未來之路:大模型技術(shù)在自動駕駛的應(yīng)用與影響
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
本文深入分析了大模型技術(shù)在自動駕駛領(lǐng)域的應(yīng)用和影響,萬字長文,慢慢觀看~
- 文中首先概述了大模型技術(shù)的發(fā)展歷程,自動駕駛模型的迭代路徑,以及大模型在自動駕駛行業(yè)中的作用。
- 接著,詳細介紹了大模型的基本定義、基礎(chǔ)功能和關(guān)鍵技術(shù),特別是Transformer注意力機制和預(yù)訓(xùn)練-微調(diào)范式。
- 文章還介紹了大模型在任務(wù)適配性、模型變革和應(yīng)用前景方面的潛力。
- 在自動駕駛技術(shù)的部分,詳細回顧了從CNN到RNN、GAN,再到BEV和Transformer結(jié)合的技術(shù)迭代路徑,以及占用網(wǎng)絡(luò)模型的應(yīng)用。
- 最后,文章重點討論了大模型如何在自動駕駛的感知、預(yù)測和決策層面提供賦能,突出了其在該領(lǐng)域的重要性和影響力。
一、本文概述
1.1 大模型技術(shù)發(fā)展歷程
大模型泛指具有數(shù)十億甚至上百億參數(shù)的深度學(xué)習模型,而大語言模型是大模型的一個典型分支(以ChatGPT為代表)
Transformer架構(gòu)的提出引入了注意力機制,突破了RNN和CNN處理長序列的固有局限,使語言模型能在大規(guī)模語料上得到豐富的語言知識預(yù)訓(xùn)練:
- 一方面,開啟了大語言模型快速發(fā)展的新時代;
- 另一方面奠定了大模型技術(shù)實現(xiàn)的基礎(chǔ),為其他領(lǐng)域模型通過增大參數(shù)量提升模型效果提供了參考思路。
復(fù)雜性、高維度、多樣性和個性化要求使得大型模型在自動駕駛、量化交易、醫(yī)療診斷和圖像分析、自然語言處理和智能對 話任務(wù)上更易獲得出色的建模能力。
1.2 自動駕駛模型迭代路徑
自動駕駛算法模塊可分為感知、決策和規(guī)劃控制三個環(huán)節(jié)。其中感知模塊為關(guān)鍵的組成部分,經(jīng)歷了多樣化的模型迭代:
CNN(2011-2016)—— RNN+GAN(2016-2018)—— BEV(2018-2020)—— Transformer+BEV(2020至 今)—— 占用網(wǎng)絡(luò)(2022至今)
可以看一下特斯拉智能駕駛迭代歷程:

2020年重構(gòu)自動駕駛算法,引入BEV+Transformer取 代傳統(tǒng)的2D+CNN算法,并采用特征級融合取代后融合,自動標注取代人工標注。
- 2022年算法中引入 時序網(wǎng)絡(luò),并將BEV升級為占用網(wǎng)絡(luò)(Occupancy Network)。
- 2023年8月,端到端AI自動駕駛系統(tǒng)FSD Beta V12首次公開亮相,完全依靠車載攝像頭和神經(jīng)網(wǎng)絡(luò)來識別道路和交通情況,并做出相應(yīng)的決策。
1.3 大模型對自動駕駛行業(yè)的賦能與影響
自動駕駛領(lǐng)域的大模型發(fā)展相對大語言模型滯后,大約始于2019年,吸取了GPT等模型成功經(jīng)驗。
大模型的應(yīng)用加速模型端的成熟,為L3/L4級別的自動駕駛技術(shù)落地提供了更加明確的預(yù)期。
可從成本、技術(shù)、監(jiān)管與安全四個層面對于L3及以上級別自動駕駛落地的展望,其中:
- 成本仍有下降空間
- 技術(shù)的發(fā)展仍將沿著算法和硬件兩條主線并進
- 法規(guī)政策還在逐步完善之中
- 安全性成為自動駕駛汽車實現(xiàn)商業(yè)化落地必不可少的重要因素
各主機廠自2021年開始加速對L2+自動駕駛的布局,且預(yù)計在2024年左右實現(xiàn)L2++(接近L3)或者更高級別的自動駕駛功能的落地,其中政策有望成為主要催化。
二、大模型技術(shù)發(fā)展歷程
