谷歌:LLM找不到推理錯誤,但能糾正它
今年,大型語言模型(LLM)成為 AI 領域關注的焦點。LLM 在各種自然語言處理(NLP)任務上取得了顯著的進展,在推理方面的突破尤其令人驚艷。但在復雜的推理任務上,LLM 的表現仍然欠佳。
那么,LLM 能否判斷出自己的推理存在錯誤?最近,劍橋大學和 Google Research 聯合開展的一項研究發現:LLM 找不到推理錯誤,但卻能使用該研究提出的回溯(backtracking)方法糾正錯誤。

- 論文地址:https://arxiv.org/pdf/2311.08516.pdf
- 數據集地址:https://github.com/WHGTyen/BIG-Bench-Mistake
這篇論文引起了一些爭論,有人提出異議,比如在 Hacker News 上,有人評論這篇論文的標題言過其實,有些標題黨。也有人批評說其中提出的校正邏輯錯誤的方法基于模式匹配,而非采用邏輯方法,這種方法其實容易失敗。
Huang 等人在論文《Large language models cannot self-correct reasoning yet》中指出:自我校正或許是能有效地提升模型輸出的風格和質量,但鮮有證據表明 LLM 有能力在沒有外部反饋的情況下識別和糾正自身的推理和邏輯錯誤。比如 Reflexion 和 RCI 都使用了基本真值的糾正結果作為停止自我校正循環的信號。
劍橋大學和 Google Research 的研究團隊提出了一種新思路:不再把自我校正看作一個單一過程,而是分成錯誤發現和輸出校正兩個過程:
- 錯誤發現是一種基礎推理技能,已經在哲學、心理學和數學領域得到了廣泛的研究和應用,并催生了批判性思維、邏輯和數學謬誤等概念。我們可以合理地認為發現錯誤的能力也應該是 對 LLM 的一項重要要求。但是,本文結果表明:當前最佳的 LLM 目前還無法可靠地發現錯誤。
- 輸出校正涉及部分或完全修改之前生成的輸出。自我校正是指由生成輸出的同一模型來完成校正。盡管 LLM 沒有發現錯誤的能力,但本文表明:如果能提供有關錯誤的信息(如通過一個小型的監督式獎勵模型),LLM 可以使用回溯方法校正輸出。
本文的主要貢獻包括:
- 使用思維鏈 prompt 設計方法,任何任務都可以變成錯誤發現任務。研究者為此收集并發布了一個 CoT 類型的軌跡信息數據集 BIG-Bench Mistake,該數據集由 PaLM 生成,并標注了第一個邏輯錯誤的位置。研究者表示,BIG-Bench Mistake 在它的同類數據集中,是首個不局限于數學問題的數據集。
