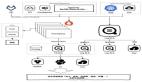
數據可觀察性 VS 數據質量
譯文隨著企業從越來越多的信息源收集到了無窮無盡的數據流,他們開始積累一個由數據存儲、潛在終端用戶和信息管道組成的生態系統。隨著生態系統愈加復雜,數據停機,以及數據部分、錯誤、缺失或其他不準確的時刻,都會成倍增加。因此,數據團隊把大部分時間花在了數據質量問題上,而不是花在了為企業創收的工作上。

數據可觀察性可以被定義為整體視圖,包括監測、跟蹤和分流事件以防止系統停機。同時,數據質量是對如何適應數據集以滿足企業的特定需求的衡量。
它們在哪里重疊?
數據可觀察性是用來提高數據質量的。當組織采用數據可觀察性來提高數據質量時,必然會有很大的效果。其中一些包括:
1、在影響用戶體驗前發現數據異常,從而節約企業成本。當異常發生時,數據可觀察性引擎會立即提醒團隊,從而使企業有時間和機會在問題影響到消費者之前進行調查和排除故障。由于數據工程團隊在問題涉及利益相關者之前就得到了通知,他們可以及時修復數據管道,避免未來的異常情況危及數據完整性。
2、通過追蹤字段級線狀數據的可觀察性來改善合作,有助于理解它們之間的依賴關系。
3、通過掌握被廢棄的數據集來提高生產力,數據可觀察性使關鍵數據資產的相關性和使用模式更加透明,在不同屬性被廢棄時通知他們。
4、通過減少解決令人厭煩的數據消防演習的時間來促進成本節約,并重新獲得對關鍵決策數據的信任。
5、更好的協調數據工程和數據分析師團隊之間的關系,有助于理解數據資產之間的關鍵依賴關系。
6、通過增加對數據資產的健康狀況、使用模式和相關性的端到端可視性,推動更高的效率和生產力。
由此,可以得出結論,數據可觀察性和數據質量依賴企業的良好運作。盡管有區別,但兩者在各種方面都有重疊,有助于提高數據質量,更好的交付產品。
原文標題:Data observability vs data quality
原文作者:Vanitha