













如何使用LangChain、RStudio和足夠的Python生成人工智能
譯文譯者 | 李睿
審校 | 重樓
LangChain是當(dāng)今最熱門(mén)的開(kāi)發(fā)平臺(tái)之一,用于創(chuàng)建使用生成式人工智能的應(yīng)用程序,但它只適用于Python和JavaScript。對(duì)于想要使用LangChain的R程序員,該怎么辦?
幸運(yùn)的是,可以使用非常基本的Python代碼在LangChain中做很多有用的事情。而且,多虧有了reticulate R包,R和RStudio用戶可以在他們熟悉的環(huán)境中編寫(xiě)和運(yùn)行Python,包括在Python和R之間來(lái)回傳遞對(duì)象和數(shù)據(jù)。
在這個(gè)LangChain教程中,將展示如何使用Python和R來(lái)訪問(wèn)LangChain和OpenAI API。這將允許使用大型語(yǔ)言模型(LLM)來(lái)查詢ggplot2的300頁(yè)P(yáng)DF文檔。第一個(gè)示例查詢:“如何在圖形的x軸上旋轉(zhuǎn)文本?”
以下是介紹這個(gè)過(guò)程的每個(gè)步驟:
(1)如果還沒(méi)有運(yùn)行,需要將系統(tǒng)設(shè)置為運(yùn)行Python和reticulate。
(2)將ggplot2 PDF文檔文件導(dǎo)入為純文本的LangChain對(duì)象。
(3)將文本分割成可以被大型語(yǔ)言模型讀取的更小的部分,因?yàn)檫@些模型對(duì)一次讀取的數(shù)量有限制。而長(zhǎng)達(dá)300頁(yè)的文本將超出OpenAI公司的限制。
(4)使用LLM為每個(gè)文本塊創(chuàng)建“嵌入”,并將它們?nèi)勘4嬖跀?shù)據(jù)庫(kù)中。嵌入是一串?dāng)?shù)字,表示多維空間中文本的語(yǔ)義。
(5)為用戶的問(wèn)題創(chuàng)建一個(gè)嵌入,然后將問(wèn)題嵌入與文本中的所有現(xiàn)有問(wèn)題進(jìn)行比較。查找并檢索最相關(guān)的文本片段。
(6)只將那些相關(guān)的文本部分輸入到像GPT-3.5這樣的LLM中,并要求它生成答案。
如果用戶要遵循示例并使用OpenAI API,則需要一個(gè)API密鑰。可以在platform.openai.com注冊(cè)。如果愿意使用另一個(gè)模型,LangChain有組件可以為許多LLM構(gòu)建鏈,而不僅僅是OpenAI公司的組件,因此用戶不會(huì)被某個(gè)LLM提供商鎖定。
LangChain擁有可以輕松處理這些步驟的組件,特別是如果企業(yè)對(duì)其默認(rèn)值感到滿意的話。這就是為什么它變得如此受歡迎的原因。
以下開(kāi)始逐步實(shí)施:
步驟1:設(shè)置系統(tǒng)在RStudio中運(yùn)行Python
如果用戶已經(jīng)運(yùn)行了Python和reticulate,則可以跳到下一步。否則,確保在系統(tǒng)上有最新版本的Python。有很多方法可以安裝Python,但只需要從python.org網(wǎng)站中下載就可以。然后,按照通常的方式使用install.packages("reticulate")安裝reticulate R包。
如果已經(jīng)安裝了Python,但是reticulate找不到它,可以使用命令use_Python(“/path/to/your/Python”)。
library(reticulate)
virtualenv_create(envname = "langchain_env", packages = c( "langchain", "openai", "pypdf", "bs4", "python-dotenv", "chromadb", "tiktoken")) # Only do this once注意,用戶可以隨意命名其環(huán)境。如果需要在創(chuàng)建環(huán)境后安裝軟件包,使用py_install(),如下所示:
py_install(packages = c( "langchain", "openai", "pypdf", "bs4", "python-dotenv", "chromadb", "tiktoken"), envname = "langchain_env")與在R中一樣,用戶應(yīng)該只需要安裝一次軟件包,而不是每次需要使用環(huán)境時(shí)都安裝軟件包。另外,不要忘記激活虛擬環(huán)境:
use_virtualenv("langchain_env")每次回到項(xiàng)目時(shí),在開(kāi)始運(yùn)行Python代碼之前,都要這樣做。
用戶可以測(cè)試其Python環(huán)境是否正在使用
reticulate::py_run_string('
print("Hello, world!")