- 為了測試當前最佳 LLM 的推理能力,研究者基于新數據集對它們進行了基準評測。結果發現,當前 SOTA LLM 也難以發現錯誤,即便是客觀的明確的錯誤。他們猜測:LLM 無法發現錯誤是 LLM 無法自我校正推理錯誤的主要原因,但這方面還有待進一步研究。
- 本文提出使用回溯方法來校正輸出,利用錯誤的位置信息來提升在原始任務上的性能。研究表明這種方法可以校正原本錯誤的輸出,同時對原本正確的輸出影響極小。
- 本文將回溯方法解釋成了「言語強化學習」的一種形式,從而可實現對 CoT 輸出的迭代式提升,而無需任何權重更新。研究者提出,可以通過一個經過訓練的分類器作為獎勵模型來使用回溯,他們也通過實驗證明了在不同獎勵模型準確度下回溯的有效性。
BIG-Bench Mistake數據集
BIG-Bench 由 2186 個 CoT 風格的軌跡信息集合組成。每個軌跡由 PaLM 2-L-Unicorn 生成,并標注了第一個邏輯錯誤的位置。表 1 展示了一個軌跡示例,其中錯誤位于第 4 步。

這些軌跡來自 BIG-Bench 數據集中的 5 個任務:詞排序、跟蹤經過混洗的對象、邏輯推演、多步算術和 Dyck 語言。
他們使用 CoT prompt 設計法來調用 PaLM 2,使其解答每個任務的問題。為了將 CoT 軌跡分成明確的步驟,他們使用了論文《React: Synergizing reasoning and acting in language models》中提出的方法,分開生成每一步,并使用了換行符作為停止 token。
在該數據集中,生成所有軌跡時,temperature = 0。答案的正確性由精確匹配決定。
基準測試結果
表 4 報告了 GPT-4-Turbo、GPT-4 和 GPT-3.5-Turbo 在新的錯誤發現數據集上的準確度。

對于每個問題,可能的答案有兩種情況:要么沒有錯誤,要么就有錯誤。如有錯誤,則數值 N 則會指示第一個錯誤出現的步驟。
所有模型都被輸入了同樣的 3 個 prompt。他們使用了三種不同的 prompt 設計方法:
- 直接的軌跡層面的 prompt 設計
- 直接的步驟層面的 prompt 設計
- CoT 步驟層面的 prompt 設計
相關討論
研究結果表明,這三個模型都難以應對這個新的錯誤發現數據集。GPT 的表現最好,但其在直接的步驟層面的 prompt 設計上也只能達到 52.87 的總體準確度。
這說明當前最佳的 LLM 難以發現錯誤,即使是在最簡單和明確的案例中。相較之下,人類在沒有特定專業知識時也能發現錯誤,并且具有很高的一致性。
