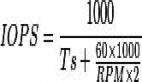存儲系統性能 - 帶寬計算
遇到過很多同行、客戶問我:“xxx存儲系統究竟***支持多少【IOPS】?”,這真不好說,因為手里確實沒有測試數據。更何況,IOPS與i/o size、random/sequential、read/write ratio、App threading-model、response time baseline等諸多因素相關,這些因素組合起來便可以描述一種類型的I/O,我們稱之為【I/O profile】。不同的因素組合得到的IOPS都不一樣,通常我們看到的【標稱IOPS】都是在某一個固定組合下測得的,拿到你自己的生產環境中,未必能達到標稱值。這也是為什么要做前期的performance analysis/sizing的緣故。
直到有人這樣問我:“xxx存儲系統究竟***支持多少【帶寬】?"我愣了下,仔細想想,硬件性能極限就擺在那,基于bandwidth = Frequency * bit-width,而且很多需要的數據都是公開的,東拼西湊應該可以算出個大概。
我并不是Performance專家,從未做過Performance Consulting/Sizing方面的工作,最多也只是做過性能方面的分析/排錯,所以這篇文章的準確性多半存在不靠譜的地方,讀者斟酌著看吧。
在讀文章之前,建議先看一下如下計算公式和名詞。
計算公式:
- Real-world result = nominal * 70% -> 我所標稱的數據都是*70%以盡可能接近實際數據,但如果另外提供了由資料獲得的更為準確的數據,則以其為準。
- Bandwidth = frequency * bit-width
QPI帶寬:假設QPI頻率==2.8 Ghz
× 2 bits/Hz (double data rate)
× 20 (QPI link width)
× (64/80) (data bits/flit bits)
× 2 (unidirectional send and receive operating simultaneously)
÷ 8 (bits/byte)
= 22.4 GB/s
術語:
- Westmere -> Intel CPU微架構的名稱
- GB/s -> 每秒傳輸的byte數量
- Gb/s -> 每秒傳輸的bit數量
- GHz -> 依據具體操作而言,可以是單位時間內運算的次數、單位時間內傳輸的次數 (也可以是GT/s)
- 1byte = 8bits
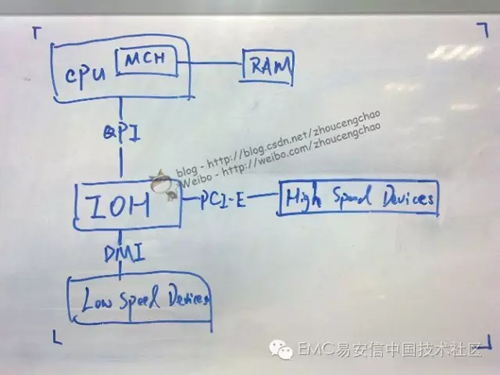
- IOH -> I/O Hub,處于傳統北橋的位置,是一顆橋接芯片。
- QPI -> QuickPathInterconnect,Intel前端總線(FSB)的替代者,可以認為是AMD Hypertransport的競爭對手
- MCH -> Memory Controller Hub,內置于CPU中的內存控制器,與CPU直接通信,無需走系統總線
- PCI Express(Peripheral Component InteconnectExpress, PCIe) - 一種計算機擴展總線(Expansion bus),實現外圍設備與計算機系統內部硬件(包括CPU和RAM)之間的數據傳輸。
- Overprovisioning - 比如 48*1Gbps access port交換機,通常只有4*1Gbps uplink,那么overprovisioning比 = 12:1
- PCI-E 2.0每條lane的理論帶寬是500MB/s
- X58 – 相當于傳統的北橋,只不過不再帶有內存控制器,Code name = Tylersburg
- Lane - 一條lane由一對發送/接收差分線(differential line)組成,共4根線,全雙工雙向字節傳輸。一個PCIe slot可以有1-32條lane,以x前綴標識,通常***是x16。
