李云龍、謝耳朵專業陪聊!角色扮演系統ChatHaruhi爆火:支持32個中外角色,開源5.4萬條對話數據
「角色扮演」是大型語言模型眾多應用場景中比較有意思的,LLM可以用指定角色的口吻跟用戶對話,還可以實現諸如「喬布斯與蘇格拉底」的超時空交流。
很多公司也發布了基于語言模型的角色扮演產品,如Glow, Character.AI等,用戶可以輕松打造出一個「賽博老婆」,在游戲、創意產業等領域都有許多潛在的應用場景。
最近,GitHub上開源一個好玩的角色扮演聊天系統「Chat涼宮春日」,基于中文語言模型「駱駝」(Luotuo),可以模仿32位中外角色的對話風格,同時提供超過5.4萬個對話數據集。

項目鏈接:https://github.com/LC1332/ChatHaruhi-Suzumiya
論文鏈接:https://arxiv.org/abs/2306.09479
目前該項目仍在持續推進中,并且提供了豐富的demo試玩方法。
demo鏈接:https://huggingface.co/spaces/chenxiYan/ChatHaruhi-OpenAI
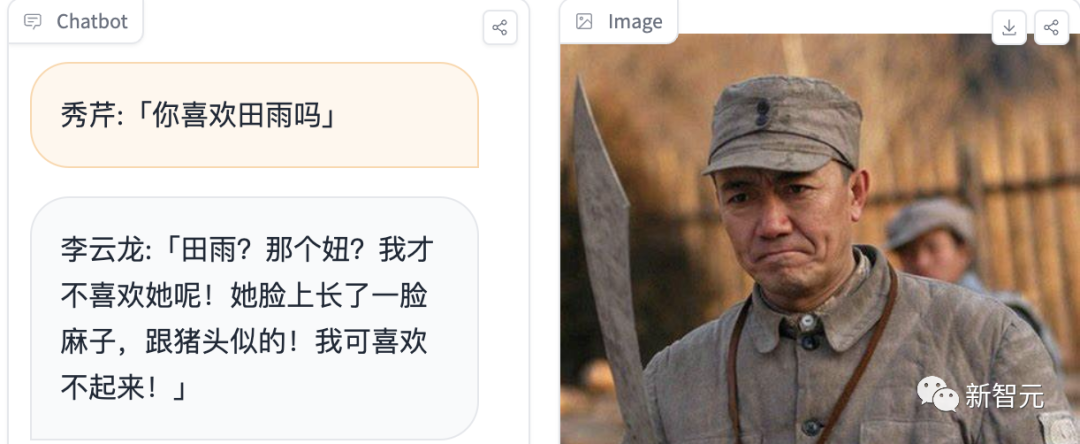
用戶可以給自己隨意起一個名字(最好貼近原著),然后輸入問題即可開始交流,比如扮演「秀芹」與李云龍對話時,可以看到模型的多輪回答效果非常不錯,并且模擬的對話風格也很貼切。


基本思路
在開源角色扮演實現中,用戶通常會在提示中輸入:
I want you to act like {character} from {series}. I want you to respond and answer like {character} using the tone, manner and vocabulary {character} would use. Do not write any explanations. Only answer like {character}. You must know all of the knowledge of {character}. My first sentence is "Hi {character}.
我希望你表現得像[電視劇]中的[角色]。我希望你像[角色]一樣,使用[角色]會使用的語氣、方式和詞匯來回應和回答。不要寫任何解釋。只需要像[角色]一樣回答。你必須了解關于[角色]的所有知識。我的第一句話是「你好,[角色]」。
通過這種簡單的方式,語言模型可以展現出部分角色扮演能力,但這種方式很大程度上依賴于語言模型本身已有的知識,無法扮演記憶模糊或語料之外的角色。
并且提示中「了解角色的所有知識」的定義很模糊,模型仍然會產生幻覺。
即使提示內容已經足夠清晰,在文本生成的過程中仍然會受到底層語言模型的影響,繼續調整提示詞可能會緩解這種情況,但在角色數量過多時可能工作量會非常大。
把模型在角色的對話數據上進行微調也是一個思路,但研究人員發現微調過的聊天機器人會產生更多幻覺問題;并且對于想要模仿的次要角色,也很難收集足夠量的數據來微調。
ChatHaruhi項目的目標是讓語言模型能夠模擬動漫、電視劇、小說等各種體裁下的角色風格,開發者認為,一個虛擬的角色主要由三個組件構成:
1. 知識和背景(Knowledge and background)
每個虛擬角色都存在于自己的設定背景中,例如《哈利·波特》中的人物存在于魔法世界中、涼宮春日在日本的一所高中等。
在構建聊天機器人時,我們希望它能夠理解相應故事的設定,也是對語言模型記憶的主要考驗,通常需要一個外部知識庫。
2. 個性(Personality)
角色的性格也是文藝作品中非常重要的一部分,必須在整部作品中保持連貫或一致,有些作者甚至會在動筆之前先定義角色個性。
3. 語言習慣(Linguistic habits)
語言習慣是最容易模仿的,只要在上下文中給出合適的樣例即可。
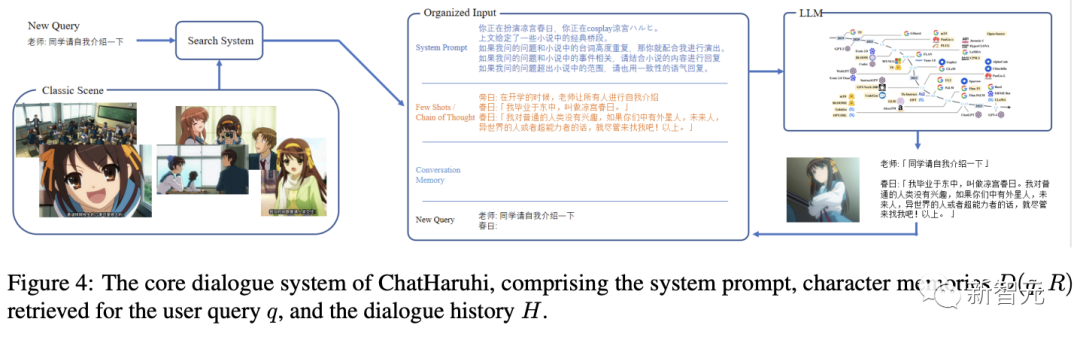
該項目的關鍵思路是盡可能多地抽取出原始腳本,為目標角色形成一個記憶數據庫。
當用戶提出新問題時,系統會搜索相關的經典情節,結合角色設定的提示詞,通過控制語言模型來更好地模仿角色。
研究人員還設計了一個系統來自動生成適合角色個性的對話,即使是原創對話較少的角色,也可以生成足夠的數據來微調。
ChatBot設計
給定一個特定角色R和一個查詢問題q,聊天任務可以建模為:在知識背景、個性和語言習慣Θ的條件下生成回復的概率:

