













如何在英特爾? 平臺(tái)上實(shí)現(xiàn)高效的大語言模型訓(xùn)練后量化
作者:英特爾公司 陸彤、何欣、郭恒、程文華、王暢、王夢(mèng)妮、沈海豪
本文介紹了可提升大語言模型的訓(xùn)練后量化表現(xiàn)的增強(qiáng)型 SmoothQuant 技術(shù),說明了這項(xiàng)技術(shù)的用法,并證明了其在準(zhǔn)確率方面的優(yōu)勢(shì)。此方法已整合至英特爾? Neural Compressor(1) 中。英特爾? Neural Compressor 是一個(gè)包含量化、剪枝(稀疏性)、蒸餾(知識(shí)提煉)和神經(jīng)架構(gòu)搜索等多種常用模型壓縮技術(shù)的開源 Python 庫。目前,諸如 TensorFlow、英特爾? Extension for TensorFlow(2) 、PyTorch、英特爾? Extension for PyTorch(3) 、ONNX Runtime 和 MXNet等主流框架,都能與之兼容。
英特爾? Neural Compressor 已經(jīng)支持多款英特爾? 架構(gòu)的硬件,比如英特爾? 至強(qiáng)? 可擴(kuò)展處理器(4) 、英特爾? 至強(qiáng)? CPU Max 系列(5) 、英特爾? 數(shù)據(jù)中心 GPU Flex 系列(6) 和英特爾? 數(shù)據(jù)中心 GPU Max 系列(7) 。本文涉及的實(shí)驗(yàn)基于第四代英特? 至強(qiáng)? 可擴(kuò)展處理器(8) 進(jìn)行。
大語言模型
大語言模型 (Large Language Model, LLM) 需基于海量數(shù)據(jù)集進(jìn)行訓(xùn)練,可能擁有數(shù)十億權(quán)重參數(shù)。其先進(jìn)的網(wǎng)絡(luò)結(jié)構(gòu)和龐大的參數(shù)量,使它們能夠很好地應(yīng)對(duì)自然語言本身的復(fù)雜性。完成訓(xùn)練后的大語言模型,可針對(duì)各種下游的自然語言處理 (NLP) 和自然語言生成 (NLG) 任務(wù)進(jìn)行調(diào)優(yōu),讓其更適合對(duì)話式聊天機(jī)器人(如 ChatGPT)、機(jī)器翻譯、文本分類、欺詐檢測(cè)和情感分析等任務(wù)場景。
大語言模型部署面臨的挑戰(zhàn)
大語言模型在執(zhí)行自然語言處理和自然語言生成任務(wù)方面表現(xiàn)出色,但其訓(xùn)練和部署頗為復(fù)雜,主要面臨以下挑戰(zhàn):
- AI 與內(nèi)存墻(9) 瓶頸問題:算力每兩年提高 3.1 倍,內(nèi)存帶寬卻只提高 1.4 倍;
- 網(wǎng)絡(luò)帶寬挑戰(zhàn):訓(xùn)練大語言模型需要采用分布式系統(tǒng),這對(duì)網(wǎng)絡(luò)帶寬提出了較高要求;
- 系統(tǒng)資源有限:訓(xùn)練后的模型往往會(huì)部署在算力和內(nèi)存資源均有限的系統(tǒng)上。
因此,采用訓(xùn)練后量化的方法來為大語言模型瘦身,對(duì)于實(shí)現(xiàn)低時(shí)延推理至關(guān)重要。
