













使用 OpenTelemetry Collector 采集 Kubernetes 指標數據

Kubernetes 已成為一個被廣泛采用的行業工具,對可觀測性工具的需求也在不斷增加。為此,OpenTelemetry 創建了許多不同的工具,來幫助 Kubernetes 用戶觀察他們的集群和服務。
接下來我們將開始使用 OpenTelemetry 監控 Kubernetes 集群,將專注于收集 Kubernetes 集群、節點、pod 和容器的指標和日志,并使集群能夠支持發出 OTLP 數據的服務。
Kubernetes 以多種不同的方式暴露了許多重要的遙測數據。它具有用于許多不同對象的日志、事件和指標,以及其工作負載生成的數據。 為了收集這些數據,我們將使用 OpenTelemetry Collector。該收集器可以高效地收集所有這些數據。
為了收集所有的數據,我們將需要安裝兩個收集器,一個作為 Daemonset,一個作為 Deployment。收集器的 DaemonSet 將用于收集服務、日志和節點、Pod 和容器的指標,而 Deployment 將用于收集集群的指標和事件。
為了安裝收集器,我們這里將使用 OpenTelemetry Collector Helm 圖表(https://github.com/open-telemetry/opentelemetry-helm-charts/tree/main/charts/opentelemetry-collector),該圖表帶有一些配置選項,可以更輕松地配置收集器。
首先需要添加 OpenTelemetry Helm 倉庫:
$ helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
$ helm repo update收集 Kubernetes 遙測數據的第一步是部署一個 OpenTelemetry Collector 的 DaemonSet 實例,以收集與節點和運行在這些節點上的工作負載相關的遙測數據。使用 DaemonSet 可以確保此收集器實例被安裝在所有節點上。每個 DaemonSet 中的收集器實例將僅從其運行的節點收集數據。
通過 OpenTelemetry Collector Helm Chat 配置所有這些組件非常簡單,它還會處理所有與 Kubernetes 相關的細節,例如 RBAC、掛載和主機端口等。不過需要注意的是,默認情況下這個 Chart 圖表不會將數據發送到任何后端。
指標采集
我們這里首先創建一個 Prometheus 實例來收集指標數據,如下所示,我們使用 Helm Chart 來快速部署 Prometheus:
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update然后創建一個 prometheus-values.yaml 文件來配置 Prometheus Helm Chart:
# prometheus-values.yaml
kubeStateMetrics:
enabled: false
nodeExporter:
enabled: false
kubelet:
enabled: false
kubeApiServer:
enabled: false
kubeControllerManager:
enabled: false
coreDns:
enabled: false
kubeDns:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: false
sidecar:
datasources:
label: grafana_datasource
labelValue: "1"
dashboards:
enabled: true
prometheus:
prometheusSpec:
enableFeatures:
- remote-write-receiver
prometheusOperator:
enabled: true
admissionWebhooks:
patch:
enabled: true
image:
registry: cnych
repository: ingress-nginx-kube-webhook-certgen
tag: v20221220-controller-v1.5.1-58-g787ea74b6
grafana:
ingress:
enabled: true
ingressClassName: nginx
hosts:
- grafana.k8s.local注意這里我們沒有定制任何 Exporter,因為我們將使用 OpenTelemetry Collector 來收集指標數據,然后再將其發送到 Prometheus 中。此外為了能夠將收集器指標發送到 Prometheus ,我們需要啟用遠程寫入功能,正常只需要在 Prometheus 啟動參數中指定 --web.enable-remote-write-receiver 即可,但是我們這里是通過 Prometheus Operator 方式部署的,所以我們需要去修改 Prometheus 的 CR 實例對象,啟用 remote-write-receiver 特性。另外我們還為 Grafana 啟用了 Ingress,這樣我們就可以通過 grafana.k8s.local 來訪問 Grafana 了,默認用戶名為 admin,密碼為 prom-operator。
接下來直接使用下面的命令一鍵部署 Prometheus 即可:
$ helm upgrade --install prometheus prometheus-community/kube-prometheus-stack -f prometheus-values.yaml --namespace kube-otel --create-namespace
Release "prometheus" does not exist. Installing it now.
