













世界模型和DriveGPT這類大模型到底能給自動駕駛帶來什么?
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
大模型今年爆火,很多領域上的應用如雨后春筍般涌現,很多優秀的工作出現,主要集中在數據生成和場景分析表述兩部分,重點解決自動駕駛的長尾分布問題和場景識別。今天自動駕駛之心帶大家梳理下自動駕駛行業上的大模型應用主要方案。所有論文可以在底部獲取下載鏈接!
1、ADAPT
ADAPT: Action-aware Driving Caption Transformer(ICRA2023)
ADAPT提出了一種基于端到端transformer的架構ADAPT(動作感知Driving cAPtion transformer),它為自動駕駛車輛的控制和動作提供了用戶友好的自然語言敘述和推理。ADAPT通過共享視頻表示聯合訓練駕駛字幕任務和車輛控制預測任務。
整體架構:

ADAPT框架概述,(a) 輸入是車輛的前視圖視頻,輸出是預測車輛的控制信號以及當前動作的敘述和推理。首先對視頻中的T幀進行密集和均勻的采樣,將其發送到可學習的視頻swin transformer,并標記為視頻標記。不同的預測頭生成最終的運動結果和文本結果。(b) (c)分別顯示預測頭~

2、BEVGPT
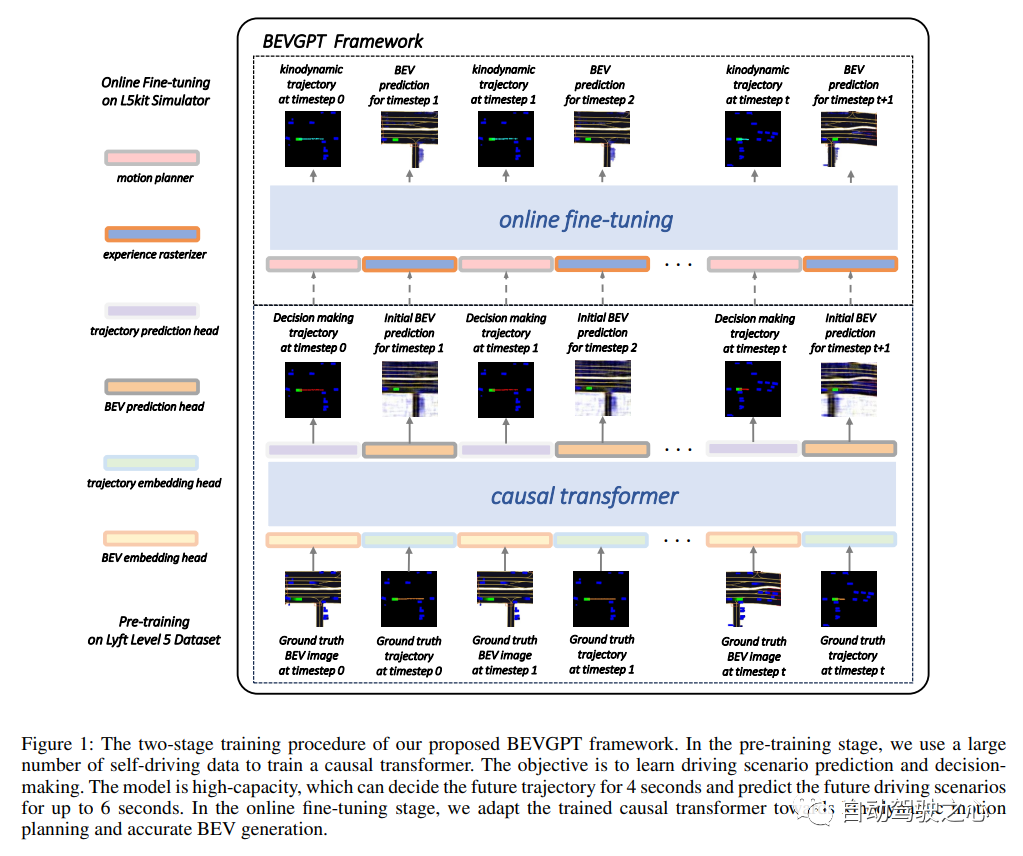
Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning.(AAAI2024)