大語言模型的量化
量化是一種常見的壓縮操作,可以減少模型占用的內(nèi)存空間,提高推理性能。采用量化方法可以降低大語言模型部署的難度。具體來說,量化是將浮點(diǎn)矩陣轉(zhuǎn)換為整數(shù)矩陣:
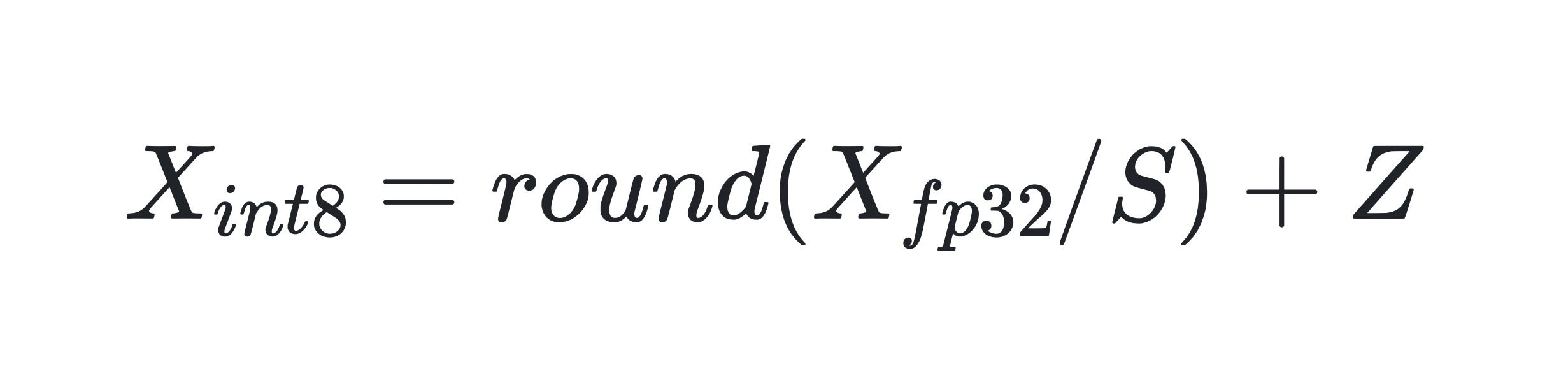
其中 X_fp32、S 和 Z 分別為輸入矩陣、比例因子和整數(shù)零點(diǎn)。
有關(guān)每通道 (per-channel) 量化策略雖然可能會(huì)減少量化損失,但不能用于激活值量化的原因,請(qǐng)參看 SmoothQuant 相關(guān)文檔(10) 。不過,激活值量化誤差損失卻是導(dǎo)致模型量化準(zhǔn)確率下降的重要因素。為此,人們提出了很多方法來降低激活值量化損失,例如:SPIQ(11) 、Outlier Suppression(12) 和SmoothQuant(13) 。這三種方法思路相似,即把激活值量化的難度轉(zhuǎn)移到權(quán)重量化上,只是三者在轉(zhuǎn)移難度的多少上有所不同。
增強(qiáng)型 SmoothQuant
SmoothQuant 引入了一個(gè)超參數(shù) α 作為平滑因子來計(jì)算每個(gè)通道的量化比例因子,并平衡激活值和權(quán)重的量化難度。
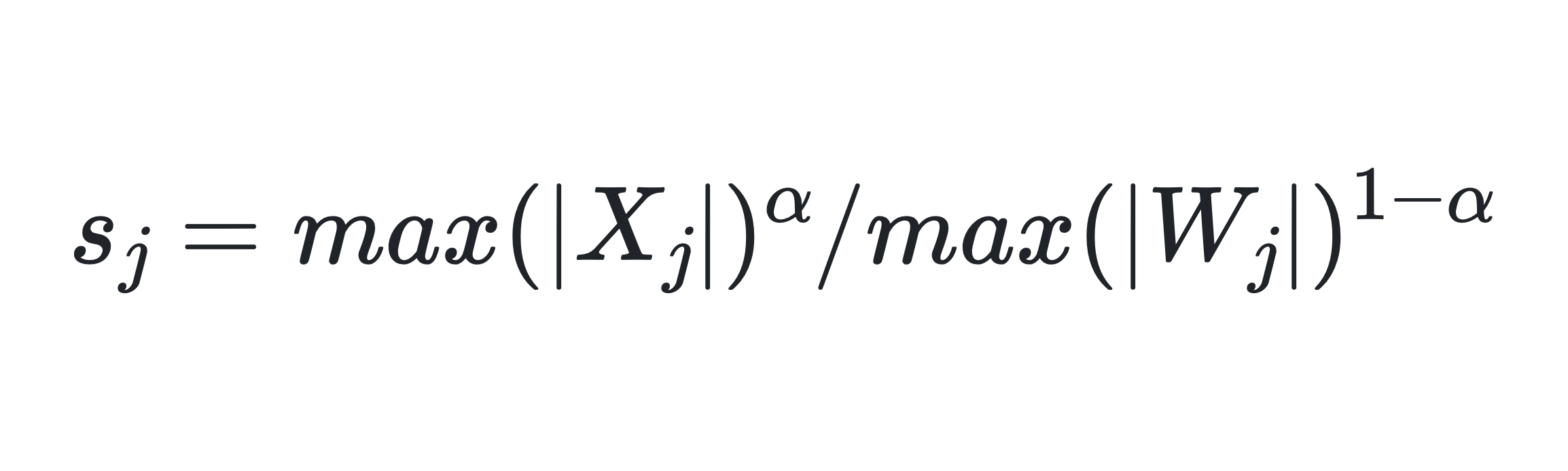
其中 j 是輸入通道索引。
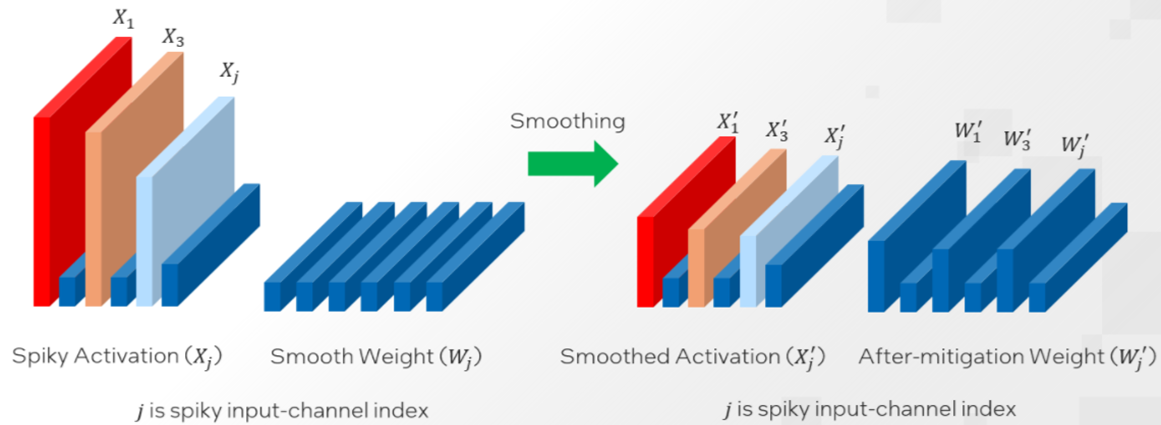
對(duì)于OPT 和 BLOOM 等大多數(shù)模型來說,α=0.5 是一個(gè)能夠較好實(shí)現(xiàn)權(quán)重和激活值量化難度分割的平衡值。模型的激活異常值越大,就越需要使用更大的 α 值來將更多的量化難度轉(zhuǎn)移到權(quán)重上。
原始的 SmoothQuant 旨在通過針對(duì)整個(gè)模型使用一個(gè)固定值 α 來分割權(quán)重和激活值的量化難度。然而,由于激活異常值的分布不僅在不同模型之間存在差異,而且在同一模型的不同層之間也不盡相同,因此,本文推薦使用英特爾? Neural Compressor 的自動(dòng)調(diào)優(yōu)能力,逐層獲取最佳 α 值。
相關(guān)方法包括以下五個(gè)主要步驟(偽代碼如下所示):
- 通過特殊的回調(diào)函數(shù) register_forward_hook 捕獲 (hook) 模型各層的輸入和輸出值。
- 根據(jù)用戶定義的 α 范圍和步長生成一個(gè) α 值列表。
- 根據(jù)給定的 α 值重新計(jì)算平滑因子并調(diào)整參數(shù)(權(quán)重值和激活值)。
- 對(duì)權(quán)重執(zhí)行每通道量化與反量化 (quantization_dequantization),對(duì)輸入值執(zhí)行每張量 (per-tensor) 量化與反量化,以預(yù)測(cè)與給定 α 值對(duì)應(yīng)的每層輸出值。