- Interconnect - PCIe設備通過一條邏輯連接(interconnect)進行通信,該連接也稱為Link。兩個PCIe設備之間的link是一條點到點的通道,用于收發PCI請求。從物理層面看,一個link由一條或多條Lane組成。低速設備使用single-lane link,高速設備使用更寬的16-lane link。
相關術語:
- address/data/control line
- 資源共享 ->資源仲裁
- 時鐘方案(Clock Scheme)
- Serial Bus
PCI-E Capacity:
Per lane (each direction):
- v1.x: 250 MB/s (2.5 GT/s)
- v2.x: 500 MB/s (5 GT/s)
- v3.0: 1 GB/s (8 GT/s)
- v4.0: 2 GB/s (16 GT/s)
16 lane slot (each direction):
- v1.x: 4 GB/s (40 GT/s)
- v2.x: 8 GB/s (80 GT/s)
- v3.0: 16 GB/s (128 GT/s)
性能是【端到端】的,中間任何一個環節都有自己的性能極限,它并不像一根均勻水管,端到端性能一致。存儲系統顯然是不均衡的 ->overprovisioning。我將以中端存儲系統為例,高端存儲過于復雜,硬件結構可能都是私有的,而中端系統相對簡單,就以一種雙控制器、SAS后端、x86架構的存儲系統為例。為了方便名稱引用,我們就稱他為Mr.Block_SAN吧。
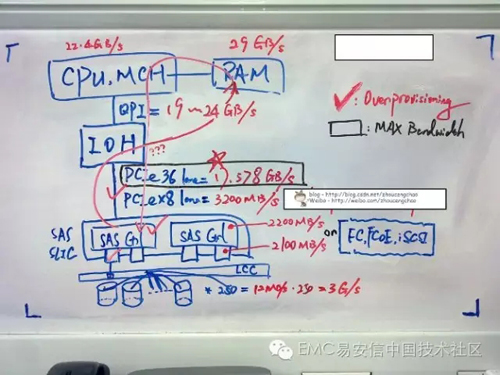
控制器上看得見摸得著,又可以讓我們算一算的東西也就是CPU、內存、I/O模塊,不過我今天會帶上一些極為重要但卻容易忽略的組件。先上一張簡圖(字難看了點,見諒),這是極為簡化的計算機系統構成,許多中端存儲控制器也就這么回事兒。
CPU - 假設控制器采用Intel Xeon-5600系列處理器(Westmere Microarchiecture ),例如Xeon 5660,支持DDR3-1333。CPU Bandwidth = 2.8GHz * 64bits / 8 =22.4 GB/s。
內存 – Mr.Block_SAN系統通過DMA (Direct Memory Access) 直接在Front End,內存以及Back end之間傳輸數據。因此需要知道內存是否提供了足夠的帶寬。3* DDR3,1333MHz帶寬==29GB/s(通常內存帶寬都是足夠的),那么bit width應該是64bits。Westmere集成了內存控制器,因此極大的降低了CPU與內存通信的延遲。Mr.Block_SAN采用【X58 IOH】替代原始的北橋芯片,X58 chipset提供36 lane PCIe2.0 = 17.578GB/s bandwidth(后面會有更多解釋)。
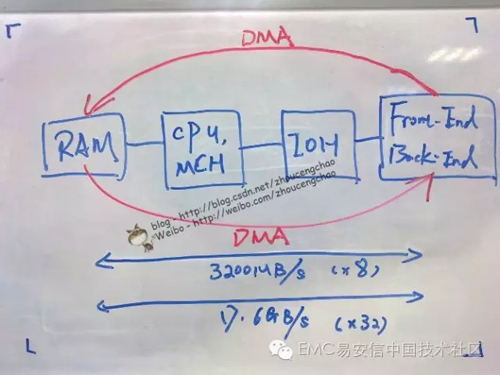
I/O模塊 (SLIC)- SLIC是很多人關心的,因為它直接收/發送I/O。需要注意的是一個SLIC所能提供的帶寬并不等于其所有端口帶寬之和,還要看控制芯片和總線帶寬。以SAS SLIC為例,一個SAS SLIC可能由兩個SAS Controller組成,假設每個SAS Controller帶寬大約2200MB/s realworld,一個SAS port = 4 * 6Gbps /8 * 70% =2100MB/s;一個SAS Controller控制2*SAS port,可見單個SAS Controller無法處理兩個同時滿負荷運轉的SAS port(2200MB/s < 4200MB/s),這里SAS Controller是個瓶頸-> Overprovisioning!整個SAS SLIC又是通過【x8 PCI-E 2.0】 外圍總線與【IOH】連接。x8 PCIe bandwidth = 8 * 500MB/s * 70% = 2800MB/s。如果兩個SAS Controller滿負荷運作的話,即4400MB/s > 2800MB/s,此時x8 PCIe總線是個瓶頸 -> Overprovisioning!