2.1 大模型基本定義與基礎(chǔ)功能
大模型基本定義:由大語言模型到泛在的大模型大模型主要指具有數(shù)十億甚至上百億參數(shù)的深度學(xué)習模型,比較有代表性的是大型語言模型( Large Language Models,比如最近大熱的ChatGPT)。
大型語言模型是一種深度學(xué)習算法,可以使用非常大的數(shù)據(jù)集來識別、總結(jié)、翻譯、預(yù)測和生成內(nèi)容。
大語言模型在很大程度上代表了一類稱為Transformer網(wǎng)絡(luò)的深度學(xué)習架構(gòu)。Transformer模型是一個神經(jīng)網(wǎng)絡(luò),通過跟蹤序列數(shù)據(jù)中的關(guān)系(像這句話中的詞語)來學(xué)習上下文和含義。
Transformer架構(gòu)的提出,開啟了大語言模型快速發(fā)展的新時代:
- 谷歌的BERT首先證明了預(yù)訓(xùn)練模型的強大潛力
- OpenAI的GPT系列及Anthropic的Claude等繼續(xù)探索語言模型技術(shù)的邊界。越來越大規(guī)模的模型不斷刷新自然語言處理的技術(shù)狀態(tài)。這些模型擁有數(shù)百億或上千億參數(shù),可以捕捉語言的復(fù)雜語義關(guān)系,并進行人類級別的語言交互。
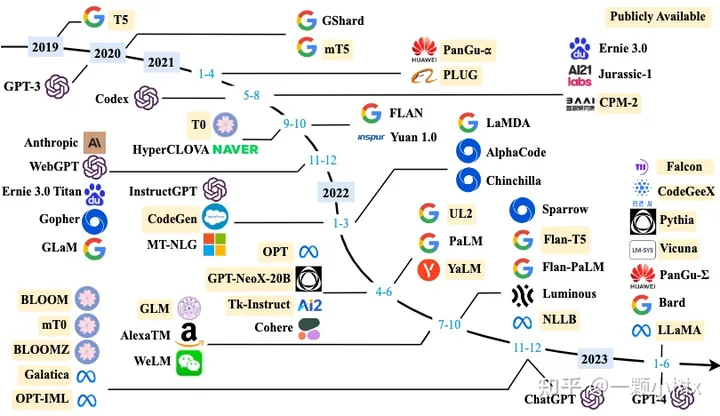
下圖是大模型的發(fā)展歷程:
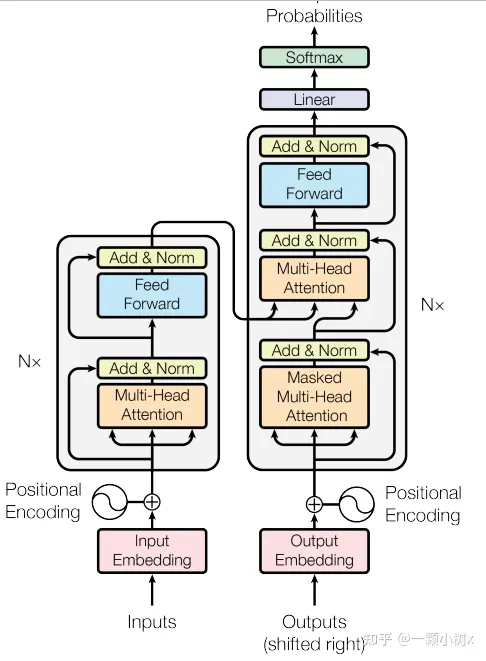
2.2 大模型的基礎(chǔ)——Transformer注意力機制
注意力機制:Transformer的核心創(chuàng)新
創(chuàng)新點1:Transformer模型最大的創(chuàng)新在于提出了注意力機制,這一機制極大地改進了模型學(xué)習遠距離依賴關(guān)系的能力,突破了傳統(tǒng)RNN和CNN在處理長序列數(shù)據(jù)時的局限。
創(chuàng)新點2:在Transformer出現(xiàn)之前,自然語言處理一般使用RNN或CNN來建模語義信息。但RNN和CNN均面臨學(xué)習遠距離依賴關(guān)系的困難:
- RNN的序列處理結(jié)構(gòu)使較早時刻的信息到后期會衰減;
- 而CNN的局部感知也限制了捕捉全局語義信息。
- 這使RNN和CNN在處理長序列時,往往難以充分學(xué)習詞語之間的遠距離依賴。
創(chuàng)新點3:Transformer注意力機制突破了RNN和CNN處理長序列的固有局限,使語言模型能在大規(guī)模語料上得到豐富的語言知識預(yù)訓(xùn)練。該模塊化、可擴展的模型結(jié)構(gòu)也便于通過增加模塊數(shù)量來擴大模型規(guī)模和表達能力,為實現(xiàn)超大參數(shù)量提供了可行路徑。
Transformer解決了傳統(tǒng)模型的長序列處理難題,并給出了可無限擴展的結(jié)構(gòu),奠定了大模型技術(shù)實現(xiàn)的雙重基礎(chǔ)。
下面是Transformer結(jié)構(gòu)圖:
2.3 大模型的預(yù)訓(xùn)練-微調(diào)范式
大模型代表了一種新的預(yù)訓(xùn)練-微調(diào)范式,其核心是先用大規(guī)模數(shù)據(jù)集預(yù)訓(xùn)練一個極大的參數(shù)模型,然后微調(diào)應(yīng)用到具體任務(wù)。
這與傳統(tǒng)的單任務(wù)訓(xùn)練形成了對比,標志著方法論的重大變革。
參數(shù)量的倍數(shù)增長是大模型最根本的特點,從早期模型的百萬量級,發(fā)展到現(xiàn)在的十億甚至百億量級,實現(xiàn)了與以往數(shù)量級的突破。
Transformer架構(gòu)的提出開啟了NLP模型設(shè)計的新紀元,它引入了自注意力機制和并行計算思想,極大地提高了模型處理長距離依賴關(guān)系的能力,為后續(xù)大模型的發(fā)展奠定了基礎(chǔ)。