- 計(jì)算相對(duì)實(shí)際輸出值的均方損失,將調(diào)整后的參數(shù)恢復(fù)回來,并保存每層的最佳 α 值。

本文提出的方法支持用多個(gè)標(biāo)準(zhǔn)(如最小值、最大值和平均值)來確定 Transformer 塊的輸入層歸一化 (LayerNorm) 操作的 α 值。實(shí)驗(yàn)發(fā)現(xiàn),將 α 范圍設(shè)為 [0.3, 0.7],步長設(shè)為 0.05,對(duì)大多數(shù)模型來說都能達(dá)到很好的平衡。
這一方法有兩個(gè)顯著特點(diǎn):一是全自動(dòng)化,二是比原始方法支持的融合模式多。
下圖提供了在 BLOOM-1b7 模型上執(zhí)行 SmoothQuant α 值自動(dòng)調(diào)優(yōu)的樣例代碼:
型 SmoothQuant 的樣例代碼") 啟用增強(qiáng)型 SmoothQuant 的樣例代碼
啟用增強(qiáng)型 SmoothQuant 的樣例代碼
用戶只需傳遞一個(gè)模型名稱 (model_name) 和一個(gè)數(shù)據(jù)加載器。值得注意的是,模型分析主要依靠的是 Torch JIT。用戶可以在加載 Hugging Face 模型(14) 時(shí)將 torchscript 設(shè)置為 True,或?qū)?return_dict 設(shè)置為 False。更多信息請(qǐng)參閱英特爾? Neural Compressor 文檔(10) 。
結(jié)果
本文提出的增強(qiáng)型 SmoothQuant 的主要優(yōu)勢(shì)在于提高了準(zhǔn)確率。
經(jīng)過對(duì)多種主流大語言模型的評(píng)估,具備自動(dòng)調(diào)優(yōu)能力的 INT8 SmoothQuant 最后一個(gè)詞元 (last-token) 的預(yù)測(cè)準(zhǔn)確率要高于原始 INT8 SmoothQuant 和 FP32 基線方法。詳見下圖:

FP32 基線方法、INT8(啟用和不啟用 SmoothQuant)以及 INT8(啟用本文提出的增強(qiáng)型 SmoothQuant)的準(zhǔn)確率對(duì)比
從上圖可以看出,在 OPT-1.3b 和 BLOOM-1b7 模型上,本文提出的增強(qiáng)型 SmoothQuant 的準(zhǔn)確率比默認(rèn)的 SmoothQuant 分別高 5.4% 和 1.6%。量化后的模型也縮小到 FP32 模型的四分之一,大大減少了內(nèi)存占用空間,從而有效地提升大模型在英特爾? 平臺(tái)上的推理性能。
更全面的結(jié)果請(qǐng)見GitHub 存儲(chǔ)庫(10) 。同時(shí),也歡迎您創(chuàng)建拉取請(qǐng)求或就GitHub 問題(15) 發(fā)表評(píng)論。期待聽到您的反饋意見和建議。
作者:
英特爾公司人工智能資深架構(gòu)師沈海豪、英特爾公司人工智能資深軟件工程師程文華、英特爾公司人工智能軟件工程師陸彤、何欣、郭恒、王暢、王夢(mèng)妮,他們都在從事模型量化及壓縮的研究與優(yōu)化工作。
注釋:
1、英特爾? Neural Compressor