NAME: prometheus
LAST DEPLOYED: Wed Aug 23 09:42:23 2023
NAMESPACE: kube-otel
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace kube-otel get pods -l "release=prometheus"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.部署后的資源對象如下所示:
$ kubectl get pods -n kube-otel
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 0 6m3s
prometheus-grafana-5d95cbc57f-v2bw8 3/3 Running 0 61s
prometheus-kube-prometheus-operator-74fcfc7ff6-2bzfj 1/1 Running 0 6m19s
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 0 6m3s
$ kubectl get ingress -n kube-otel
NAME CLASS HOSTS ADDRESS PORTS AGE
prometheus-grafana nginx grafana.k8s.local 10.98.12.94 80 114s現在我們需要將指標數據發送到 Prometheus,所以我們需要在 Otel 采集器里面去配置導出器,可以使用到 prometheus 或者 prometheusremotewrite 導出器。我們這里將使用如下的 otel-collector-ds-values.yaml 文件來配置 OpenTelemetry Collector Helm Chart:
# otel-collector-ds-values.yaml
mode: daemonset
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
clusterRole:
create: true
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
verbs:
- get
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- get
presets:
hostMetrics:
enabled: true
kubernetesAttributes:
enabled: true
kubeletMetrics:
enabled: true
ports:
prom: # 添加一個 9090 端口,用于 Prometheus 抓取
enabled: true
containerPort: 9090
servicePort: 9090
protocol: TCP
service: # 創建一個 Service,后面 ServiceMonitor 會用到
enabled: true
config:
receivers:
prometheus:
config:
scrape_configs:
- job_name: opentelemetry-collector
scrape_interval: 10s
static_configs:
- targets:
- ${env:MY_POD_IP}:8888
exporters:
logging:
loglevel: debug
prometheus:
endpoint: "0.0.0.0:9090"
metric_expiration: 180m
resource_to_telemetry_conversion:
enabled: true
# prometheusremotewrite:
# endpoint: http://prometheus-kube-prometheus-prometheus:9090/api/v1/write
# tls:
# insecure: true
processors:
metricstransform:
transforms:
include: .+
match_type: regexp
action: update
operations:
- action: add_label
new_label: k8s.cluster.id
new_value: abcd1234
- action: add_label
new_label: k8s.cluster.name
new_value: youdian-k8s
service:
pipelines:
metrics:
exporters:
- prometheus
processors:
- memory_limiter # 內存限制一般放在最前面
- metricstransform
- k8sattributes
- batch # 批量處理器放在最后
receivers:
- otlp
- hostmetrics
- kubeletstats
- prometheus直接使用上面的配置文件來部署 OpenTelemetry Collector DaemonSet:
$ helm upgrade --install opentelemetry-collector open-telemetry/opentelemetry-collector -f otel-ds-values.yaml --namespace kube-otel --create-namespace
$ kubectl get pods -n kube-otel
NAME READY STATUS RESTARTS AGE
opentelemetry-collector-agent-22rsm 1/1 Running 0 18h
opentelemetry-collector-agent-v4nkh 1/1 Running 0 18h
opentelemetry-collector-agent-xndlq 1/1 Running 0 18h安裝后我們可以查看當前采集器的配置信息,使用命令 kubectl get cm -n kube-otel opentelemetry-collector-agent -oyaml:
exporters:
logging:
loglevel: debug
prometheus:
endpoint: 0.0.0.0:9090
metric_expiration: 180m
resource_to_telemetry_conversion:
enabled: true
extensions:
health_check: {}
memory_ballast:
size_in_percentage: 40
processors:
batch: {}
k8sattributes:
extract:
metadata:
- k8s.namespace.name
- k8s.deployment.name
- k8s.statefulset.name
- k8s.daemonset.name
- k8s.cronjob.name
- k8s.job.name
- k8s.node.name
- k8s.pod.name
- k8s.pod.uid
- k8s.pod.start_time
filter:
node_from_env_var: K8S_NODE_NAME
passthrough: false
pod_association:
- sources:
- from: resource_attribute
name: k8s.pod.ip
- sources:
- from: resource_attribute
name: k8s.pod.uid
- sources:
- from: connection
memory_limiter:
check_interval: 5s
limit_percentage: 80
spike_limit_percentage: 25
metricstransform:
transforms:
action: update
include: .+
match_type: regexp
operations:
- action: add_label
new_label: k8s.cluster.id
new_value: abcd1234
- action: add_label
new_label: k8s.cluster.name
new_value: youdian-k8s
receivers:
hostmetrics:
collection_interval: 10s
root_path: /hostfs
scrapers:
cpu: null
disk: null
filesystem:
exclude_fs_types:
fs_types:
- autofs
- binfmt_misc
- bpf
- cgroup2
- configfs
- debugfs
- devpts
- devtmpfs
- fusectl
- hugetlbfs
- iso9660
- mqueue
- nsfs
- overlay
- proc
- procfs
- pstore
- rpc_pipefs
- securityfs
- selinuxfs
- squashfs
- sysfs
- tracefs
match_type: strict
exclude_mount_points:
match_type: regexp
mount_points:
- /dev/*
- /proc/*
- /sys/*
- /run/k3s/containerd/*
- /var/lib/docker/*
- /var/lib/kubelet/*
- /snap/*
load: null
memory: null
network: null
kubeletstats:
auth_type: serviceAccount
collection_interval: 20s
endpoint: ${K8S_NODE_NAME}:10250
otlp:
protocols:
grpc:
endpoint: ${env:MY_POD_IP}:4317
http:
endpoint: ${env:MY_POD_IP}:4318
prometheus:
config:
scrape_configs:
- job_name: opentelemetry-collector
