騰訊大數據實時湖倉智能優化實踐

一、湖倉架構
騰訊大數據的湖倉架構如下圖所示:

這里分為三個部分,分別是數據湖計算、數據湖管理和數據湖存儲。
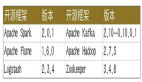
數據湖計算部分,Spark 作為 ETL Batch 任務的主要批處理引擎,Flink 作為準實時計算的流處理引擎,StarRocks 和 Presto 作為即席查詢的 OLAP 引擎。數據湖管理層以 Iceberg 為核心,同時開放了一些簡單的 API,支持用戶通過 SDK 的方式去調用。在 Iceberg 之上構建了一套 Auto Optimize Service 服務,幫助用戶在使用 Iceberg 的過程中實現查詢性能的提升和存儲成本的降低。數據湖底層存儲基于 HDFS 和 COS,COS 是騰訊云的云對象存儲,可以滿足云上用戶的大規模結構化/非結構化存儲需求,在上層計算框架和底層存儲系統之間,也會引入 Alluxio 構建了一個統一的存儲 Cache 層,進行數據緩存提速。本次分享的重點主要是圍繞智能優化服務(Auto Optimize Service)展開。
二、智能優化服務

智能優化服務主要由六個部分組成,分別是:Compaction Service(合并小文件)、Expiration Service(淘汰過期快照)、Cleaning Service(生命周期管理和孤兒文件清理)、Clustering Service(數據重分布)、Index Service(二級索引推薦)和 Auto Engine Service(自動引擎加速)。以下就各模塊近期做的重點工作展開介紹。
1. Compaction Service
(1)小文件合并優化
小文件合并有讀和寫兩個階段,由于 Iceberg 主要以 PARQUET/ORC 列存格式為主,讀寫列存面臨著兩次行列轉換和編解碼,開銷非常大。針對這個痛點,我們對 Parquet 存儲模型進行了分析,主要由 RowGroup、Column Chunk、Page 以及 Footer 組成,相對位置如下圖所示,不同列的最小存儲單元以 Page 級別組織,數據水平方向上以 RowGroup 大小劃分數據塊,以便上層引擎按照 RowGroup 級別分配 task 加載數據。

基于存儲模型的特點,我們針對性地采用了 RowGroup Level 和 Page Level 兩種拷貝優化,對于大文件合并大文件且僅涉及重新壓縮、僅涉及列裁剪的場景,使用 RowGroup Copy;對于小文件合并大文件、不涉及列變化、不涉及 BloomFilter 的場景,使用 Page Copy。

下面是我們內部全部升級優化之后的落地效果,合并時間&資源減少 5 倍多。

(2)更多優化
我們還增強了 Delete Files 合并優化和增量 Rewrite 策略。
在大規模 Update 的場景下,會產生大量的 Delete Files,數據讀取時會頻繁地進行 Delete File Apply Data File 的操作,這個過程是串行的,I/O 開銷巨大。當合并的速度低于 Delete File Apply 的速度,就會因為積攢了大量的 Delete Files 導致合并失敗。針對這個痛點,我們使用 Left Anti Join 拆分出了關聯 Delete File 的 DataFile 和未關聯 Delete File 的 DataFile,然后將兩者進行 Union All。此外還在 Delete File Apply Data File 的過程中使用了 Bloom Index 加速尋找,及時刪除未關聯 Data File 的 Delete File。
增量 Rewrite 優化會通過在 DataFile 中引入 Modify Time 來決策,進行分區級別的增量更新。

2. Index Service
(1)Iceberg Core Framework
Iceberg 較 Hive 增加了 min-max 索引,記錄了 DataFile 所有 column 列的最大值和最小值,在執行引擎計算時可以協助做文件級別的過濾,但是文件級別的索引粒度較粗,在隨機寫數據的時候 min-max 存在交叉,導致索引失效。所以我們在這個基礎之上進一步拓展了二級索引,來提高 Data Skipping 的能力,加速查詢。索引的構建和加載過程在 Iceberg Core 層的框架支持實現如下:

(2)Iceberg scan metrics
對于專注于業務開發的用戶來說,索引的選擇往往是比較困難的,如何精準的判斷是不是需要索引,需要什么索引,索引是否有效,索引是否會帶來副作用等,往往需要經過一些額外的任務來進行分析,如果靠用戶自己的決策選擇,獲得大規模的適配收益很難。基于這個想法,我們做了智能推薦索引的支持,而智能的推薦,首先是需要一套 metrics 框架的支持,能夠記錄表的 Scan,Filter 等各種事件,收集 Partition Status 信息,然后對這些事件進行分析,統計列的查詢頻次,過濾條件,根據規則區分高/低基數列等。最后根據分析結果,進行 Index 的推薦。

(3)索引智能推薦流程
整個端到端的 Index Service 流程如下圖:1)首先是 SQL 提取,由于我們獲取到的 SQL 是引擎優化后的,并不是原始 SQL,所以需要進行 SQL 重構。2)是索引粗篩,根據拿到的信息,比如列和分區的查詢頻度,初步判斷怎么建立索引是有效的。3)開始嘗試構建索引,支持構建分區級別增量索引。4)在用戶無感知的情況下進行任務雙跑。5)根據雙跑結果進行索引優化的效果評估。6)將索引優化數據輸出給用戶,推薦用戶使用。7)由于索引構建是復雜的,一個表會被多任務引用,一個任務也會去訪問多張表,我們提供任務級別和表級別的索引構建,盡可能實現表級和任務級的同步優化。