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/neural-compressor.html
2、英特爾? Extension for TensorFlow
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/optimization-for-tensorflow.html
3、英特爾? Extension for PyTorch
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/optimization-for-pytorch.html
4、英特爾? 至強(qiáng)? 可擴(kuò)展處理器
https://www.intel.cn/content/www/cn/zh/products/details/processors/xeon/scalable.html
5、英特爾? 至強(qiáng)? CPU Max 系列
https://www.intel.cn/content/www/cn/zh/products/details/processors/xeon/max-series.html
6、英特爾? 數(shù)據(jù)中心 GPU Flex 系列
https://www.intel.cn/content/www/cn/zh/products/details/discrete-gpus/data-center-gpu/flex-series.html
7、英特爾? 數(shù)據(jù)中心 GPU Max 系列
https://www.intel.com/content/www/us/en/products/details/discrete-gpus/data-center-gpu/max-series.html
8、第四代英特? 至強(qiáng)? 可擴(kuò)展處理器
https://www.intel.cn/content/www/cn/zh/events/accelerate-with-xeon.html
9、AI 與內(nèi)存墻
https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
10、SmoothQuant 相關(guān)文檔 / 英特爾? Neural Compressor 文檔 / GitHub 存儲(chǔ)庫
https://github.com/intel/neural-compressor/blob/master/docs/source/smooth_quant.md
11、SPIQ
https://arxiv.org/abs/2203.14642
12、Outlier Suppression
https://arxiv.org/abs/2209.13325
13、 SmoothQuant
https://arxiv.org/abs/2211.10438
14、Hugging Face 模型
https://huggingface.co/models
15、GitHub 問題
https://github.com/intel/neural-compressor/issues
