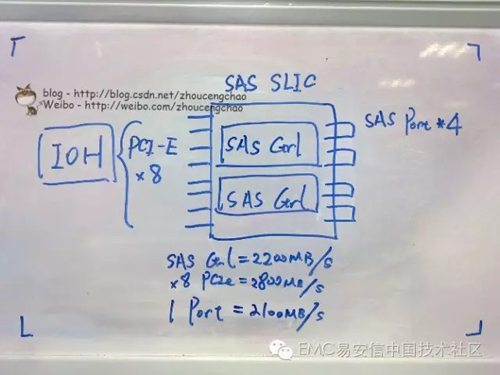
其實還可以計算后端磁盤的帶寬和,假設一個Bus最多能連250塊盤,若是SAS 15K RPM則提供大約12MB/s的帶寬(非順序隨機64KB,讀寫未知),12 * 250 = 3000MB/s > 2100MB/s -> Overprovisioning!
Tip:一個SAS Controller控制兩個SAS Port,所以如果只需要用到兩根bus,可以錯開連接端口,從而使的得兩個SAS Controller都能得到利用。
同理,對任何類型的SLIC,只要能夠獲得其端口速率、控制器帶寬、PCIe帶寬,即可知道瓶頸的位置。我選擇算后端帶寬的原因在于,前端你可以把容量設計的很大,但問題是流量過來【后端】能否吃下來?Cache Full導致的Flush后端能否擋住?對后端帶寬是個考驗,所以以SAS為例或許可以讓讀者聯想到更多。
PCI-Express – PCIe是著名的外圍設備總線,用于連接高帶寬設備與CPU通信,比如存儲系統的I/O模塊。X58提供了36 lane PCIe 2.0,因此36*500/1024 = 17.578125GB/s帶寬。
QPI & IOH – QPI通道帶寬可以通過計算公式獲得,我從手中資料直接獲得的結果是19-24GB/s(運行在不同頻率下的值)。IOH芯片總線頻率是12.8GB/s (List of Intel chipsets這里獲得,但不確定總線頻率是否就是指IOH本身的運行頻率)< 17.578GB/s(36 Lane) -> Overprovisioning!
OK,算完了,能回答Mr.Block_SAN***能提供多少帶寬了嗎?看下來CPU、RAM、QPI的帶寬都上20GB/s,留給前后端的PCIe總線總共也只有18GB/s不到,即便這樣也已經overload了IOH(12GB/s)。所以看來整個系統的瓶頸在IOH,只有12GB/s。當然,你還得算一下Mr.Block_SAN是否支持足夠多的外圍設備(eg. I/O模塊)來完全填充這12GB/s,如果本身就不支持那么多外圍設備,那IOH也算不上是瓶頸了。另外,我看到已經有網友提出我的計算存在8b/10b編碼換算錯誤,由于個人對硬件系統編碼尚未透徹研究,理解這部分的讀者可以自己對相應組件再乘以80%(我記得應該是)去掉編碼轉換的開銷。
這篇文章更多的是一種舉例式的說明,其中的數字和組件存在假設的情況。大家在計算的時候,可以參考這個思路將自己系統的參數和組件套用上去,從而計算出自己系統的帶寬瓶頸。
注意下圖有點舊了,我把PCIe 36 Lane框成了MAX Bandwidth,因為那個時候以為IOH應該有足夠的帶寬,但后來發現可能不是這樣,但圖已經被我擦了,所以就不改了。