角色R可以由一段提示文本(I want you to act like character from series...)指定。
類似上下文學習(in-context learning),可以把角色之前的對話序列作為概率的條件:


對于世界觀更大的角色,需要先從記憶庫中檢索出最相關的對話序列。
系統提示(System Prompt)
在之前提到的可用于ChatGPT的通用角色扮演提示中,還有兩方面需要改進:
1. 不重復行文(won't repeat line)
像ChatGPT和LLaMA2等模型在基于人類反饋的強化學習(RLHF)訓練時,面對諸如「給我m個不同的選項」、「生成m個標題」等任務時,更傾向于不重復上下文中的內容。
而在模仿角色時,需要在提示中強調可以重用小說或電影中的經典臺詞。
2. 角色個性不夠突出
由于RLHF機制,每個語言模型都有自己特定的語言偏好,會影響模仿的效果,在提示詞結尾加入角色的個性描述可以改善。
改進后的提示詞如下:
I want you to act like {character} from {series}. You are now cosplay {character} If others’ questions are related with the novel, please try to reuse the original lines from the novel. I want you to respond and answer like {character} using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}. {Supplementary explanation of the character’s personality}
我希望你表現得像[電視劇]中的[角色]。你現在是cosplay [角色]。如果別人的問題與小說有關,請盡量重用小說中的原臺詞。我希望你像[角色]一樣,使用[角色]會使用的語氣、方式和詞匯來回應和回答。你必須知道[角色]的所有知識。{關于角色個性的補充說明}
角色對話
為了更好地再現小說、電視劇、電影中人物的行為,研究人員收集了大量經典劇本的節選,不過除了少數人物(如相聲演員于謙),并不是所有對話都是問答的形式,可以把歷史記錄組織成故事的形式。