研究者猜測:LLM 無法發現錯誤是 LLM 無法自我校正推理錯誤的主要原因。
prompt 設計方法的比較
研究者發現,從直接軌跡層面的方法到步驟層面的方法再到 CoT 方法,無錯誤的軌跡準確度顯著下降。圖 1 展示了這種權衡。
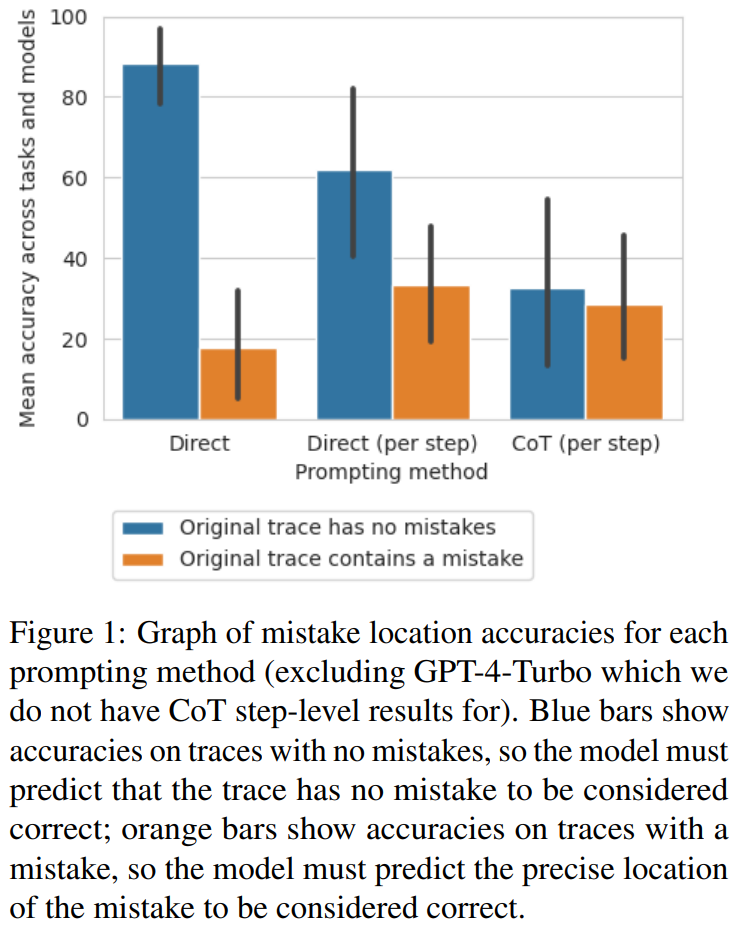
研究者猜測其原因是模型生成的輸出的數量。這三種方法涉及到生成越來越復雜的輸出:直接的軌跡層面的 prompt 設計方法需要單個 token,直接的步驟層面的 prompt 設計方法每步需要一個 token,CoT 步驟層面的 prompt 設計每步需要多個句子。如果每次生成調用都有一定的概率識別出錯誤,那么對每條軌跡的調用越多,模型識別出至少一個錯誤的可能性就越大。
將錯誤位置作為正確性代理的少樣本 prompt 設計
研究者探究了這些 prompt 設計方法能否可靠地決定一個軌跡的正確性,而不是錯誤位置。
他們計算了平均 F1 分數,依據為模型能否預測軌跡中是否存在錯誤。如果存在錯誤,則假設模型預測的是該軌跡是 incorrect_ans。否則就假設模型預測的是該軌跡是 correct_ans。
使用 correct_ans 和 incorrect_ans 作為正例標簽,并根據每個標簽的出現次數進行加權,研究者計算了平均 F1 分數,結果見表 5。
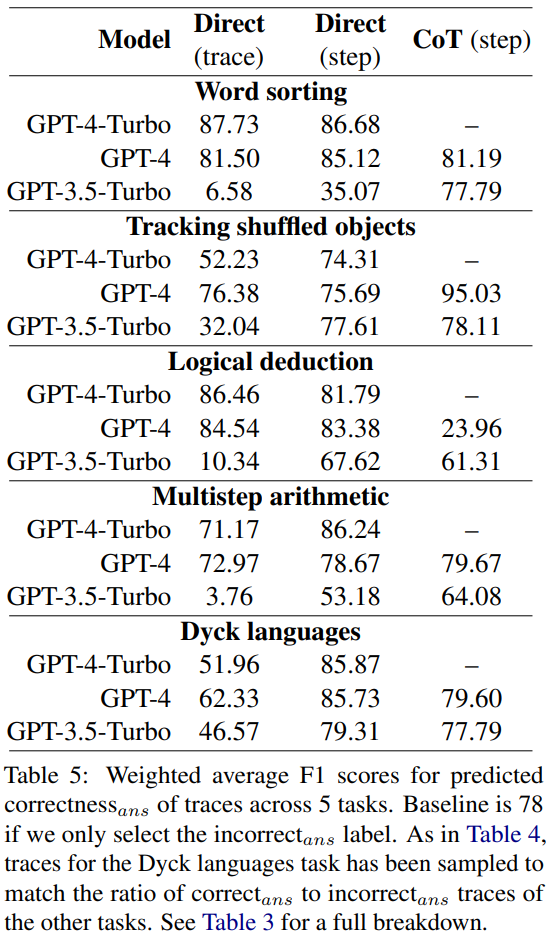
這個加權 F1 分數表明,對于確定最終答案的正確性而言,通過 prompt 尋找錯誤是一個很糟糕的策略。
回溯
Huang 等人指出 LLM 無法在沒有外部反饋的情況下自我校正邏輯錯誤。但是,在許多真實世界應用中,通常沒有可用的外部反饋。
研究者在這項研究中采用了一種替代方案:用一個在少量數據上訓練的輕量級分類器替代外部反饋。與傳統強化學習中的獎勵模型類似,這個分類器可以檢測 CoT 軌跡中的任何邏輯錯誤,然后再將其反饋給生成器模型以提升輸出。如果想要最大化提升,可以進行多次迭代。
研究者提出了一種簡單的回溯方法,可以根據邏輯錯誤的位置來提升模型的輸出:
- 模型首先生成一個初始的 CoT 軌跡。在實驗中,設置 temperature = 0。
- 然后使用獎勵模型確定軌跡中錯誤的位置。
- 如果沒有錯誤,就轉向下一個軌跡。如果有錯誤,則再次向模型輸入 prompt 以執行相同的步驟,但這一次 temperature = 1,生成 8 個輸出。這里會使用同樣的 prompt 以及包含錯誤步驟之前所有步驟的部分軌跡。
- 在這 8 個輸出中,過濾掉與之前的錯誤一樣的選項。再從剩下的輸出中選擇對數概率最高的一個。