正是由于Transformer架構(gòu)的成功,研究者們意識到模型的架構(gòu)設(shè)計在處理復(fù)雜任務(wù)和大規(guī)模數(shù)據(jù)中發(fā)揮著舉足輕重的作用。這一認識激發(fā)了研究者進一步擴大模型參數(shù)量的興趣。雖然之前也曾有過擴大參數(shù)量的嘗試,但因受限于當時模型本身的記憶力等能力,提高參數(shù)數(shù)量后模型的改進并不明顯。
GPT-3的成功充分驗證了適度增大參數(shù)量能顯著提升模型的泛化能力和適應(yīng)性,由此掀起了大模型研究的熱潮。
它憑借過千億參數(shù)量和強大的語言生成能力,成為參數(shù)化模型的典范。GPT-3在許多NLP任務(wù)上表現(xiàn)亮眼,甚至在少樣本或零樣本學(xué)習中也能取得驚人的效果。
增大參數(shù)量的優(yōu)點:
- 更好的表示能力:增大參數(shù)量使模型能夠更好地學(xué)習數(shù)據(jù)中的復(fù)雜關(guān)系和模式,從而提高模型的表示能力,使其在不同任務(wù)上表現(xiàn)更出色。
- 泛化能力和遷移學(xué)習:大模型能夠從一個領(lǐng)域?qū)W習到的知識遷移到另一個領(lǐng)域,實現(xiàn)更好的遷移學(xué)習效果,這對于數(shù)據(jù)稀缺的任務(wù)尤其有價值。
- 零樣本學(xué)習:增大參數(shù)量可以使模型更好地利用已有的知識和模式,從而在零樣本學(xué)習中取得更好的效果,即使只有很少的示例也能完成任務(wù)。
- 創(chuàng)新和探索:大模型的強大能力可以幫助人們進行更多創(chuàng)新性的實驗和探索,挖掘出更多數(shù)據(jù)中的隱藏信息。
2.4 探索大模型:任務(wù)適配性、模型變革與應(yīng)用前景
與早期的人工智能模型相比,大型模型在參數(shù)量上取得了質(zhì)的飛躍,導(dǎo)致了在復(fù)雜任務(wù)的建模能力整體上的提升:
1)學(xué)習能力增強:以應(yīng)對更復(fù)雜的任務(wù);
2)泛化能力加強:以實現(xiàn)更廣泛的適用性;
3)魯棒性提高;
4)具備更高層次認知互動能力:可模擬某些人類能力等。
復(fù)雜性、高維度、多樣性和個性化要求使得大型模型在某些任務(wù)上更易獲得出色的建模能力:
- 多模態(tài)傳感器數(shù)據(jù)的融合分析,尤其涉及到時序數(shù)據(jù)的處理,如自動駕駛
- 復(fù)雜且動態(tài)的目標,需要模型從大規(guī)模多樣化的數(shù)據(jù)模式中學(xué)習,如金融領(lǐng)域中的量化交易策略優(yōu)化
- 涉及異構(gòu)數(shù)據(jù)源的高維輸入空間,如醫(yī)學(xué)圖像和報告
- 需要為不同用戶或場景進行個性化建模的定制化需求,如智能助理

三、自動駕駛技術(shù)迭代路徑
3.1 自動駕駛算法核心模塊概覽
自動駕駛算法模塊可分為感知、決策和規(guī)劃控制三個環(huán)節(jié),其中感知模塊為關(guān)鍵的組成部分
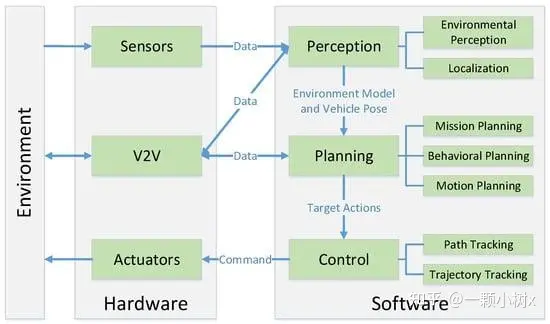
感知模塊:感知模塊負責解析并理解自動駕駛所處車輛周邊的交通環(huán)境,是實現(xiàn)自動駕駛的基礎(chǔ)和前提,感知模塊的精準程度,直接影響并制約著自動駕駛系統(tǒng)的整體安全性和可靠性。
感知模塊主要通過攝像頭、激光雷達、毫米波雷達等各類傳感器獲取輸入數(shù)據(jù),然后通過深度學(xué)習等算法,準確解析出道路標線、其他車輛、行人、交通燈、路標等場景元素,以供后續(xù)流程使用。
決策和規(guī)劃控制:與感知模塊相比,決策和規(guī)劃控制等模塊的作用更為單一和被動。
這些模塊主要依據(jù)感知模塊輸出的環(huán)境理解結(jié)果,通過算法決策生成駕駛策略,并實時規(guī)劃車輛的運動軌跡和速度,最終轉(zhuǎn)換為控制命令,以實現(xiàn)自動駕駛。