')如果用戶喜歡的話,可以采用Python變量設(shè)置OpenAI API密鑰。因?yàn)橐呀?jīng)在一個(gè)R環(huán)境變量中有了它,通常使用R來(lái)設(shè)置OpenAI API密鑰。用戶可以使用reticulate的r_to_py()函數(shù)將任何R變量保存為python友好的格式,包括環(huán)境變量:
api_key_for_py <- r_to_py(Sys.getenv("OPENAI_API_KEY"))它接受OPENAI_API_KEY環(huán)境變量,確保它是Python友好的,并將其存儲(chǔ)在一個(gè)新變量中:api_key_for_py(同樣,可以采用任何名稱)。
最后,準(zhǔn)備好編寫(xiě)代碼!
步驟2:下載并導(dǎo)入PDF文件
將在主項(xiàng)目目錄下創(chuàng)建一個(gè)新的docs子目錄,并使用R在那里下載文件。
# Create the directory if it doesn't exist
if(!(dir.exists("docs"))) {
dir.create("docs")
}
# Download the file
download.file("https://cran.r-project.org/web/packages/ggplot2/ggplot2.pdf", destfile = "docs/ggplot2.pdf", mode = "wb")接下來(lái)是Python代碼,將該文件導(dǎo)入為包含內(nèi)容和元數(shù)據(jù)的LangChain文檔對(duì)象。將為此創(chuàng)建一個(gè)名為prep_docs.py的新Python腳本文件。可以像上面那樣使用py_run_string()函數(shù)在R腳本中繼續(xù)運(yùn)行Python代碼。然而,如果用戶正在處理一個(gè)更大的任務(wù),那么就不太理想,因?yàn)閷?huì)在諸如代碼完成之類(lèi)的事項(xiàng)上面臨失敗。
Python新手的關(guān)鍵點(diǎn):不要將腳本文件的名稱與將要加載的Python模塊的名稱相同!換句話說(shuō),雖然該文件不必命名為prep_docs.py,但如果要導(dǎo)入langchain包,就不要將其命名為langchain.py !它們會(huì)發(fā)生沖突。這在R中并不是問(wèn)題。
以下是新的prep_docs.py文件的第一部分:
If running from RStudio, remember to first run in R:
# library(reticulate)
# use_virtualenv("the_virtual_environment_you_set_up")
# api_key_py <- r_to_py(Sys.getenv("OPENAI_API_KEY"))
from langchain.document_loaders import PyPDFLoader
my_loader = PyPDFLoader('docs/ggplot2.pdf')
# print(type (my_loader))
all_pages = my_loader.load()
# print(type(all_pages))
print( len(all_pages) )這段代碼首先導(dǎo)入PDF文檔加載器PyPDFLoader。接下來(lái),它創(chuàng)建PDF加載器類(lèi)的一個(gè)實(shí)例。然后,它運(yùn)行加載器及其load方法,將結(jié)果存儲(chǔ)在一個(gè)名為all_pages的變量中。該對(duì)象是一個(gè)Python列表。
在這里包含了一些注釋行,如果想看到它們,它們將打印對(duì)象類(lèi)型。最后一行打印列表的長(zhǎng)度,在本例中是304。
可以點(diǎn)擊RStudio中的source按鈕來(lái)運(yùn)行一個(gè)完整的Python腳本。或者,突出顯示一些代碼行并只運(yùn)行它們,就像使用R腳本一樣。Python代碼在運(yùn)行時(shí)看起來(lái)與R代碼略有不同,因?yàn)樗赗控制臺(tái)中打開(kāi)一個(gè)Python交互式REPL會(huì)話。用戶將被指示輸入exit或quit(沒(méi)有括號(hào))以退出并在完成后返回常規(guī)R控制臺(tái)。
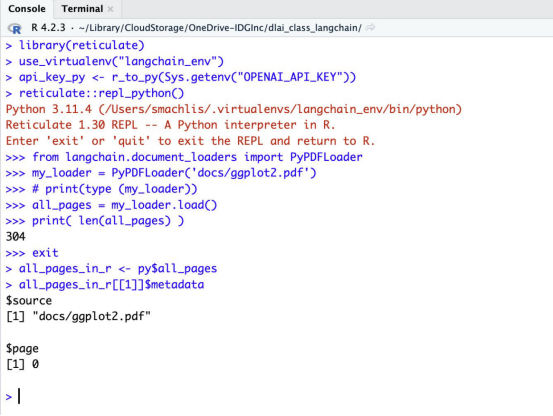
用戶可以使用reticulate的py對(duì)象在R中檢查all_pages Python對(duì)象。下面的R代碼將Python all_pages對(duì)象存儲(chǔ)到一個(gè)名為all_pages_in_r的R變量中(用戶可以隨意調(diào)用它)。然后,可以像處理任何其他R對(duì)象一樣處理該對(duì)象。在本例中,它是一個(gè)列表。
all_pages_in_r <- py$all_pages
# Examples:
all_pages_in_r[[1]]$metadata # See metadata in the first item