scrape_interval: 10s
static_configs:
- targets:
- ${env:MY_POD_IP}:8888
service:
extensions:
- health_check
- memory_ballast
pipelines:
metrics:
exporters:
- prometheus
processors:
- memory_limiter
- metricstransform
- k8sattributes
- batch
receivers:
- otlp
- hostmetrics
- kubeletstats
- prometheus
telemetry:
metrics:
address: ${env:MY_POD_IP}:8888
# ...... 省略其他上面的配置信息是 OpenTelemetry Collector 真正運行時的配置信息,我們這里只保留了和 metrics 相關的配置。從上面配置文件可以看出我們定義了 4 個接收器:
- hostmetrics 接收器
- kubeletstats 接收器
- otlp 接收器
- prometheus 接收器
4 個處理器:
- batch 處理器
- memory_limiter 處理器
- k8sattributes 處理器
- metricstransform 處理器
2 個導出器:
- logging 導出器
- prometheus 導出器
下面我們來詳細介紹一下其他組件。
otlp 接收器
otlp 接收器是在 OTLP 格式中收集跟蹤、指標和日志的最佳解決方案。如果您在以其他格式發出應用程序遙測數據,那么收集器很有可能也有一個相應的接收器。這個前面我們已經詳細介紹過了,我們這里定義了 http 和 grpc 兩種協議,分別監聽 4317 和 4318 端口。配置如下所示:
receivers:
otlp:
protocols:
grpc:
endpoint: ${env:MY_POD_IP}:4317
http:
endpoint: ${env:MY_POD_IP}:4318hostmetrics 接收器
hostmetrics 接收器用于收集主機級別的指標,例如 CPU 使用率、磁盤使用率、內存使用率和網絡流量。我們這里的配置如下所示:
receivers:
hostmetrics:
collection_interval: 10s
root_path: /hostfs
scrapers:
cpu: null
disk: null
filesystem:
exclude_fs_types:
fs_types:
- autofs
- binfmt_misc
- bpf
- cgroup2
- configfs
- debugfs
- devpts
- devtmpfs
- fusectl
- hugetlbfs
- iso9660
- mqueue
- nsfs
- overlay
- proc
- procfs
- pstore
- rpc_pipefs
- securityfs
- selinuxfs
- squashfs
- sysfs
- tracefs
match_type: strict
exclude_mount_points:
match_type: regexp
mount_points:
- /dev/*
- /proc/*
- /sys/*
- /run/k3s/containerd/*
- /var/lib/docker/*
- /var/lib/kubelet/*
- /snap/*
load: null
memory: null
network: null配置紅通過 collection_interval 指定了每 10 秒收集一次指標,并使用根路徑 /hostfs 來訪問主機文件系統。
hostmetrics 接收器包括多個抓取器,用于收集不同類型的指標。例如,cpu 抓取器用于收集 CPU 使用率指標,disk 抓取器用于收集磁盤使用率指標,memory 抓取器用于收集內存使用率指標,load 抓取器用于收集 CPU 負載指標。在這個配置文件中,我們只啟用了 filesystem 抓取器,用于收集文件系統使用率指標。
filesystem 抓取器的配置中,指定了要排除某些文件系統類型和掛載點的指標收集。具體來說,它排除了文件系統類型 autofs、binfmt_misc、bpf、cgroup2......,它還排除了掛載點 /dev/*、/proc/*、/sys/*、/run/k3s/containerd/*、/var/lib/docker/*、/var/lib/kubelet/* 和 /snap/*,這些排除操作確保只收集相關的文件系統使用率指標。
kubeletstats 接收器
Kubelet Stats Receiver 用于從 kubelet 上的 API 服務器中獲取指標。通常用于收集與 Kubernetes 工作負載相關的指標,例如 CPU 使用率、內存使用率和網絡流量。這些指標可用于監視 Kubernetes 集群和工作負載的健康狀況和性能。
Kubelet Stats Receiver 默認支持在端口 10250 暴露的安全 Kubelet 端點和在端口 10255 暴露的只讀 Kubelet 端點。如果 auth_type 設置為 none,則將使用只讀端點。如果 auth_type 設置為以下任何值,則將使用安全端點:
- tls 告訴接收方使用 TLS 進行身份驗證,并要求設置 ca_file、key_file 和 cert_file 字段。
- serviceAccount 告訴該接收者使用默認的 ServiceAccount 令牌來向 kubelet API 進行身份驗證。
- kubeConfig 告訴該接收器使用 kubeconfig 文件(KUBECONFIG 環境變量或 ~/.kube/config)進行身份驗證并使用 APIServer 代理來訪問 kubelet API。
- initial_delay(默認 = 1 秒),定義接收器在開始之前等待的時間。
此外還可以指定以下參數:
- collection_interval(默認= 10s),收集數據的時間間隔。
- insecure_skip_verify(默認= false),是否跳過證書驗證。
默認情況下,所有生成的指標都基于 kubelet 的 /stats/summary 端點提供的資源標簽。對于某些場景而言,這可能還不夠。因此,可以利用其他端點來獲取附加的元數據,并將它們設置為指標資源的額外標簽。當前支持的元數據包括以下內容:
- container.id - 使用從通過 /pods 暴露的容器狀態獲取的容器 ID 標簽來增強指標。
- k8s.volume.type - 從通過 /pods 暴露的 Pod 規范收集卷類型,并將其作為卷指標的標簽。如果端點提供的信息不僅僅是卷類型,這些信息也會根據可用字段和卷類型進行同步。例如,aws.volume.id 將從 awsElasticBlockStore 同步,gcp.pd.name 將從 gcePersistentDisk 同步。
如果你希望將 container.id 標簽添加到你的指標中,請使用 extra_metadata_labels 字段來啟用它,例如:
receivers:
kubeletstats:
collection_interval: 10s
auth_type: "serviceAccount"
endpoint: "${env:K8S_NODE_NAME}:10250"
insecure_skip_verify: true
extra_metadata_labels:
- container.id如果沒有設置 extra_metadata_labels,則不會進行額外的 API 調用來獲取額外的元數據。
默認情況下,該收集器將收集來自容器、pod 和節點的指標。我們可以通過設置一個 metric_groups 來指定要收集的數據來源,可以指定的值包括 container、pod、node 和 volume。比如希望僅從接收器收集節點和 Pod 指標,則可以使用以下配置:
receivers:
kubeletstats:
collection_interval: 10s
auth_type: "serviceAccount"
endpoint: "${env:K8S_NODE_NAME}:10250"
insecure_skip_verify: true
metric_groups:
- node
- podK8S_NODE_NAME 環境變量在 Kubernetes 集群里面我們可以通過 Downward API 來注入。
prometheus 接收器
Prometheus 接收器以 Prometheus 格式接收指標數據。該接收器旨在最大限度地成為 Prometheus 的替代品,但是目前不支持下面這些 Prometheus 的高級功能:
- alert_config.alertmanagers
- alert_config.relabel_configs
- remote_read
- remote_write
- rule_files
該接收器是讓 Prometheus 抓取你的服務的直接替代品。它支持 scrape_config 中的全部 Prometheus 配置,包括服務發現。就像在啟動 Prometheus 之前在 YAML 配置文件中寫入一樣,例如:
prometheus --config.file=prom.yaml注意:由于收集器配置支持 env 變量替換,prometheus 配置中的 $ 字符將被解釋為環境變量。如果要在 prometheus 配置中使用 $ 字符,則必須使用 $$ 對其進行轉義。
比如我們可以通過下面的配置來讓收集器接收 Prometheus 的指標數據,使用方法和 Prometheus 一樣,只需要在 scrape_configs 中添加一個任務即可:
receivers:
prometheus:
config:
scrape_configs:
- job_name: opentelemetry-collector
scrape_interval: 10s
static_configs:
- targets:
- ${env:MY_POD_IP}:8888
- job_name: k8s
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
[__meta_kubernetes_pod_annotation_prometheus_io_scrape]
regex: "true"