BEVGPT 是第一個生成式, 集預測、決策、運動規劃于一體的自監督 pre-trained的大模型。輸入BEV images, 輸出自車軌跡, 并且能夠輸出對駕駛場景的預測, 該方案訓練時需要高精地圖。之所以叫GPT,一方面是因為利用了GPT式的自回歸訓練方法, 這里自回歸的輸入是歷史的軌跡及BEV, target 是下一個BEV和軌跡。另一方面,能夠做到生成, 即給定初始楨的BEV, 算法能夠自己生成接下來的多幀BEV場景。該方法并不是一個從傳感器輸入的端到端方法, 可以看成是基于感知的結果,將后面的模塊用一個模型給模型化了, 在實際中也有重要的應用價值. 比如能夠基于很多駕駛回傳數據的感知結果和軌跡真值來訓練駕駛專家模型。
整體結構:
3、DriveGPT4
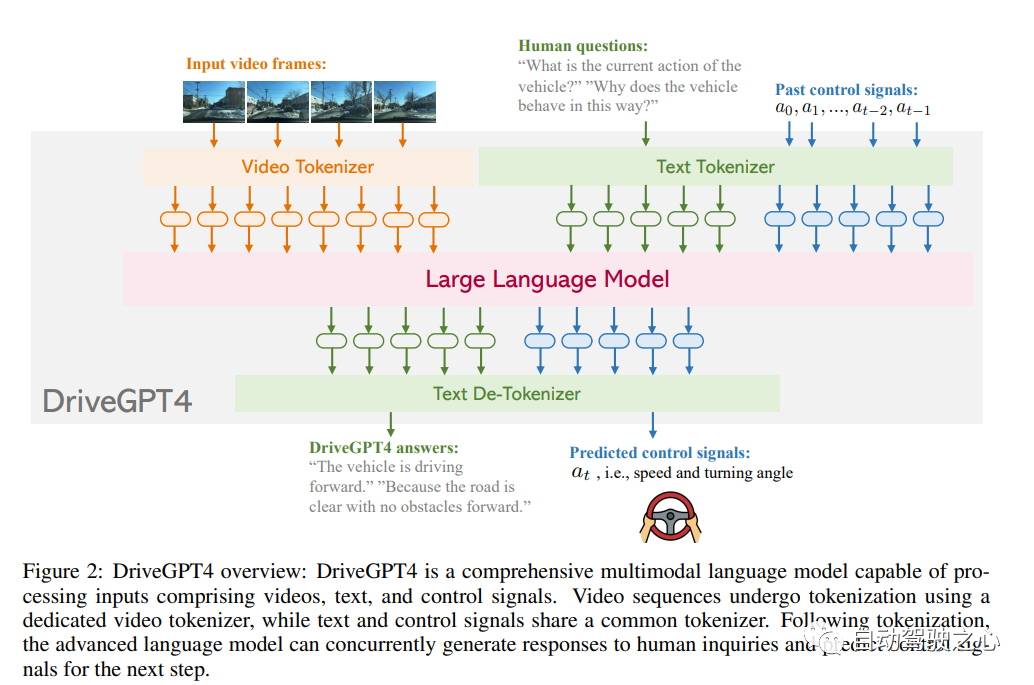
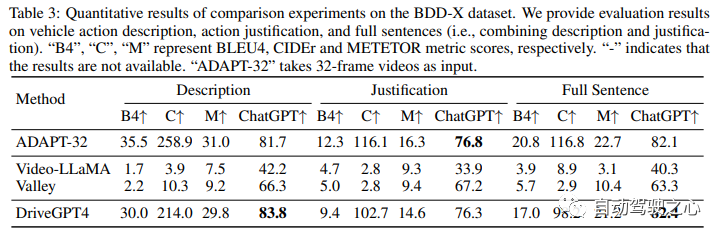
DriveGPT4 Interpretable End-to-end Autonomous Driving via Large Language Model
在過去的十年里,自動駕駛在學術界和工業界都得到了快速發展。然而其有限的可解釋性仍然是一個懸而未決的重大問題,嚴重阻礙了自動駕駛的發展進程。以前使用小語言模型的方法由于缺乏靈活性、泛化能力和魯棒性而未能解決這個問題。近兩年隨著ChatGPT的出現,多模態大型語言模型(LLM)因其通過文本處理和推理非文本數據(如圖像和視頻)的能力而受到研究界的極大關注。