3. Clustering Service
由于 Iceberg 的 min-max 索引在隨機寫的情況下是普遍失效的,導致 Data Skipping 能力較差,所以如果需要精確覆蓋 min-max,可以將數據進行重排分布。當用戶進行單列查詢的時候,提前對數據列排序寫入,如果是多列查詢的情況,由于無法保證多個列都分布在一個文件中,我們使用 Z-order,對每個列進行數字化處理,采樣計算 Range-ID,生成交錯位Z-Value,根據 Z-Value 進行重分區,可以保證不同列之間的相對有序性。

實際業務中,Data Clustering 和 Data Skipping 都實現了四倍以上的效果提升。

4. AutoEngine Service
相對于 OLAP 引擎來講,Iceberg 表,Hudi 表都是外表,這些外表基本都是 TB 級別,使用 StarRocks,Doris 查詢外表并不能發揮 OLAP 的查詢優勢。AutoEngine Service 通過收集 OLAP 引擎的 Event Message,對相應的分區進行加熱,也就是將相關分區數據路由到 StarRocks 集群,上層引擎可以在 StarRocks 集群中發現該分區的元數據,由此實現基于存儲計算引擎的選擇優化。

三、場景化能力
1. 多流拼接
關于多流拼接,這里舉個例子簡單說明, 如圖所示,有兩個 MQ 同時往下游寫數據,MQ1 更新列 data1,MQ2 更新列 data2,最終根據 id 聚合,取時間戳 orderColumn 排序最靠前的一條,作為 join 之后的 source。要實現這個合并更新能力,往往需要外接各種臨時存儲 Redis/Hbase/MQ 等組件。

那在 Iceberg 層面是怎么優化的呢?由于 Iceberg 本身支持事務和列級的更新刪除操作,類似于代碼倉庫的 Branch 概念,因此可以通過打 tag 的方式去標記狀態。具體實現是,初始化階段,數據寫入主流程,同時多流往其他 Merged Branch 去寫入,寫完之后的話會有一個異步的 Compaction 任務,定期和主流程合并,當用戶在讀的時候,直接讀取 Merged Branch。

2. 主鍵表
通過多流 Join 的實現方法依賴 Compaction Service 的調度性能,當數據規模不斷增加,多流 join 聚合計算更新的拼接方式可能存在性能瓶頸,所以我們也引入主鍵表作為行級更新的另一種實現方式。比如這里我們根據 id 分成四個桶,存在多個任務往一個桶去寫數據,一個桶內的數據是有序的,那么下游在讀取桶數據的時候會更輕松。但是當 id 的基數很大的時候,比如當 id 為 4/8/16 的時候,都會往一個桶內寫數,會產生 DataFile 的重疊,在下游從桶內讀數的時候,就需要合并一個桶內的多個 DataFile 到一個 Reader 處理。如果分桶數量設置的不合適,單點壓力就會過大,此時可以使用 Rescale 實現桶的彈性擴縮容。另外在桶的基礎上擴展列族 Column Family 的概念,相當于每個列都作為獨立的文件寫入,多個 Column Family 行拼接 Full Outer Join 即可。

3. In Place 遷移
由于對數據湖的高階特性能力的需要,很多業務做了架構的升級,同時也面臨著存量 Thive(騰訊自研 Hive)和 Hive 的數據遷移到 Iceberg。這里需要重點支持的工作包括:存儲數據的遷移,計算任務的遷移。

首先存儲數據的遷移,我們提供了 data in-place 的方案,不搬移原來的 data files,僅僅重新生成 Iceberg 新表所需的 metadata 即可,遷移的過程支持了 STRICT/APPEND/OVERWRITE 等三種模式。
其次是計算任務的遷移支持, 我們改進支持了新的 Name Mapping 機制,增強支持了 Identity partition pruning 能力,使得對于場景的 built-in functions 裁剪能力取得數量級性能提升,優化實現如下:

4. PyIceberg
Iceberg Table Spec 是開發性的實現,可以支持多種語言 API 接入,AI生態圈數據科學等主要以 Python 環境為主,要求高性能 Native 解碼,對 JVM 環境無強依賴,PySpark 雖然具備接入 Iceberg 的能力,但是太重了。我們可以直接利用 PyIceberg 能力,無JVM 依賴,加載解碼一次即可,提供廣泛的機器學習類庫的優勢,拓展 Python的技術棧到 Iceberg 元數據層面,構造 Pandas,Tensorflow,Pytorch 等不同的 DataFrame,方便進行數據分析和 AI 模型訓練的編程探索,我們內部也深度支持了 PyIceberg SQL 的列裁剪和謂詞下推能力,結合 DuckDB 做一些小數據集的算法快速調試。

四、總結和展望
未來還將從以下方面著手,進行實時湖倉的優化:

1. Auto Optimize Service
- 冷熱分離降本提效
- 物化視圖提速
- AE 服務智能化感知
- Compaction 能力打磨
- 更多 Transform UDF Partition Pruning 優化
2. 主鍵表優化
拓展 Deletion Vector,解決謂詞下推必須聯合去重的性能問題
3. AI 探索
- 落地適合模型訓練的湖倉格式。
- 探索實現分布式 dataFrame,整合 metadata 和引擎。