nchar(all_pages_in_r[[100]]$page_content) # Count number of characters in the 100th itemLangChain集成
如果用戶還沒(méi)有最喜歡的將PDF轉(zhuǎn)換為可讀文本的方法,那么LangChain的PyPDFLoader可以方便地用于其他非人工智能項(xiàng)目。而且,LangChain還有100多種其他文件加載器,包括PowerPoint、Word、網(wǎng)頁(yè)、YouTube、epub、Evernote和Notion等格式。可以在LangChain集成中心中看到一些文件格式和集成文檔加載器。
步驟3:將文檔拆分為多個(gè)部分
LangChain有幾個(gè)轉(zhuǎn)換器可以將文檔分解成塊,包括按字符、標(biāo)記和標(biāo)記頭進(jìn)行拆分。一個(gè)推薦的默認(rèn)值是RecursiveCharacterTextSplitter,它將“遞歸地嘗試按不同的字符進(jìn)行拆分,以找到一個(gè)有效的字符”。另一個(gè)流行的選項(xiàng)是CharacterTextSplitter,它的設(shè)計(jì)目的是讓用戶設(shè)置其參數(shù)。
用戶可以設(shè)置該拆分器的最大文本塊大小,是按字符計(jì)數(shù)還是按LLM令牌計(jì)數(shù)(令牌通常是1到4個(gè)字符),以及文本塊應(yīng)該重疊多少。在開(kāi)始使用LangChain之前,從未考慮過(guò)文本塊重疊的必要性,但它是有意義的,除非用戶可以通過(guò)邏輯塊(如用標(biāo)題分隔的章節(jié)或節(jié))來(lái)分隔。否則,文本可能會(huì)在句子中間被拆分,一個(gè)重要的信息可能會(huì)被分成兩個(gè)部分,其中任何一個(gè)都沒(méi)有明確的完整含義。
用戶還可以選擇希望拆分器在分割文本時(shí)優(yōu)先考慮哪些分隔符。CharacterTextSplitter的默認(rèn)值是首先拆分為兩個(gè)新行(\n\n),然后再拆分一個(gè)新行、一個(gè)空格,最后完全不使用分隔符。
下面的代碼通過(guò)使用Python內(nèi)部的reticulate的R對(duì)象,從R api_key_for_py變量導(dǎo)入OpenAI API密鑰。它還加載openai Python包和LangChain的遞歸字符分割器,創(chuàng)建一個(gè)RecursiveCharacterTextSplitter類(lèi)的實(shí)例,并在all_pages塊上運(yùn)行該實(shí)例的split_documents()方法。
import openai
openai.api_key = r.api_key_for_py
from langchain.text_splitter import RecursiveCharacterTextSplitter
my_doc_splitter_recursive = RecursiveCharacterTextSplitter()
my_split_docs = my_doc_splitter_recursive.split_documents(all_pages)同樣,用戶可以用R代碼將這些結(jié)果發(fā)送給R,例如:
My_split_docs <- py$ My_split_docs是否想知道塊中的最大字符數(shù)是多少?可以用R中的一個(gè)自定義函數(shù)來(lái)檢查這個(gè)列表:
get_characters <- function(the_chunk) {
x <- nchar(the_chunk$page_content)
return(x)
}
purrr::map_int(my_split_docs, get_characters) |>
max()這將生成3,985個(gè)字符,因此看起來(lái)默認(rèn)的塊最大值是4,000個(gè)字符。
如果想要更小的文本塊,首先嘗試CharacterTextSplitter并人工地將chunk_size設(shè)置為小于4,000,例如
chunk_size = 1000
chunk_overlap = 150
from langchain.text_splitter import CharacterTextSplitter
c_splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap, separator=" ")
c_split_docs = c_splitter.split_documents(all_pages)
print(len(c_split_docs)) # To see in Python how many chunks there are now可以在R和Python中檢查結(jié)果:
c_split_docs <- py$c_split_docs
length(c_split_docs)該代碼生成695個(gè)塊,最大為1000。
成本是多少?