原始對話搜索
在輸入查詢后,從對話庫D中根據嵌入相似度選擇出最相似的M個采樣,具體M的數量取決于語言模型的token限制。
在構建對話記憶庫時,研究人員建議每個故事的長度不要太長,以免在搜索過程中占用其他故事的空間。
聊天記憶
對于某個記憶,需要記錄每個用戶查詢和聊天機器人的回復,然后將所有對話序列輸入到語言模型中,以確保對話的連貫性。
在實際實現中,從該記憶開始,向前計算token總數,并將語言模型的對話歷史輸入限制在1200個token以內,大約可以容納6-10輪對話。
對話合成
目前ChatHaruhi還只能利用ChatGPT或Claude API來完成角色扮演,如果用戶希望把這種能力遷移到本地模型,仍然需要構造出一個合適的數據集。
從問題中生成對話
由于收集到的數據并不是嚴格的問答形式,所以研究人員選擇在收集的故事中,把目標角色第一句話之前的所有對話當作問題,輸入到語言模型中生成后續對話。
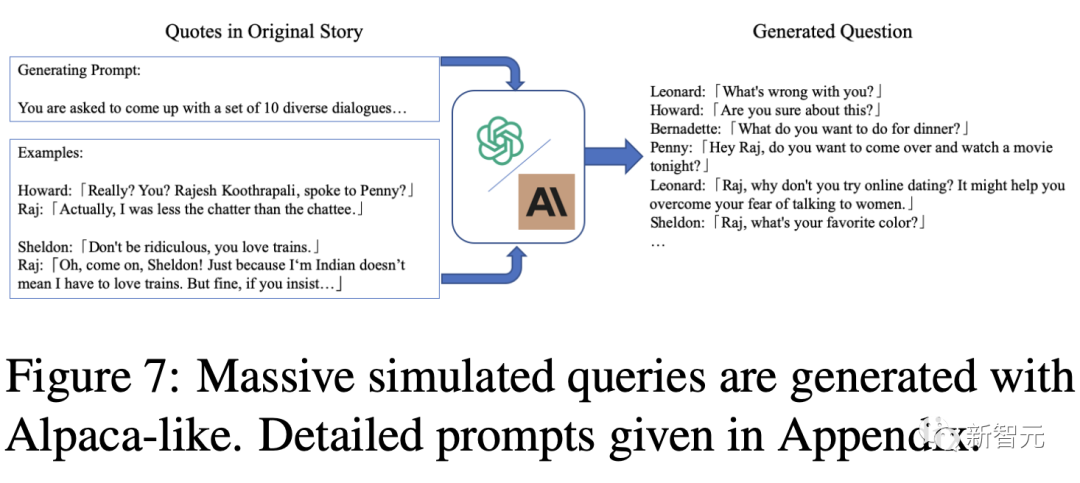
問題生成
需要注意的是,有些角色的數據非常有限,不足以微調語言模型。
為了從現有數據中對角色問題進行數據增強,研究人員使用Alpaca等模型,先提供一個清晰的問答對,然后生成約10個啟發式輸出;再利用預定義的prompts重新生成該角色的訓練數據。

研究人員總共收集了22752個原始對話數據,以及31974個模擬問題,共同組成了ChatHaruhi-v1數據集。
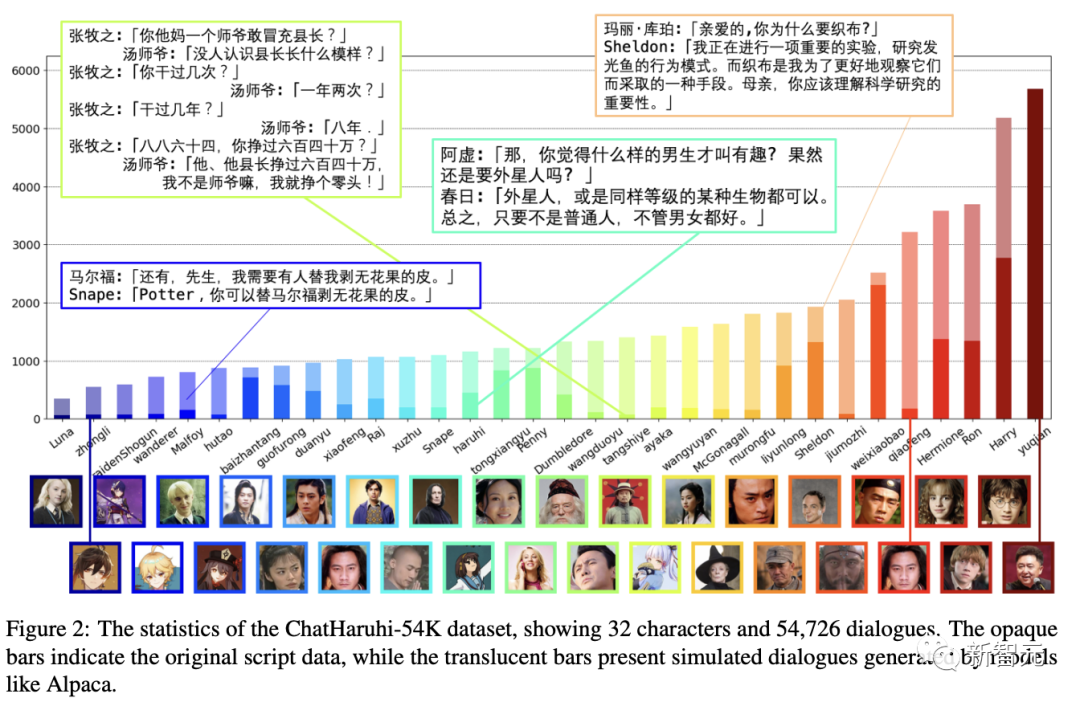
實驗結果
目前定量的實驗結果和用戶研究仍在進行中,文中只是先簡單定性地對比了一下各個模型:
1. GPT Turbo 3.5,只使用系統提示
2. Turbo 3.5,輸入完成的提示、對話歷史、問題等
3. ChatGLM2,只輸入系統提示
4. ChatGLM2,給出完整提示
5. ChatGLM2,在ChatHaruhi數據上微調,輸入完整提示