action: keep
metric_relabel_configs:
- source_labels: [__name__]
regex: "(request_duration_seconds.*|response_duration_seconds.*)"
action: keep我們這里添加的 opentelemetry-collector 任務,是去抓取 8888 端口的數據,而 8888 端口就是 OpenTelemetry Collector 的端口,這個端口我們在 service.telemetry 中已經定義了,這樣我們就可以通過該接收器來抓取 OpenTelemetry Collector 本身的指標數據了。
batch 處理器
批處理器接受追蹤、指標或日志,并將它們分批處理。批處理有助于更好地壓縮數據,并減少傳輸數據所需的外部連接數量。該處理器支持基于大小和時間的批處理。
強烈建議在每個采集器上配置批處理器。批處理器應該在內存限制器(memory_limiter)以及任何其他采樣處理器之后的管道中定義。這是因為批處理應該在任何數據采樣之后再發生。
批處理器中可以配置如下所示的一些參數:
- send_batch_size(默認值=8192):無論超時如何,達到此數量的追蹤、指標數據或日志記錄后,都將立即發送批處理。send_batch_size 起到觸發器的作用,不影響批處理的大小。如果需要強制限制發送到管道中下一個組件的批處理大小,可以配置 send_batch_max_size。
- timeout(默認值=200ms):無論批處理大小如何,在經過一定時間后,將立即發送批處理。如果設置為零,則忽略send_batch_size,因為數據將立即發送,只受 send_batch_max_size 的限制。
- send_batch_max_size(默認值=0):批處理大小的上限。0 表示批處理大小無上限,此屬性確保較大的批處理被拆分為較小的單位。它必須大于或等于 send_batch_size。
- metadata_keys(默認值=空):當設置時,此處理器將為 client.Metadata 中值的每個不同組合創建一個批處理程序實例。
- metadata_cardinality_limit(默認值=1000):當 metadata_keys 不為空時,此設置限制將在進程的生命周期內處理的元數據鍵值的唯一組合的數量。
比如如下配置包含一個默認的批處理器和一個具有自定義設置的第二個批處理器。批處理器 batch/2 將在 10 秒內緩沖最多 10000 個 span、指標數據點或日志記錄,而不會分割數據項以強制執行最大批處理大小。
processors:
batch:
batch/2:
send_batch_size: 10000
timeout: 10s下面的配置將強制執行最大批處理大小限制,即 10000 個 span、指標數據點或日志記錄,而不引入任何人為的延遲。
processors:
batch:
send_batch_max_size: 10000
timeout: 0smemory_limiter 處理器
內存限制處理器用于防止收集器的內存不足情況。考慮到收集器處理的數據的數量和類型是環境特定的,并且收集器的資源利用率也取決于配置的處理器,因此對內存使用情況進行檢查非常重要。
memory_limiter 處理器允許定期檢查內存使用情況,如果超過定義的限制,將開始拒絕數據并強制 GC 減少內存消耗。memory_limiter 使用軟內存限制和硬內存限制,硬限制始終高于或等于軟限制。
內存使用量隨時間變化,硬限制是進程堆分配的最大內存量,超過此限制將觸發內存限制操作。軟限制是內存使用量下降到硬限制以下的閾值,恢復正常操作。
比如定義硬限制 limit_mib 為 100 MiB,軟限制是 80 MiB,那么 spike_limit_mib 則為 20 MiB。當內存使用量超過硬限制時,處理器將拒絕接收數據,并強制執行垃圾收集以嘗試釋放內存。當內存使用量超過軟限制時,處理器將進入內存限制模式,如果內存使用量下降到軟限制以下,則恢復正常操作,數據將不再被拒絕,并且不會執行強制垃圾收集。
在內存限制模式下,處理器返回的錯誤是非永久性錯誤。當接收器方看到此錯誤時,他們會重試發送相同的數據。
強烈建議在每個收集器上配置 ballast 擴展以及 memory_limiter 處理器。ballast 擴展應配置為分配給收集器的內存的 1/3 到 1/2。 memory_limiter 處理器應該是管道中定義的第一個處理器(緊接在接收器之后)。這是為了確保可以將背壓發送到適用的接收器,并在觸發 memory_limiter 時將數據丟失的可能性降到最低。
內存限制器主要的配置選項包括下面這些:
- check_interval(默認 = 0s):用于指定檢查內存使用情況的時間間隔。比如設置為 5s,表示每 5 秒檢查一次內存使用情況。
- limit_mib(默認 = 0):進程堆分配的最大內存量(以 MiB 為單位)。請注意,通常進程的總內存使用量將比該值高出約 50MiB,這定義了硬限制。
- spike_limit_mib(默認 = limit_mib 的 20%):內存使用測量之間預期的最大峰值。該值必須小于 limit_mib。軟限制值將等于 limit_mib - spike_limit_mib。 spike_limit_mib 的建議值約為 limit_mib 的 20%。