但是,大模型在車端賦能主要作用于感知和預(yù)測環(huán)節(jié),逐漸進入決策層。
3.2 CNN
2011-2016:CNN引發(fā)自動駕駛領(lǐng)域的首次革新浪潮
隨著深度學(xué)習和計算能力的提升,卷積神經(jīng)網(wǎng)絡(luò)(CNN)在圖像識別任務(wù)上的出色表現(xiàn)引發(fā)了自動駕駛領(lǐng)域的首次革新浪潮。
- 2011年,IJCNN的論文《Traffic Sign Recognition with Multi-Scale Convolutional Networks》展示了CNN在交通標志識別方面的潛力;
- 2016年,Nvidia團隊發(fā)表的《End-to-End Deep Learning for Self-Driving Cars》成為最早將CNN應(yīng)用于端到端自動駕駛的工作之一。
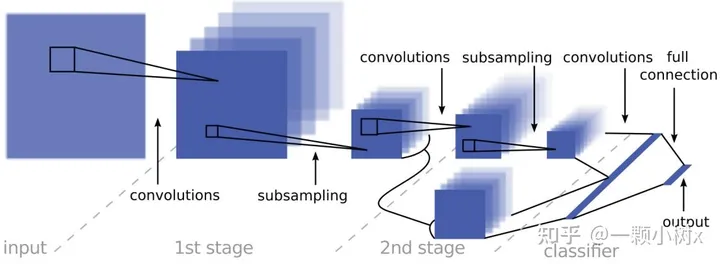
這是一個兩階段的卷積神經(jīng)網(wǎng)絡(luò)架構(gòu),輸入通過兩個卷積和子采樣階段進行前饋處理,最終通過線性分類器進行分類。
CNN極大提升了自動駕駛車輛的環(huán)境感知能力
- 一方面,CNN在圖像識別與處理方面的卓越表現(xiàn),使車輛能夠準確分析道路、交通標志、行人與其他車輛;
- 另一方面,CNN有效處理多種傳感器數(shù)據(jù)的優(yōu)勢,實現(xiàn)了圖像、激光雷達等數(shù)據(jù)的融合,提供全面的環(huán)境認知。疊加計算效率的提高,CNN模型進一步獲得了實時進行復(fù)雜的感知與決策的能力。
但CNN自動駕駛也存在一定局限性:
- 1)需要大量標注駕駛數(shù)據(jù)進行訓(xùn)練,而獲取足夠多樣化數(shù)據(jù)具有難度;
- 2)泛化性能有待提高;
- 3)魯棒性也需要經(jīng)受更復(fù)雜環(huán)境的考驗;
- 4)時序任務(wù)處理能力:相比較而言RNN等其他模型可能更占優(yōu)勢。
3.3 RNN、GAN
2016-2018:RNN和GAN被廣泛應(yīng)用到自動駕駛相關(guān)的研究,推動自動駕駛在對應(yīng)時間區(qū)間內(nèi)快速發(fā)展
RNN相較于CNN更適合處理時間序列數(shù)據(jù):RNN的循環(huán)結(jié)構(gòu)可以建模時間上的動態(tài)變化,這對處理自動駕駛中的軌跡預(yù)測、行為 分析等時序任務(wù)非常有用。例如在目標跟蹤、多智能體互動建模等領(lǐng)域,RNN和LSTM(RNN的改進版本)帶來了巨大突破,可以 預(yù)測車輛未來的運動軌跡,為決策和規(guī)劃提供支持。
GAN的生成能力緩解自動駕駛系統(tǒng)訓(xùn)練數(shù)據(jù)不足的問題:GAN可以學(xué)習復(fù)雜分布,生成高質(zhì)量的合成數(shù)據(jù),為自動駕駛領(lǐng)域帶來 了新思路,用于緩解自動駕駛系統(tǒng)訓(xùn)練數(shù)據(jù)不足的問題。例如GAN可以生成模擬的傳感器數(shù)據(jù)、場景信息,測試自動駕駛算法的 魯棒性,也可以用于交互式模擬場景生成。
RNN+GAN,可以實現(xiàn)端到端的行為預(yù)測和運動規(guī)劃:RNN負責時序建模,GAN負責數(shù)據(jù)生成,兩者相互協(xié)同,可以為自動駕駛系統(tǒng)提供更全面和可靠的環(huán)境感知、狀態(tài)預(yù)測和決策支持。
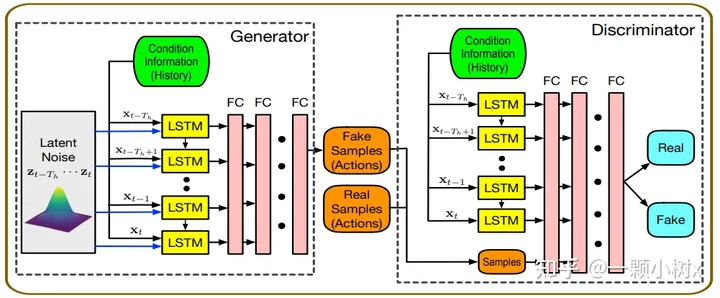
這是融合了LSTM和GAN的模型架構(gòu)示例。
RNN和GAN仍未解決的問題:
- RNN類模型:長期時序建模能力仍較弱,特別是在處理較長的時間序列數(shù)據(jù)時可能出現(xiàn)梯度消失或梯度爆炸的問題,限制了它在某些自動駕駛?cè)蝿?wù)上的應(yīng)用效果。
- GAN模型:生成的數(shù)據(jù)質(zhì)量難以控制,很難達到足夠逼真的程度。此外,盡管GAN可以生成合成數(shù)據(jù),但在實際應(yīng)用中,它在自動駕駛領(lǐng)域的具體應(yīng)用仍相對有限。
