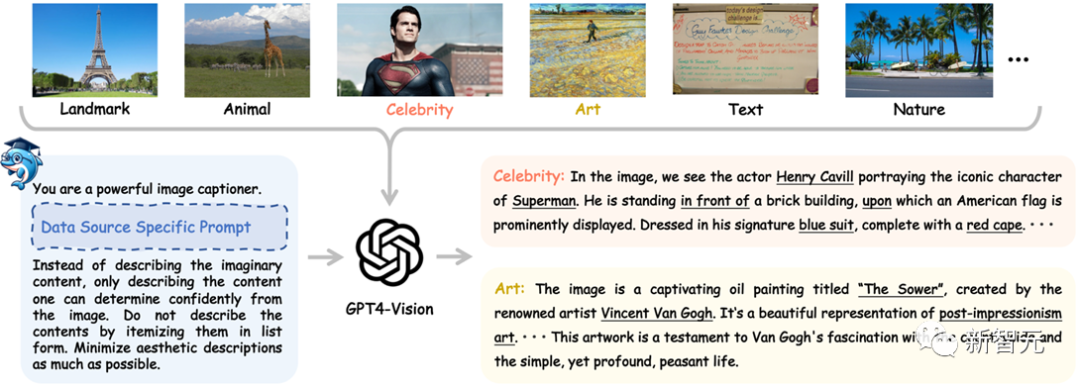
圖1 利用GPT4-Vision 收集ShareGPT4V原始數據流程圖
如果給GPT4-Vision模型一個梵高的畫作《播種者》,其不僅可以準確地識別出畫作的名稱,創作者,還可以分析出畫作所屬的藝術流派,畫作內容,以及畫作本身表達出的情感與想法等信息。
為了更充分地與現有的圖像描述數據集進行對比。我們在下圖中將ShareGPT4V數據集中的高質量文本描述與當前多模態大模型所使用的數據集中的文本描述一起羅列出來:

圖 2 「圖片-文本描述」數據質量對比圖
從圖中可以看出,使用人工標注的COCO數據集雖然正確但通常十分的短,提供的信息極其有限。
LLaVA數據集使用語言模型GPT4想象出的場景描述通常過度依賴bounding box而不可避免地帶來幻覺問題。比如bounding box確實會提供8個人的標注,但其中兩個人在火車上而不是在等車。
其次,LLaVA數據集還只能局限于COCO的標注信息,通常會遺漏人工標注中沒提及的內容(比如樹木)。
在比較之下,我們收集的圖像描述不僅可以給出綜合性的描述,還不容易遺漏圖像中的重要信息(比如站臺信息和告示牌文字等)。
通過在該初始數據上進行深入訓練后,研究者們開發出了一個強大的圖像描述模型Share-Captioner。利用這一模型,他們進一步生成了120萬高質量的「圖片-文本描述」數據ShareGPT4V-PT以用于預訓練階段。

圖3 圖像描述模型擴大數據集規模流程圖
Share-Captioner在圖像描述能力上有著媲美GPT4-Vision的水平,下面是對于同一張圖片的不同來源的文本描述:

圖4 不同來源圖像描述對比圖
從上圖可以看出Share-Captioner縮小了與GPT4-Vision模型在圖像描述任務上的能力。可以作為收集大規模高質量圖文數據對的「平替」。
實驗
研究者們首先通過等量替換實驗,在有監督微調(SFT)階段充分展示了ShareGPT4V數據集的有效性。
從圖中可以看出,ShareGPT4V數據集可以無縫地使得多種架構、多種參數規模的多模態模型的性能得到大幅提升!
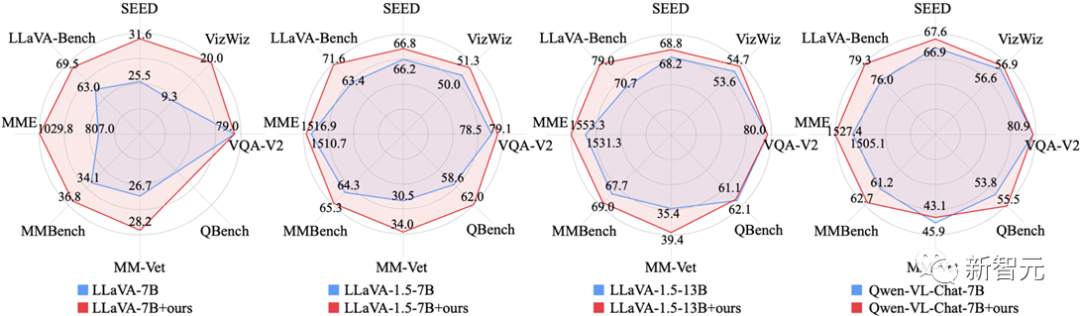
圖5 使用ShareGPT4V數據集等量替換SFT中圖像描述數據后模型效果對比圖
接下來,研究者們將ShareGPT4V數據集同時在預訓練和有監督微調階段使用,得到了ShareGPT4V-7B模型。
ShareGPT4V-7B在絕大多數多模態基準測試中都取得了非常優異的成果,在7B的模型規模全部取得了最優的性能!

圖6 ShareGPT4V-7B在各個多模態基準測試上的表現
總體而言,ShareGPT4V數據集的推出為未來的多模態研究與應用奠定了新的基石。多模態開源社區有望著眼于高質量圖像描述開發出更強大、智能的多模態模型。

