- limit_percentage(默認值 = 0):進程堆要分配的最大總內存量。此配置在具有 cgroup 的 Linux 系統上受支持,旨在用于像 docker 這樣的動態平臺。此選項用于根據可用總內存計算內存限制。例如,設置為 75%,總內存為 1GiB,將限制為 750 MiB。固定內存設置 (limit_mib) 優先于百分比配置。
- spike_limit_percentage(默認 = 0):內存使用測量之間預期的最大峰值。該值必須小于 limit_percentage。該選項用于根據總可用內存計算 spike_limit_mib。例如,如果總內存為 1GiB,則設置為 25% 將峰值限制為 250MiB。此選項僅與 limit_percentage 一起使用。
k8sattributes 處理器
Kubernetes 屬性處理器允許使用 K8s 元數據自動設置追蹤、指標和日志資源屬性。當 k8sattributes 處理器被應用于一個 Kubernetes 集群中的 Pod 時,它會從 Pod 的元數據中提取一些屬性,例如 Pod 的名稱、UID、啟動時間等其他元數據。這些屬性將與遙測數據一起發送到后端,以便在分析和調試遙測數據時可以更好地了解它們來自哪個 Pod。
在 k8sattributes 處理器中,pod_association 屬性定義了如何將遙測數據與 Pod 相關聯。例如,如果一個 Pod 發送了多個遙測數據,那么這些遙測數據將被關聯到同一個 Pod 上,以便在后續的分析和調試中可以更好地了解它們來自哪個 Pod。
比如我們這里定義的處理器如下所示:
k8sattributes:
extract:
metadata: # 列出要從k8s中提取的元數據屬性
- k8s.namespace.name
- k8s.deployment.name
- k8s.statefulset.name
- k8s.daemonset.name
- k8s.cronjob.name
- k8s.job.name
- k8s.node.name
- k8s.pod.name
- k8s.pod.uid
- k8s.pod.start_time
filter: # 只有來自與該值匹配的節點的數據將被考慮。
node_from_env_var: K8S_NODE_NAME
passthrough: false # 表示處理器不會傳遞任何不符合過濾條件的數據。
pod_association:
- sources:
- from: resource_attribute # from 表示規則類型
name: k8s.pod.ip
- sources:
- from: resource_attribute # resource_attribute 表示從接收到的資源的屬性列表中查找的屬性名稱
name: k8s.pod.uid
- sources:
- from: connection其中 extract 選項列出要從 Kubernetes 中提取的元數據屬性,我們這里包括命名空間、Deployment、StatefulSet、DaemonSet、CronJob、Job、Node、Pod 名稱、Pod UID 和 Pod 啟動時間。 filter 屬性指定僅考慮名稱與 K8S_NODE_NAME 環境變量的值匹配的節點的數據。passthrough選項設置為 false,這意味著處理器不會傳遞任何不符合過濾條件的數據。
最后,pod_association 選項定義了如何將從 Kubernetes 中提取的 Pod 元數據與遙測數據關聯起來。在這個配置文件中,pod_association 屬性定義了三個關聯源,分別是 k8s.pod.ip、k8s.pod.uid 和 connection。
- 第一個關聯源是 k8s.pod.ip,它使用 Pod IP 作為關聯的來源。這意味著從同一個 Pod IP 發送的所有遙測數據都將與同一個 Pod 關聯起來。
- 第二個關聯源是 k8s.pod.uid,它使用 Pod UID 作為關聯的來源。這意味著從同一個 Pod UID 發送的所有遙測數據都將與同一個 Pod 關聯起來。
- 第三個關聯源是 connection,它使用連接信息作為關聯的來源。這意味著從同一個連接發送的所有遙測數據都將與同一個 Pod 關聯起來。
如果未配置 Pod 關聯規則,則資源僅通過連接的 IP 地址與元數據關聯。
通過這些關聯源,pod_association 屬性可以確保遙測數據與正確的 Pod 相關聯,從而使得在分析和調試遙測數據時更加方便和準確。
要收集的元數據由定義的元數據配置確定,該配置定義了要添加的資源屬性列表。列表中的項與將要添加的資源屬性名稱完全相同。默認情況下添加以下屬性:
- k8s.namespace.name
- k8s.pod.name
- k8s.pod.uid
- k8s.pod.start_time
- k8s.deployment.name
- k8s.node.name
你可以使用 metadata 配置更改此列表。并非所有屬性都能夠被添加。只有來自 metadata 的屬性名稱應該用于 pod_association 的 resource_attribute,空值或不存在的值將會被忽略。