- 樣本效率低:RNN和GAN在樣本效率方面仍較低,通常需要大量的真實場景數(shù)據(jù)來訓(xùn)練和優(yōu)化模型。而且這些模型難以解釋,缺乏對內(nèi)部決策過程的清晰解釋,同時模型的穩(wěn)定性和可靠性也是需要進一步解決的問題之一。
RNN和GAN在自動駕駛領(lǐng)域應(yīng)用趨冷的原因:
- 效率和實時性需求:自動駕駛系統(tǒng)需要在實時性要求較高的情況下做出決策和控制。傳統(tǒng)的RNN在處理序列數(shù)據(jù)時,存在計算效率較低的問題,處理實時感知和決策任務(wù)能力有限。
- 復(fù)雜性和泛化能力:自動駕駛涉及復(fù)雜多變的交通場景和環(huán)境,需要具備強大的泛化能力。然而,傳統(tǒng)的RNN可能在處理復(fù)雜的時序數(shù)據(jù)時遇到困難,而無法很好地適應(yīng)各種交通情況。
- 新興技術(shù)的興起:隨著深度學(xué)習領(lǐng)域的發(fā)展,新的模型架構(gòu)和算法不斷涌現(xiàn),如Transformer架構(gòu)、強化學(xué)習等,這些新技術(shù)在處理感知、決策和規(guī)劃等任務(wù)方面可能更加高效和適用。
3.4 BEV
2018-2020:基于鳥瞰視角(BEV)的模型在自動駕駛領(lǐng)域獲得了廣泛的研究和應(yīng)用
BEV模型的核心思想是將車輛周圍的三維環(huán)境數(shù)據(jù)(如來自激光雷達和攝像頭的點云、圖像等數(shù)據(jù))投影到俯視平面上生成二維的鳥瞰圖。這種將三維信息“壓平”成二維表示的方式,為自動駕駛系統(tǒng)的環(huán)境感知和理解帶來了重要優(yōu)勢:
- 鳥瞰圖提供了比直接的原始傳感器數(shù)據(jù)更加直觀和信息豐富的環(huán)境表示,可以更清晰地觀察道路、車輛、行人、標志等元素的位置和關(guān)系,增強自動駕駛對復(fù)雜環(huán)境的感知能力
- 全局的俯視視角更有利于路徑規(guī)劃和避障系統(tǒng)進行決策,根據(jù)道路和交通狀況規(guī)劃更合理穩(wěn)定的路徑
- BEV模型可以將來自不同傳感器的輸入數(shù)據(jù)統(tǒng)一到一個共享表示中,為系統(tǒng)提供更加一致和全面的環(huán)境信息
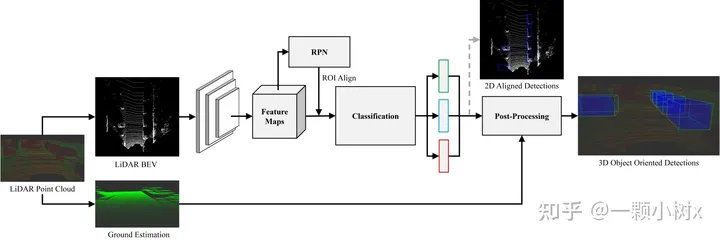
這是BirdNet 3D 對象檢測框架,網(wǎng)絡(luò)的三個輸出是:類別(綠色)、2d 邊界框(藍色)和偏航角(紅色)。
但是,BEV模型也存在一些問題亟待解決:
- 從原始三維數(shù)據(jù)生成BEV表示需要進行大量坐標變換和數(shù)據(jù)處理,增加了計算量和對硬件的要求
- 信息損失問題,三維信息投影到二維時難免會損失一些細節(jié),如遮擋關(guān)系等
- 不同傳感器到BEV坐標系的轉(zhuǎn)換也需要進行復(fù)雜的標定和校準
- 需要研究如何有效融合各種異構(gòu)數(shù)據(jù)源,以生成更加準確和完整的BEV
3.5 Transformer+BEV
2020年以來, Transformer+BEV結(jié)合正在成為自動駕駛領(lǐng)域的重要共識,推動自動駕駛技術(shù)進入嶄新發(fā)展階段
將Transformer模型與BEV(鳥瞰視角)表示相結(jié)合的方法,正在成為自動駕駛領(lǐng)域的重要共識,推動完全自主駕駛的實現(xiàn)
- 一方面,BEV可以高效表達自動駕駛系統(tǒng)周圍的豐富空間信息;
- 另一方面,Transformer在處理序列數(shù)據(jù)和復(fù)雜上下文關(guān)系方面展現(xiàn)了獨特優(yōu)勢,在自然語言處理等領(lǐng)域得到成功應(yīng)用。兩者結(jié)合可以充分利用BEV提供的環(huán)境空間信息,以及Transformer在多源異構(gòu)數(shù)據(jù)建模方面的能力,實現(xiàn)更精確的環(huán)境感知、更長遠的運動規(guī)劃和更全局化的決策。