因此一些工作開始嘗試將自動駕駛和大語言模型結合起來,今天汽車人為大家分享的DriveGPT4就是利用LLM的可解釋實現的端到端自動駕駛系統。DriveGPT4能夠解釋車輛動作并提供相應的推理,以及回答用戶提出的各種問題以增強交互。此外,DriveGPT4以端到端的方式預測車輛的運動控制。這些功能源于專門為無人駕駛設計的定制視覺指令調整數據集。DriveGPT4也是世界首個專注于可解釋的端到端自動駕駛的工作。當與傳統方法和視頻理解LLM一起在多個任務上進行評估時,DriveGPT4表現出SOTA的定性和定量性能。
4、Drive Like a Human
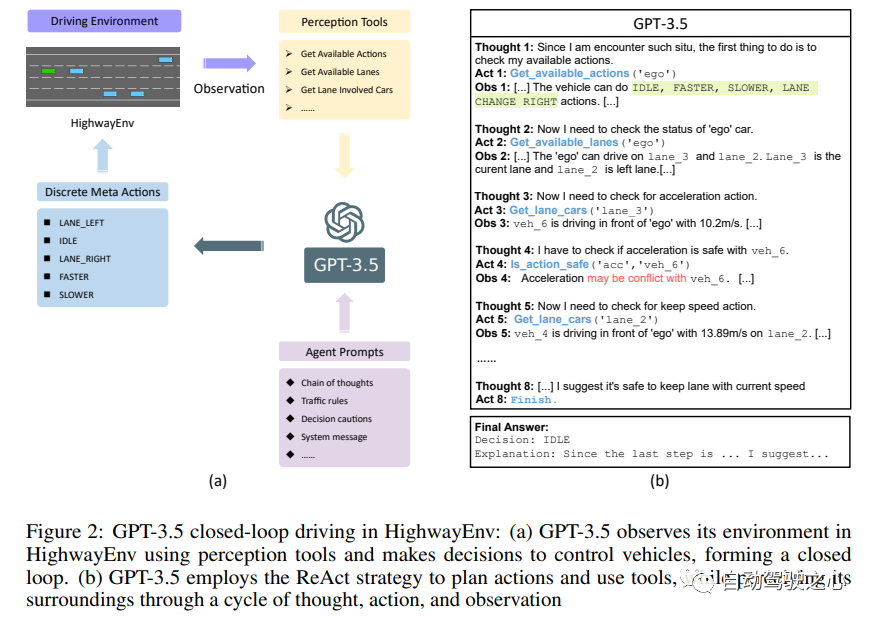
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models.
code:https://github.com/PJLab-ADG/DriveLikeAHuman
作者提出了理想的AD系統應該像人類一樣駕駛,通過持續駕駛積累經驗,并利用常識解決問題。為了實現這一目標,確定了AD系統所需的三種關鍵能力:推理、解釋和記憶。通過構建閉環系統來展示LLM的理解能力和環境交互能力,證明了在駕駛場景中使用LLM的可行性。大量實驗表明,LLM表現出了令人印象深刻的推理和解決長尾案例的能力,為類人自動駕駛的發展提供了寶貴的見解!
5、Driving with LLMs
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving.