此外 k8sattributesprocessor 還可以通過 pod 和命名空間的標簽和注解來設置資源屬性。
metricstransform 處理器
指標轉換處理器可用于重命名指標,以及添加、重命名或刪除標簽鍵和值。它還可用于跨標簽或標簽值對指標執行縮放和聚合。下表提供了可應用于一個或多個指標的受支持操作的完整列表。
操作 | 示例 (基于指標 system.cpu.usage) |
Rename metrics | 重命名 system.cpu.usage_time |
Add labels | 添加一個新的標簽 identifirer 值為 1 |
Rename label keys | 重命名標簽 state 為 cpu_state |
Rename label values | 對于標簽 state, 將值 idle 重命名為 - |
Delete data points | 刪除標簽為 state=idle 的所有數據點 |
Toggle data type | 從 int 數據點更改為 double 數據點 |
Scale value | 將值乘以 1000,從秒轉換為毫秒。 |
Aggregate across label sets | 僅保留標簽 state,對該標簽具有相同值的所有點求平均值 |
Aggregate across label values | 對于標簽state,將值為 user 或 system 的點求和,并賦給used = user + system。 |
我們這里的添加的配置如下:
metricstransform:
transforms:
action: update
include: .+
match_type: regexp
operations:
- action: add_label
new_label: k8s.cluster.id
new_value: abcd1234
- action: add_label
new_label: k8s.cluster.name
new_value: youdian-k8s表示我們會對所有的指標添加 k8s.cluster.id 和 k8s.cluster.name 兩個標簽。
logging 導出器
日志導出器,用于將數據導出到標準輸出,主要用于調試階段。
prometheus 導出器
Prometheus 導出器,該導出器可以指定一個端點,將從接收器接收到的指標數據通過這個端點進行導出,這樣 Prometheus 只需要從這個端點拉取數據即可。而 prometheusremotewrite 導出器則是將指標數據直接遠程寫入到指定的地址,這個地址是支持 Prometheus 遠程寫入協議的地址。(經測試當前版本遠程寫入的導出器有一定問題)
我們這里的配置如下:
prometheus:
endpoint: 0.0.0.0:9090
metric_expiration: 180m
resource_to_telemetry_conversion:
enabled: true- endpoint:指標將通過路徑 /metrics 暴露的地址,也就是我們想通過上面地址來訪問指標數據,我們這里表示想在 9090 端口來暴露指標數據。
- metric_expiration(默認值= 5m):定義了在沒有更新的情況下暴露的指標的時間長度。
- resource_to_telemetry_conversion(默認為 false):如果啟用為 true,則所有資源屬性將默認轉換為指標標簽。
所以最后我們可以在 Prometheus 中去采集 OpenTelemetry Collector 在 9090 端口暴露的指標數據,只需要創建一個如下所示的 ServiceMonitor 對象即可:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: otel-prom
namespace: kube-otel
labels:
release: prometheus
spec:
endpoints:
- interval: 10s
port: prom # 我們在helm values 中定義了一個 prom 的 Service 端口
path: metrics
selector:
matchLabels:
component: agent-collector
app.kubernetes.io/instance: opentelemetry-collector創建后我們就可以在 Prometheus 中找到 OpenTelemetry Collector 暴露的指標數據了。
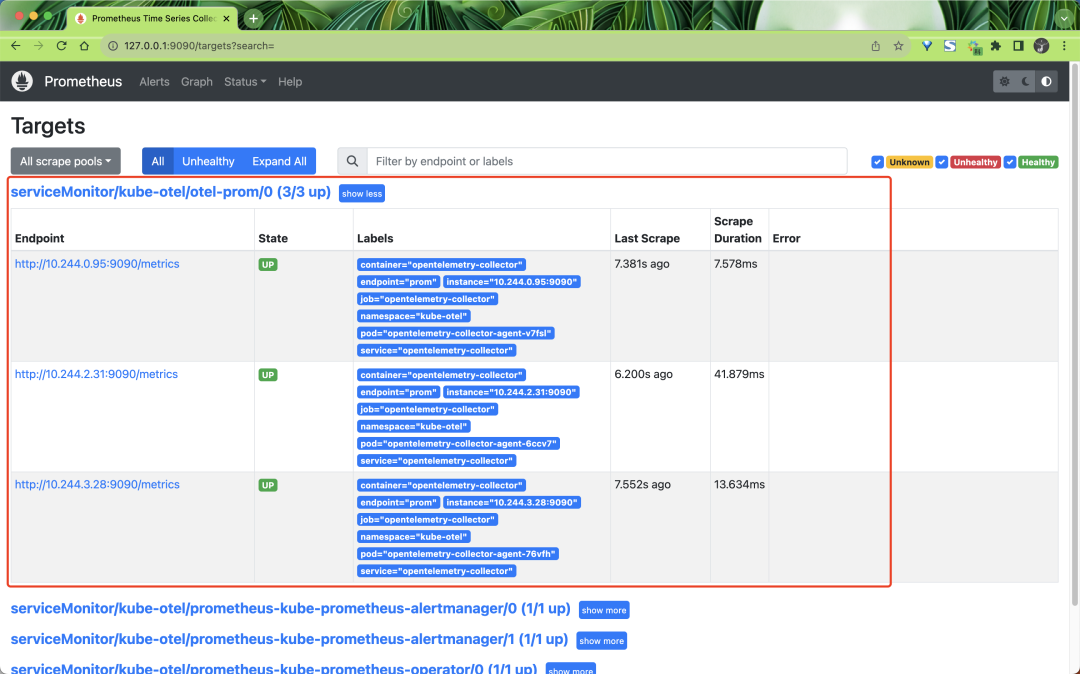
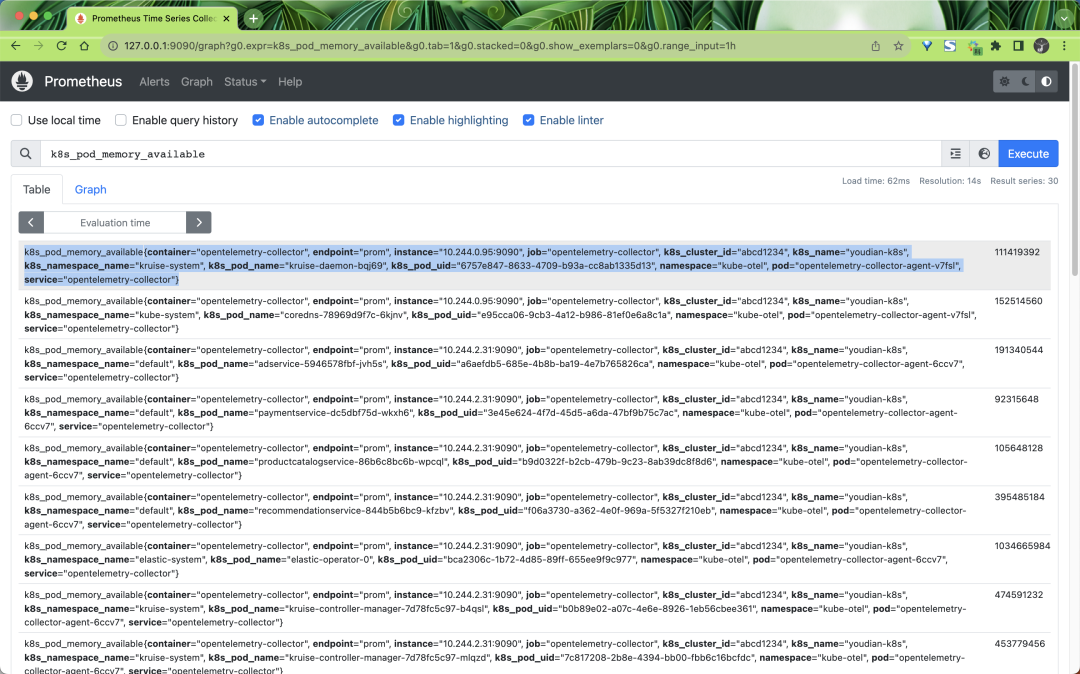
采集到的指標里面包含了很多的標簽,這些標簽都是通過我們前面定義的處理器添加的,比如:
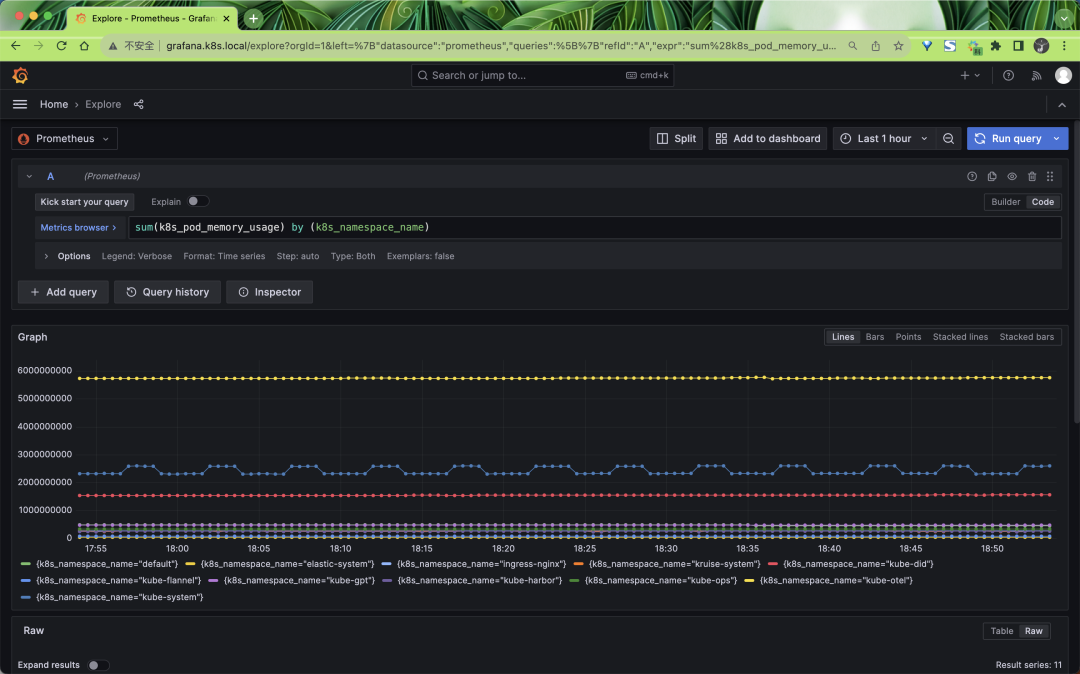
同樣我們也可以通過 Grafana 來查詢這些指標數據:
此外我們還可以部署 OpenTelemetry Collector 的 Deployment 模式來采集其他指標數據。



