特斯拉率先引入BEV+Tranformer大模型,與傳統(tǒng)2D+CNN小模型相比,大模型的優(yōu)勢主要在于:
- 1)提高感知能力:BEV將激光雷達、雷達和相機等多模態(tài)數(shù)據(jù)融合在同一平面上,可以提供全局視角并消除數(shù)據(jù)之間的遮擋和重疊問題,提高物體檢測和跟蹤的精度;
- 2)提高泛化能力:Transformer模型提取特征函數(shù),通過注意力機制尋找事物本身的內(nèi)在關(guān)系,使智能駕駛學(xué)會總結(jié)歸納而不是機械式學(xué)習。主流車企及自動駕駛企業(yè)均已布局BEV+Transformer,大模型成為自動駕駛算法的主流趨勢。
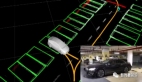
下面是Transformer+BEV的示例框圖:
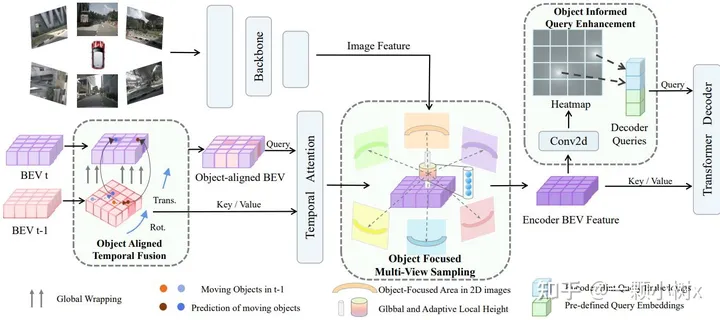
(a) 對象對齊時間融合:首先根據(jù)車輛自身的移動情況,把 當前時刻(t時刻)的鳥瞰視角地圖變形調(diào)整成上一時刻(t-1 時刻)的樣子。這樣就可以根據(jù)對象在上一時刻的位置, 結(jié)合速度預(yù)測出它當前的位置,從而實現(xiàn)對象在不同時刻 地圖上的融合。
(b) 對象聚焦多視圖采樣:首先在三維空間預(yù)設(shè)一些點,然后把這些點投影到圖像上的特征上。這樣不僅可以在整個高度范圍采樣,還可以對某些主要對象按照自適應(yīng)和聚焦的方式,在它們所處的局部空間區(qū)域采樣更多點。
(c) 對象通知查詢增強:在編碼器處理圖像特征后,添加熱圖的監(jiān)督信息。同時用檢測到對象高置信度位置對應(yīng)的點 來替換掉原本預(yù)設(shè)要查詢的一些點。
下面是Transformer+BEV的示例框圖2:
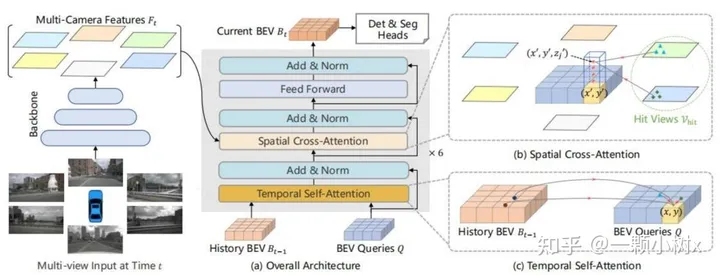
GPT的出現(xiàn)對Transformer+BEV模型的產(chǎn)生起到了重要影響
- GPT的成功表明了Transformer模型的潛力,促使更多研究者將Transformer應(yīng)用到計算機視覺和自動駕駛領(lǐng)域,產(chǎn)生了 Transformer+BEV的創(chuàng)新做法。
- GPT的預(yù)訓(xùn)練思想為Transformer+BEV的預(yù)訓(xùn)練和遷移學(xué)習提供了借鑒,可以通過預(yù)訓(xùn)練捕捉語義信息,然后遷移應(yīng)用。
- OpenAI公開的代碼和模型也加速了Transformer類模型在各領(lǐng)域的研究進程。
當前Transformer+BEV模型受關(guān)注,主要基于它綜合了Transformer和BEV各自的優(yōu)勢
- Transformer擅長處理序列數(shù)據(jù),捕捉語義信息;而BEV提供場景整體觀,有利解析空間關(guān)系。兩者組合可實現(xiàn)互補,增強 對復(fù)雜場景的理解表達。
- 自動駕駛數(shù)據(jù)積累為訓(xùn)練大模型奠定基礎(chǔ)。大數(shù)據(jù)支持學(xué)習更復(fù)雜特征,提升環(huán)境感知精度,也使端到端學(xué)習成為可能。
- 提升安全性和泛化能力仍是自動駕駛核心難題。目前階段Transformer+BEV較好地結(jié)合語義理解和多視角建模,可處理相對 不常見、復(fù)雜或者挑戰(zhàn)性的交通場景或環(huán)境,具有很大潛力。
3.6 占用網(wǎng)絡(luò)模型
2022年,自動駕駛系統(tǒng)中使用了占用網(wǎng)絡(luò)模型,實現(xiàn)了對道路場景的高效建模
占用網(wǎng)絡(luò)模型
- 占用網(wǎng)絡(luò)是特斯拉在2022年應(yīng)用到自動駕駛感知的一種技術(shù),相較于BEV可以更精準地還原自動駕駛汽車行駛周圍3D環(huán)境,提升車輛的環(huán)境感知能力。