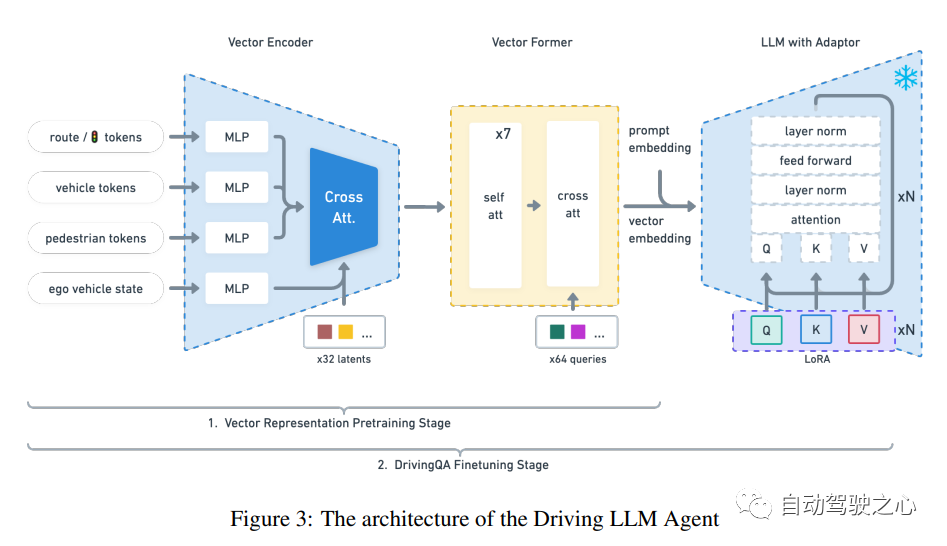
大型語言模型(LLM)在自動駕駛領域顯示出了前景,尤其是在泛化和可解釋性方面。本文引入了一種獨特的目標級多模式LLM架構,該架構將矢量化的數字模態與預先訓練的LLM相結合,以提高對駕駛情況下上下文的理解。本文還提出了一個新的數據集,其中包括來自10k駕駛場景的160k個QA對,與RL代理收集的高質量控制命令和教師LLM(GPT-3.5)生成的問答對配對。設計了一種獨特的預訓練策略,使用矢量字幕語言數據將數字矢量模態與靜態LLM表示對齊。論文還介紹了駕駛QA的評估指標,并展示了LLM駕駛員在解釋駕駛場景、回答問題和決策方面的熟練程度。與傳統的行為克隆相比,突出了基于LLM的驅動動作生成的潛力。我們也提供了基準、數據集和模型以供進一步探索。
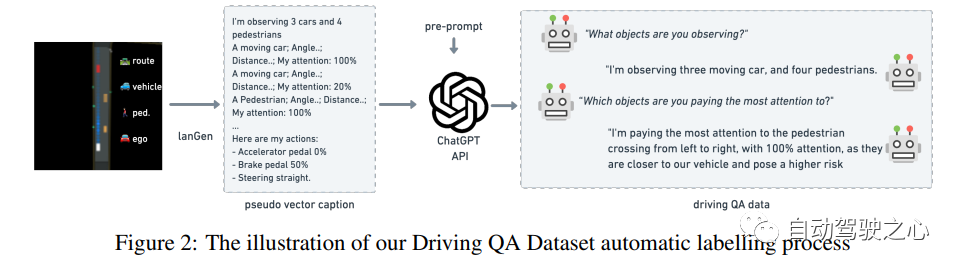
模型結構:
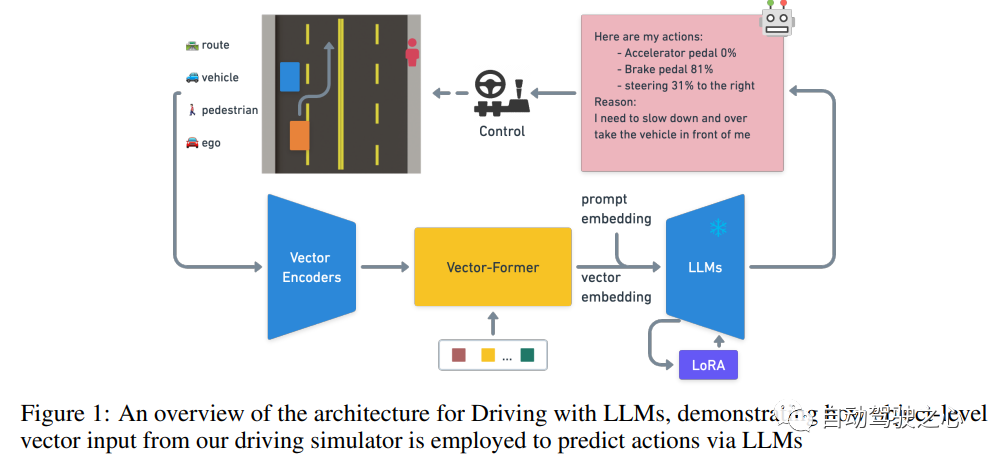
LLM駕駛體系結構概述,演示如何使用來自駕駛模擬器的對象級矢量輸入來通過LLM預測動作!