在進(jìn)一步討論之前,如果想知道為所有這些塊生成嵌入是否會(huì)非常昂貴。將從默認(rèn)的306項(xiàng)遞歸拆分開(kāi)始。可以計(jì)算R對(duì)象上這些塊中的字符總數(shù):
purrr::map_int(my_split_docs, get_characters) |>
sum()答案是513506。保守地估計(jì)每個(gè)令牌有兩個(gè)字符,其結(jié)果大約是20萬(wàn)個(gè)。
如果想更準(zhǔn)確,TheOpenAIR R包有一個(gè)count_tokens()函數(shù)(確保安裝該函數(shù)和purrr以使用下面的R代碼):
purrr::map_int(my_split_docs, ~ TheOpenAIR::count_tokens(.x$page_content)) |>
sum ()該代碼顯示了126,343個(gè)令牌。
那要花費(fèi)多少成本?OpenAI用于生成嵌入的模型是ada-2。現(xiàn)在ada-2的1000個(gè)令牌價(jià)格為0.0001美元,126,000代幣的價(jià)格約為1.3美分。這些費(fèi)用在預(yù)算之內(nèi)。
步驟4:生成嵌入
LangChain有預(yù)制的組件,可以從文本塊創(chuàng)建嵌入并存儲(chǔ)它們。對(duì)于存儲(chǔ),將使用LangChain中最簡(jiǎn)單的選項(xiàng)之一:Chroma,這是一個(gè)可以在本地使用的開(kāi)源嵌入數(shù)據(jù)庫(kù)。
首先,將用R代碼為docs目錄創(chuàng)建一個(gè)子目錄,因?yàn)榻ㄗh在Chroma目錄中除了數(shù)據(jù)庫(kù)之外什么都不要。這是R代碼:
if(!dir.exists("docs/chroma_db")) {
dir.create("docs/chromaba_db")
}下面是使用LangChain的OpenAIEmbeddings生成嵌入的一些Python代碼。這是目前默認(rèn)為OpenAI的ada-2模型,因此不需要指定它。LangChain通過(guò)其嵌入類(lèi)支持許多其他LLM,包括Hugging Face Hub、Cohere、Llama cpp和Spacy。
下面的Python代碼稍微修改了一下DeepLearning.AI的LangChain與其數(shù)據(jù)聊天在線教程。
from langchain.embeddings.openai import OpenAIEmbeddings
embed_object = OpenAIEmbeddings()
from langchain.vectorstores import Chroma
chroma_store_directory = "docs/chroma_db"
vectordb = Chroma.from_documents(
documents=my_split_docs,
embedding=embed_object,
persist_directory=chroma_store_directory
)
# Check how many embeddings were created
print(vectordb._collection.count())注意_collection.count()中的下劃線!
可以看到有306個(gè)嵌入,與ggplot2文本塊的數(shù)量相同。
Python新手的另一個(gè)注意事項(xiàng):縮進(jìn)在Python中很重要。確保非縮進(jìn)行之前沒(méi)有空格,并且縮進(jìn)行都使用相同數(shù)量的縮進(jìn)空格。
在這個(gè)系統(tǒng)上,這段代碼似乎將數(shù)據(jù)保存到了磁盤(pán)上。但是,教程指出用戶應(yīng)該運(yùn)行以下Python代碼來(lái)保存嵌入以供以后使用。這樣做的原因是不想在文檔更改之前重新生成嵌入。
vectordb.persist()現(xiàn)在,已經(jīng)完成了為查詢準(zhǔn)備文檔的工作。將創(chuàng)建qanda.py這個(gè)新文件,來(lái)使用創(chuàng)建的矢量嵌入。
步驟5:嵌入用戶查詢和查找文檔塊
現(xiàn)在是時(shí)候提出一個(gè)問(wèn)題,為該問(wèn)題生成嵌入,并根據(jù)塊的嵌入檢索與該問(wèn)題最相關(guān)的文檔。
由于vectordb對(duì)象的內(nèi)置方法,LangChain提供了在一行代碼中完成所有這些工作的幾種方法。它的similarity_search()方法直接計(jì)算向量相似度,并返回最相似的文本塊。
不過(guò),還有其他幾種方法可以做到這一點(diǎn),包括max_marginal_relevance e_search()。這背后的想法是,不一定想要三個(gè)幾乎相同的文本塊。如果文本中有一點(diǎn)多樣性,以獲得額外的有用信息,也許最終會(huì)得到一個(gè)更豐富的回答。因此,max_marginal_relevance e_search()檢索的相關(guān)文本比實(shí)際計(jì)劃傳遞給LLM以獲取答案的文本多一些(用戶決定多出多少)。然后,結(jié)合一定程度的多樣性,它選擇最后的文本片段。
用戶可以指定希望similarity_search()返回多少相關(guān)文本塊及其k參數(shù)。對(duì)于max_marginal_relevance(),用戶指定最初應(yīng)該使用fetch_k檢索多少塊,以及希望LLM查找其使用k的答案的最終文本片段。
如果文檔沒(méi)有更改,不想運(yùn)行文檔準(zhǔn)備文件,將首先在新的qanda.py文件中加載必要的包和環(huán)境變量(即OpenAI API密鑰),就像在使用doc_prepare .py之前所做的那樣。然后,將加載chromadb矢量數(shù)據(jù)庫(kù):