- 占用網(wǎng)絡(luò)包含兩部分:一個編碼器學(xué)習豐富語義特征,一個解碼器可以生成三維場景表達。
- 特斯拉使用車載攝像頭采集的大量行車數(shù)據(jù),訓(xùn)練占用網(wǎng)絡(luò)模型。解碼器部分能夠復(fù)原和想象各種場景,增強異常情況下的感知棒性。
- 占用網(wǎng)絡(luò)技術(shù)使特斯拉可以充分利用非標注數(shù)據(jù),有效補充標注數(shù)據(jù)集的不足。這對于提升自動駕駛安全性、減少交通事故具有重要意義。特斯拉正在持續(xù)改進該技術(shù)在自動駕駛系統(tǒng)中的集成應(yīng)用。
特斯拉在2023年AI Day公開了occupancy network(占用網(wǎng)絡(luò))模型,基于學(xué)習進行三維重建,意圖為更精準地還原自動駕 駛汽車行駛周圍3D環(huán)境,可視作BEV視圖的升華迭代:
- BEV+Transformer的不足:鳥瞰圖為2D圖像,會缺失一些空間高度信息,無法真實反映物體在3D空間的實際占用體積, 故而在BEV中更關(guān)心靜止物體(如路沿、車道線等),而空間目標的識別(如物體3D結(jié)構(gòu))難以識別
- 占用網(wǎng)絡(luò):現(xiàn)存三維表示方法(體素、網(wǎng)格、點云)在儲存、結(jié)構(gòu)和是否利于學(xué)習方面均不夠完全理想,而占用網(wǎng)絡(luò)基于學(xué)習將三維曲面表示為深度神經(jīng)網(wǎng)絡(luò)分類器的連續(xù)決策邊界,可以在沒有激光雷達提供點云數(shù)據(jù)的情況下對3D環(huán)境進行重建,且相較于激光雷達還可以更好地將感知到的3D幾何信息與語義信息融合,得到更加準確的三維場景信息
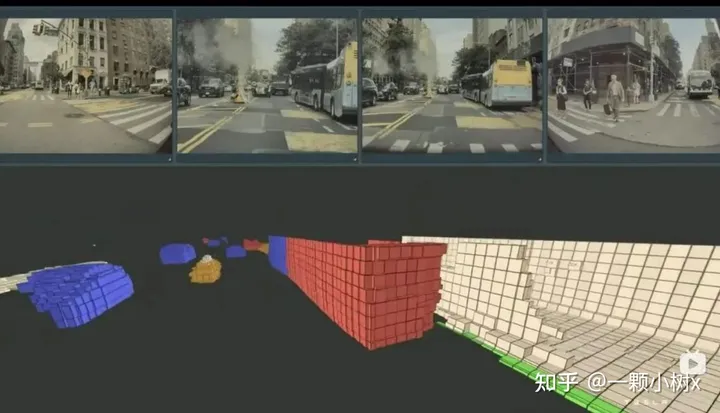
華為ADS 2.0進一步升級GOD 網(wǎng)絡(luò),道路拓撲推理網(wǎng)絡(luò)進一步增強,類似于特斯拉的占用網(wǎng)絡(luò)。
- GOD 2.0(通用障礙物檢測網(wǎng)絡(luò), General Obstacle Detection)障礙物識別無上限,障礙物識別率達到99.9%;
- RCR2.0能識別更多路,感知面積達到2.5個足球場,道路拓撲實時生成。
- 2023年12月,搭載ADS 2.0的問界新M7可實現(xiàn)全國無高精地圖的高階智能駕駛。
對比BEV效果,下面BEV鳥瞰視圖

下面是占用網(wǎng)絡(luò)3D視圖:

四、大模型對自動駕駛行業(yè)的賦能
4.1 自動駕駛的大模型
以GPT為代表的大模型通常包含億級甚至百億級參數(shù),采用Transformer結(jié)構(gòu)進行分布式訓(xùn)練,以提升模型能力。
GPT的成功激發(fā)了:自動駕駛研究者利用類似架構(gòu)進行端到端學(xué)習,甚至涌現(xiàn)出專為自動駕駛設(shè)計的預(yù)訓(xùn)練模型。這些努力為自動駕駛行業(yè)帶來新思路,大模型通過強大的數(shù)據(jù)分析和模式識別能力,增強了自動駕駛系統(tǒng)的安全性、效率和用戶體驗,實現(xiàn)了更準確的環(huán)境感知、 智能決策。

大模型的應(yīng)用加速模型端的成熟,為L3/L4級別的自動駕駛技術(shù)落地提供了更加明確的預(yù)期
模型的成熟使得自動駕駛系統(tǒng)更加穩(wěn)定和可靠,為商業(yè)化應(yīng)用奠定了基礎(chǔ)。隨著深度學(xué)習和神經(jīng)網(wǎng)絡(luò)技術(shù)的迅速發(fā)展,模型在 感知、決策和控制等方面取得了顯著進展,向著高效地處理大量傳感器數(shù)據(jù),準確識別交通標志、行人、車輛等、實現(xiàn)環(huán)境感 知的方向發(fā)展。此外,模型也能夠輔助實時路徑規(guī)劃和決策制定,使車輛能夠在復(fù)雜的交通環(huán)境中安全行駛。