6、HiLM-D
HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving.
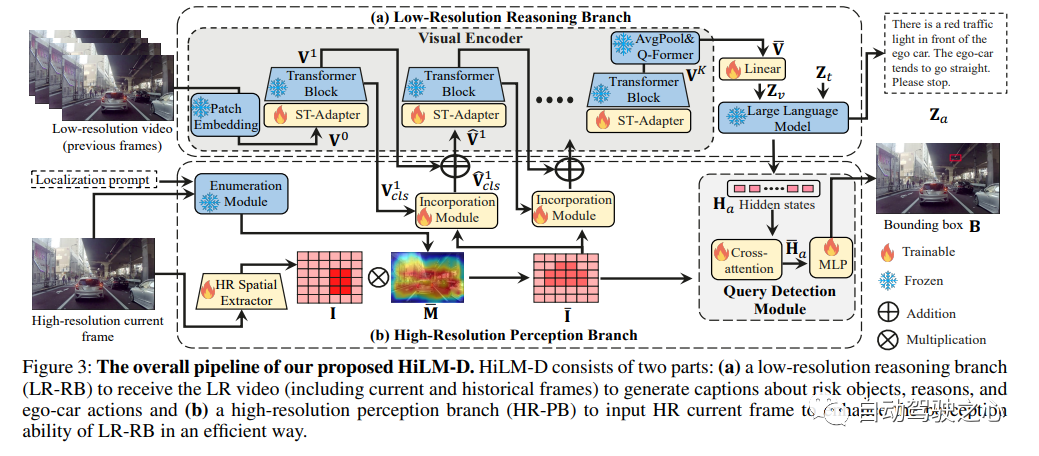
自動駕駛系統通常針對不同的任務使用單獨的模型,從而產生復雜的設計。這是首次利用奇異多模態大語言模型(MLLMs)來整合視頻中的多個自動駕駛任務,即風險目標定位和意圖與建議預測(ROLISP)任務。ROLISP使用自然語言同時識別和解釋風險目標,理解自我-車輛意圖,并提供動作建議,從而消除了特定任務架構的必要性。然而,由于缺乏高分辨率(HR)信息,現有的MLLM在應用于ROLISP時往往會錯過小目標(如交通錐),并過度關注突出目標(如大型卡車)。本文提出了HiLM-D(在用于自動駕駛的MLLMs中實現高分辨率理解),這是一種將人力資源信息整合到用于ROLISP任務的MLLMs中的有效方法。
HiLM-D集成了兩個分支:
(i) 低分辨率推理分支可以是任何MLLMs,處理低分辨率視頻以說明風險目標并辨別自我車輛意圖/建議;
(ii)HiLM-D突出的高分辨率感知分支(HR-PB)攝取HR圖像,通過捕捉視覺特異性HR特征圖并將所有潛在風險優先于僅突出的目標來增強檢測;HR-PB作為一個即插即用模塊,無縫地適應當前的MLLM。在ROLISP基準上的實驗表明,與領先的MLLMs相比,HiLM-D具有顯著的優勢,在BLEU-4中用于字幕的改進為4.8%,在mIoU中用于檢測的改進為17.2%。
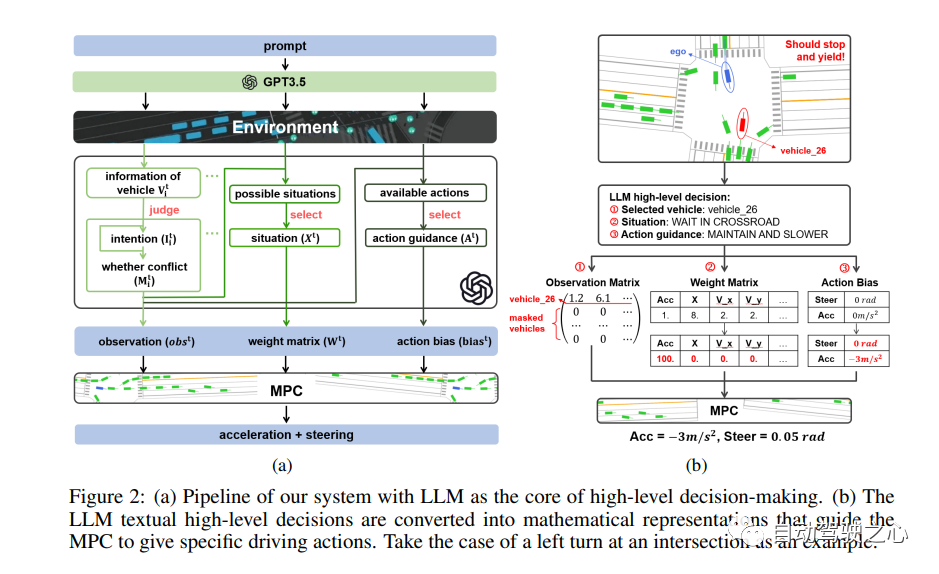
7、LanguageMPC
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving.