# If running from RStudio, remember to first run in R:
# library(reticulate)
# use_virtualenv("the_virtual_environment_you_set_up")
# api_key_py <- r_to_py(Sys.getenv("OPENAI_API_KEY"))
import openai
openai.api_key = r.api_key_for_py
from langchain.embeddings.openai import OpenAIEmbeddings
embed_object = OpenAIEmbeddings()
from langchain.vectorstores import Chroma
chroma_store_directory = "docs/chroma_db"
vectordb = Chroma(persist_directory=chroma_store_directory,
embedding_functinotallow=embed_object)接下來(lái),將硬編碼一個(gè)問(wèn)題并檢索相關(guān)文檔。需要注意,可以用一行代碼檢索文檔:
my_question = "How do you rotate text on the x-axis of a graph?"
# For straightforward similarity searching
sim_docs = vectordb.similarity_search(my_question)
# For maximum marginal relevance search retrieving 5 possible chunks and choosing 3 finalists:
mm_docs = vectordb.max_marginal_relevance_search(my_question, k = 3, fetch_k = 5)如果想查看檢索到的文檔片段,可以在Python中打印它們,如下所示:
for doc in mm_docs:
print(doc.page_content)
for doc in sim_docs:
print(doc.page_content)注意縮進(jìn)是for循環(huán)的一部分。
還可以使用以下命令查看它們的元數(shù)據(jù):
for doc in mm_docs:
print(doc.metadata)
for docs in sim_docs:
print(docs.metadata)與其他對(duì)象一樣,也可以在R中查看這些對(duì)象:
mm_relevant <- py$mm_docs
sim_relevant <- py$sim_docs不確定為什么當(dāng)請(qǐng)求三個(gè)文檔時(shí),模型有時(shí)會(huì)返回四個(gè)文檔,但這應(yīng)該不是問(wèn)題,除非LLM在遍歷文本以生成響應(yīng)時(shí)有太多的令牌。
步驟6:生成答案
現(xiàn)在是時(shí)候讓GPT-3.5這樣的LLM根據(jù)相關(guān)文檔生成對(duì)用戶問(wèn)題的書(shū)面回復(fù)了。可以使用LangChain的RetrievalQA功能來(lái)實(shí)現(xiàn)這一點(diǎn)。
建議首先嘗試LangChain的默認(rèn)模板,這很容易實(shí)現(xiàn),通常適用于原型制作或用戶自己使用:
# Set up the LLM you want to use, in this example OpenAI's gpt-3.5-turbo
from langchain.chat_models import ChatOpenAI
the_llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Create a chain using the RetrievalQA component
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(the_llm,retriever=vectordb.as_retriever())
# Run the chain on the question, and print the result
print(qa_chain.run(my_question))LLM給出了以下回復(fù):
To rotate text on the x-axis of a graph, you can use the `theme()` function in ggplot2. Specifically, you can use the `axis.text.x` argument to modify the appearance of the x-axis text. Here is an example:
```R
library(ggplot2)
# Create a basic scatter plot
p <- ggplot(mtcars, aes(x = mpg, y = wt)) +
geom_point()
# Rotate x-axis text by 45 degrees
p + theme(axis.text.x = element_text(angle = 45, hjust = 1))
```
In this example, the `angle` argument is set to 45, which rotates the x-axis text by 45 degrees. The `hjust` argument is set to 1, which aligns the text to the right. You can adjust the angle and alignment values to achieve the desired rotation and alignment of the x-axis text.看起來(lái)是正確的!