大模型的應(yīng)用為L3/L4級別的自動駕駛技術(shù)落地提供了更加明確的預(yù)期,尤其特斯拉在前沿技術(shù)領(lǐng)域的探索,正在成為實現(xiàn)L3/L4級別自動駕駛落地的風向標。特斯拉提出的Transformer+BEV+占用網(wǎng)絡(luò)算法讓車輛能夠更精準地理解復(fù)雜的交通環(huán)境, 為L3/L4級別的自動駕駛系統(tǒng)提供更強的環(huán)境感知能力,從而在城市道路和高速公路等特定場景中更自信地行駛。
國內(nèi)重要自動駕駛政策節(jié)選
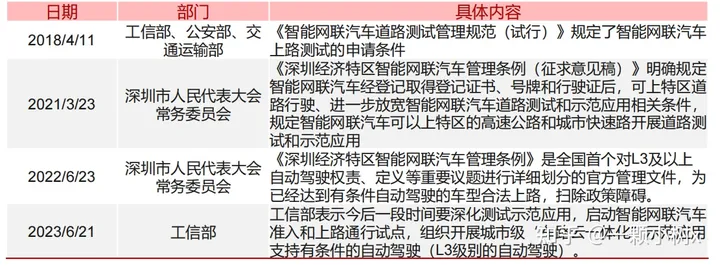
安全性自動駕駛汽車實現(xiàn)商業(yè)化落地必不可少的重要因素
為保證自動駕駛系統(tǒng)的安全可靠,按照國家監(jiān)管要求,自動駕駛車輛必須經(jīng)過5000公里以上的封閉場地訓(xùn)練評估,且測試駕駛員須通過不少于50小時培訓(xùn),并通過車輛安全技術(shù)檢驗后方可申請上路測試資格。目前我國智能網(wǎng)聯(lián)汽車道路測試總里 程已超7000萬公里,我們預(yù)計L3級及以上自動駕駛汽車開放個人使用上路試點區(qū)域仍需一定的時間才能實現(xiàn)。
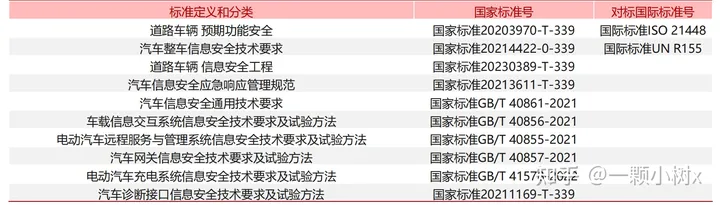
汽車通信安全和數(shù)據(jù)安全也需達到國標或相關(guān)條例要求。我們預(yù)計未來中國會參考歐美國家實踐,進一步細化安全要求,加強相關(guān)法規(guī)制度建設(shè),如制定自動駕駛汽車安全評估標準、明確自動駕駛系統(tǒng)開發(fā)生命周期各階段的安全保障要求、建立自 動駕駛汽車事故責任認定機制等。
部分自動駕駛汽車安全標準:
4.2 車端賦能主要作用于感知和預(yù)測環(huán)節(jié),逐漸進入決策層
大模型在自動駕駛中的應(yīng)用簡單來說,就是把整車采集到的數(shù)據(jù)回傳到云端,通過云端部署的大模型,對數(shù)據(jù)進行相近的訓(xùn)練。
大模型主要作用于自動駕駛的感知和預(yù)測環(huán)節(jié)。
- 在感知層,可以利用Transformer模型對BEV數(shù)據(jù)進行特征提取,實現(xiàn)對障礙物的監(jiān)測和定位;
- 預(yù)測層基于感知模塊的輸出,利用Transformer模型捕捉學(xué)習交通參與者的運動模式和歷史軌跡數(shù)據(jù),預(yù)測他們未來行為和軌跡。
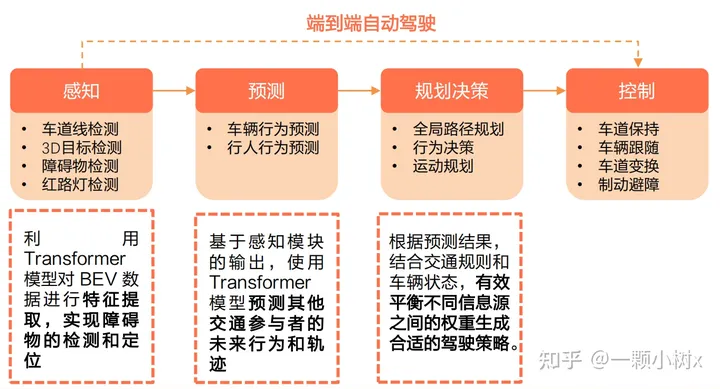
未來將驅(qū)動駕駛策略生成逐漸從規(guī)則驅(qū)動向數(shù)據(jù)驅(qū)動轉(zhuǎn)變。規(guī)劃決策層的駕駛策略的生成有兩種方式:
1)基于數(shù)據(jù)驅(qū)動的深度學(xué)習算法;
2)基于規(guī)則驅(qū)動(出于安全考慮,目前普遍采取基于規(guī)則生成駕駛策略,但隨著自動駕駛等級的提升及應(yīng)用場景的不斷拓展,基于規(guī)則 的規(guī)控算法存在較多Corner Case處理局限性)。
結(jié)合車輛動力學(xué),可利用Transformer模型生成合適的駕駛策略:
將動態(tài)環(huán)境、路況信息、 車輛狀態(tài)等數(shù)據(jù)整合到模型中,Transformer多頭注意力機制有效平衡不同信息源之間的權(quán)重,以便快速在復(fù)雜環(huán)境中做出合理決策。
本文內(nèi)容來以下資料:
- AI+行業(yè)系列之智能駕駛:自動駕駛的“大模型”時代
- 智能汽車行業(yè)專題研究:大模型應(yīng)用下自動駕駛賽道將有哪些變化
- 2023年行業(yè)大模型標準體系及能力架構(gòu)研究報告
- 人工智能行業(yè)專題報告:多模態(tài)AI研究框架
- AI大時代系列報告之一(基礎(chǔ)篇):大模型與算力共振,奇點時刻到來
- 等等......
分享完成,本文只供大家參考與學(xué)習,謝謝~