這項工作將大型語言模型(LLM)作為需要人類常識理解的復雜AD場景的決策組件。設計了認知途徑,以實現LLM的全面推理,并開發了將LLM決策轉化為可操作駕駛命令的算法。通過這種方法,LLM決策通過引導參數矩陣自適應與低級控制器無縫集成。大量實驗表明,由于LLM的常識性推理能力,提出的方法不僅在單車任務中始終優于基線方法,而且有助于處理復雜的駕駛行為,甚至多車協調。本文在安全性、效率、可推廣性和互操作性方面,為利用LLM作為復雜AD場景的有效決策者邁出了第一步,希望它能成為該領域未來研究的靈感來源。

網絡結構:
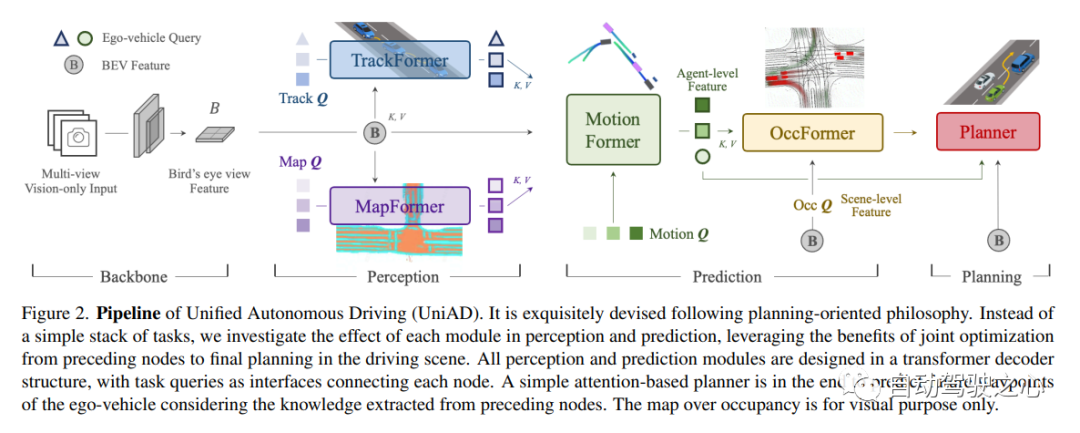
8、Planning-oriented Autonomous Driving
今年CVPR2023的best paper!UniAD將各任務通過token的形式在特征層面,按照感知-預測-決策的流程進行深度融合,使得各項任務彼此支持,實現性能提升。在nuScenes數據集的所有任務上,UniAD都達到SOTA性能,比所有其它端到端的方法都要優越,尤其是預測和規劃效果遠超其它模型。作為業內首個實現感知決策一體化自動駕駛通用大模型,UniAD能更好地協助進行行車規劃,實現「多任務」和「高性能」,確保車輛行駛的可靠和安全。基于此,UniAD具有極大的應用落地潛力和價值。

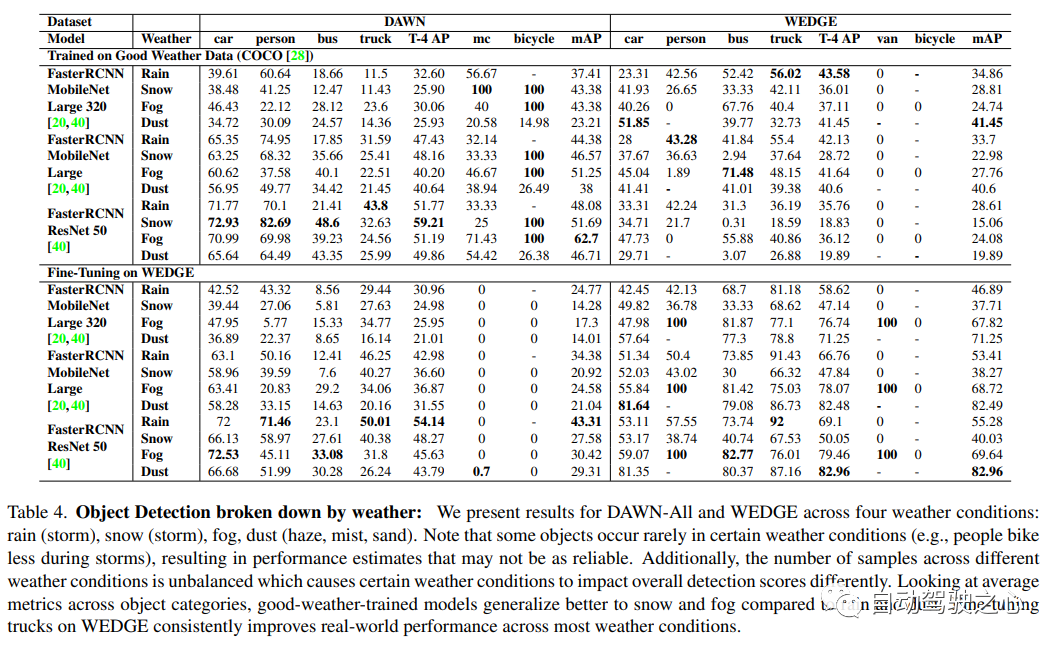