現(xiàn)在鏈已經(jīng)設(shè)置好了,可以用一個(gè)R腳本用一個(gè)命令在其他問(wèn)題上運(yùn)行它:
py_run_string('
print(qa_chain.run("How can I make a bar chart where the bars are steel blue?"))
')以下是它們的回應(yīng):
```R
library(ggplot2)
# Create a bar chart with steel blue bars
p <- ggplot(mtcars, aes(factor(cyl)))
p + geom_bar(fill = "steelblue")
```
In this example, we use the `fill` aesthetic to specify the color of the bars as "steelblue". You can adjust the color to your preference by changing the color name or using a hexadecimal color code.這是一個(gè)比在ChatGPT 3.5中有時(shí)收到的相同問(wèn)題可獲得更好的答案。有時(shí)它發(fā)回的代碼實(shí)際上并不起作用。
用戶可能還想確認(rèn)答案不是從一般的ChatGPT知識(shí)庫(kù)中提取的,而是真正來(lái)自其上傳的文檔。為了找到答案,可以問(wèn)一些與ggplot2完全無(wú)關(guān)的問(wèn)題,這些問(wèn)題不會(huì)出現(xiàn)在文檔中:
py_run_string('
print(qa_chain.run("What is the capital of Australia?"))
')用戶應(yīng)該這樣回復(fù):
I don't know.如果正在創(chuàng)建一個(gè)應(yīng)用程序以供更廣泛的使用,那么“我不知道”可能有點(diǎn)簡(jiǎn)潔。如果用戶想定制默認(rèn)模板,可以查看LangChain文檔。如果用戶正在為不止自己或一個(gè)小團(tuán)隊(duì)創(chuàng)建應(yīng)用程序,那么個(gè)性化響應(yīng)是有意義的。
模板調(diào)整是LangChain可能感覺(jué)過(guò)于復(fù)雜的一個(gè)領(lǐng)域,它可能需要多行代碼來(lái)實(shí)現(xiàn)對(duì)模板的小更改。然而,使用任何固執(zhí)己見(jiàn)的框架都是有風(fēng)險(xiǎn)的,這取決于每個(gè)開(kāi)發(fā)人員來(lái)決定項(xiàng)目的總體收益是否值得這樣的成本。雖然它非常受歡迎,但并不是每個(gè)人都是LangChain的忠實(shí)用戶。
還可以用LangChain做什么?
到目前為止,對(duì)應(yīng)用程序最簡(jiǎn)單的添加是包含更多文檔。LangChain有一個(gè)DirectoryLoader來(lái)簡(jiǎn)化這個(gè)過(guò)程。如果用戶正在跨多個(gè)文檔進(jìn)行搜索,可能希望知道哪些文檔用于生成響應(yīng)。可以給RetrievalQA添加return_source_documents=True參數(shù),如下所示:
qa_chain = RetrievalQA.from_chain_type(the_llm,retriever=vectordb.as_retriever(), return_source_documents=True)
my_result = qa_chain({"query": my_question})
print(my_result['result'])該代碼最初只對(duì)單個(gè)用戶在本地運(yùn)行有用,但它可以成為使用Streamlit或Shiny for Python等框架的交互式Web應(yīng)用程序的邏輯基礎(chǔ)。或者,將Python和R結(jié)合起來(lái),將LLM的最終答案發(fā)送回R,并使用Shiny R Web框架創(chuàng)建一個(gè)應(yīng)用程序(盡管發(fā)現(xiàn)同時(shí)使用Python和R部署Shiny應(yīng)用程序有點(diǎn)復(fù)雜)。
還要注意的是,這個(gè)應(yīng)用程序在技術(shù)上并不是一個(gè)“聊天機(jī)器人”,因?yàn)樗粫?huì)記住用戶之前的問(wèn)題。所以,不能有一個(gè)“對(duì)話”,例如“如何改變圖表標(biāo)題文字的大小?”,然后是“圖例呢?”用戶需要把每個(gè)新單詞拼出來(lái)。
但是,可以向應(yīng)用程序添加內(nèi)存,使用LangChain的ConversationBufferMemory將其轉(zhuǎn)換為聊天機(jī)器人。
其他資源
要了解更多關(guān)于LangChain的信息,除了LangChain文檔之外,還有一個(gè)LangChain Discord服務(wù)器,其中有一個(gè)人工智能聊天機(jī)器人kapa。它可以查詢文檔。
原文標(biāo)題:Generative AI with LangChain, RStudio, and just enough Python,作者:Sharon Machlis




