- 最后,用新的重新生成的步驟替換之前步驟,再重新設置 temperature = 0,繼續生成該軌跡的剩余步驟。
相比于之前的自我校正方法,這種回溯方法有諸多優勢:
- 新的回溯方法不需要對答案有預先的知識。相反,它依賴于有關邏輯錯誤的信息(比如來自訓練獎勵模型的信息),這可以使用獎勵模型一步步地確定。邏輯錯誤可能出現在 correct_ans 軌跡中,也可能不出現在 incorrect_ans 軌跡中。
- 回溯方法不依賴于任何特定的 prompt 文本或措辭,從而可減少相關的偏好。
- 相比于需要重新生成整個軌跡的方法,回溯方法可以通過復用已知邏輯正確的步驟來降低計算成本。
- 回溯方法可直接提升中間步驟的質量,這可能對需要正確步驟的場景來說很有用(比如生成數學問題的解),同時還能提升可解釋性。
研究者基于 BIG-Bench Mistake 數據集實驗了回溯方法能否幫助 LLM 校正邏輯錯誤。結果見表 6。

?accuracy? 是指在原始答案是 correct_ans 時,在軌跡集合上的 accuracy_ans 之差。
?accuracy? 則是對于 incorrect_ans 軌跡的結果。
這些分數結果表明:校正 incorrect_ans 軌跡的收益大于改變原本正確的答案所造成的損失。此外,盡管隨機基準也獲得了提升,但它們的提升顯著小于使用真正錯誤位置時的提升。注意,在隨機基準中,涉及步驟更少的任務更可能獲得性能提升,因為這樣更可能找到真正錯誤的位置。
為了探索在沒有好的標簽時,需要哪種準確度等級的獎勵模型,他們實驗了通過模擬的獎勵模型使用回溯;這種模擬的獎勵模型的設計目標是產生不同準確度等級的標簽。他們使用 accuracy_RM 表示模擬獎勵模型在指定錯誤位置的準確度。
當給定獎勵模型的 accuracy_RM 為 X% 時,便在 X% 的時間使用來自 BIG-Bench Mistake 的錯誤位置。對于剩余的 (100 ? X)%,就隨機采樣一個錯誤位置。為了模擬典型分類器的行為,會按照與數據集分布相匹配的方式來采樣錯誤位置。研究者也想辦法確保了采樣的錯誤位置與正確位置不匹配。結果見圖 2。
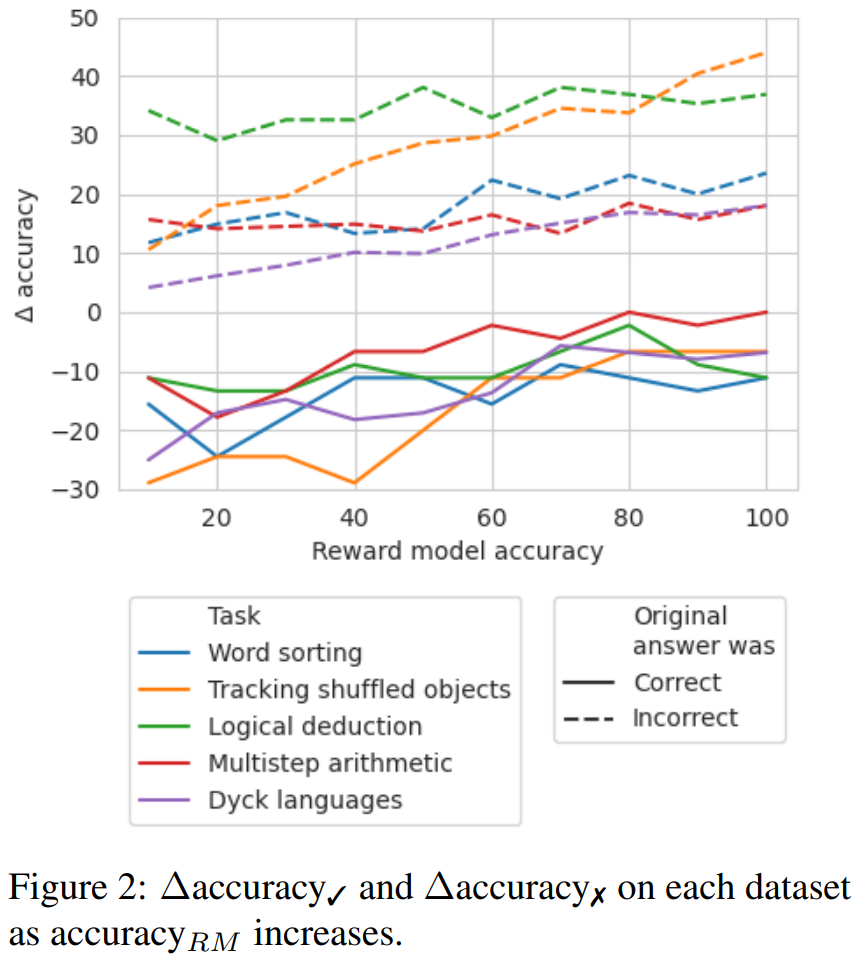
可以看到 ?accuracy? 的損失在 65% 時開始趨于穩定。事實上,對于大多數任務,在 accuracy_RM 大約為 60-70% 時,?accuracy? 就已經大于 ?accuracy? 了。這表明盡管更高的準確度能得到更好的結果,但即便沒有黃金標準的錯誤位置標簽,回溯也依然有效。