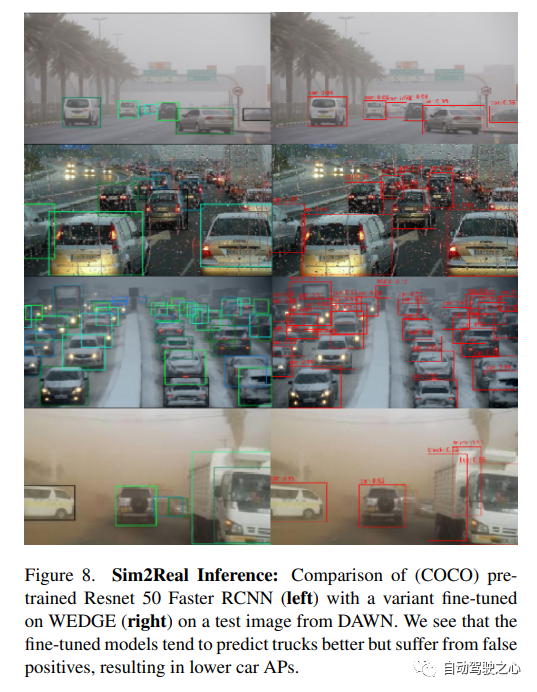
9、WEDGE
WEDGE:A multi-weather autonomous driving dataset built from generative vision-language models.
開放的道路給自主感知帶來了許多挑戰,包括極端天氣。在好天氣數據集上訓練的模型經常無法在這些分布外數據(OOD)設置中進行檢測。為了增強感知中的對抗性魯棒性,本文引入WEDGE(WEather Images by DALL-E GEneration):一個通過提示用視覺語言生成模型生成的合成數據集。WEDGE 由 16 種極端天氣條件下的 3360 張圖像組成,并用 16513 個邊框手動注釋,支持天氣分類和 2D 目標檢測任務的研究。作者從研究的角度分析了WEDGE,驗證了其對于極端天氣自主感知的有效性。作者還建立了分類和檢測的基線性能,測試準確度為 53.87%,mAP 為 45.41。WEDGE 可用于微調檢測器,將真實世界天氣基準(例如 DAWN)的 SOTA 性能提高 4.48 AP,適用于卡車等類別。


原文鏈接:https://mp.weixin.qq.com/s/jJkwrf_-1mjO4yGjbJXb3Q





























