谷歌DeepMind構建“早期預警系統” 推進AI治理,確保AI目標與人類一致

DeepMind警告稱,AI模型可能具有獲取武器和發動網絡攻擊的能力
總部位于英國的DeepMind一直活躍在AI研究的前沿,是全球少數幾家致力于開發達到人類水平的通用AI公司之一,最近與母公司谷歌進行了更緊密的整合。
DeepMind的研究團隊與來自學術界,以及OpenAI和Anthropic等其他主要AI開發商的研究人員合作,開發了這一新的威脅檢測系統。
DeepMind工程師在一篇關于新框架的技術博客中宣稱,“為了負責任地走在AI研究的前沿,我們必須盡早識別AI系統中的新功能和新風險。”
如今已經有了一些評估工具,可以根據特定的風險檢查功能強大的通用模型。這些工具在AI系統向公眾廣泛提供之前識別出其存在的一些不必要的行為,包括尋找誤導性陳述,有偏見的決定或復制版權保護的內容。
這些問題來自于越來越高級的大模型,它們的能力超出了簡單的內容生成,而包括在操縱、欺騙、網絡攻擊或其他危險能力方面的強大技能。新框架被描述為可用于減輕這些風險的“早期預警系統”。
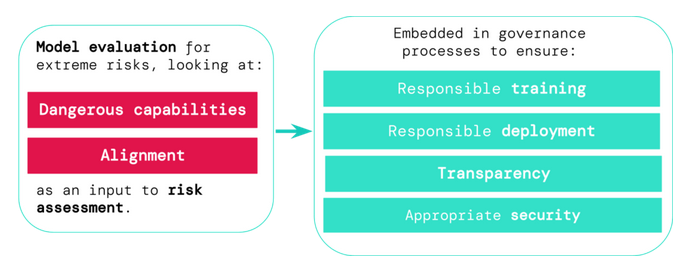
DeepMind的研究人員表示,評估結果可以嵌入到治理中以降低風險
DeepMind的研究人員表示,負責任的AI開發人員需要解決或規避當前的風險,并預測未來可能出現的風險,因為大型語言模型越來越擅長獨立思考。他們在報告中寫道,“在持續進步之后,未來的通用模型可能會默認學習各種危險的能力。”
雖然對這一風險并不確定,但該團隊表示,未來的AI系統與人類的利益不太一致,可能會實施攻擊性的行為,在對話中巧妙地欺騙人類,操縱人類實施有害的行動,設計或獲取武器,微調和操作云計算平臺上的其他高風險AI系統。
AI還可以幫助人類執行這些任務,增加恐怖分子獲取他們以前無法獲取的數據和內容的風險。DeepMind的開發團隊在博客中寫道,“模型評估可以幫助我們提前識別這些風險。”
框架中提出的模型評估可用于發現某個AI模型何時具有可用于威脅、施加或逃避的“危險能力”。它還允許開發人員確定模型在多大程度上傾向于應用這種能力來造成損害——也就是它的一致性。DeepMind的開發團隊在博客中寫道,“即使在非常廣泛的場景中,一致性評估也應確認模型的行為符合預期,并在可能的情況下檢查模型的內部工作。”
這些結果可以用來了解風險水平以及導致風險水平的因素是什么。研究人員警告說:“如果AI系統的能力足以造成極端傷害,假設它被濫用或安排不當,AI社區應該將其視為高度危險的系統。要在現實世界中部署這樣的系統,AI開發人員需要展示出異常高的安全標準。”
這就是治理結構發揮重要作用的地方。OpenAI最近宣布,將向開發AI治理系統的機構和組織提供10筆10萬美元的贈款,而七國集團(G7)也計劃舉行會議,將討論如何應對AI風險。
DeepMind表示:“如果我們有更好的工具來識別哪些模型存在風險,開發商和監管機構就能更好地確保負責任地對AI進行訓練,根據風險評估做出部署決策,而透明度至關重要,包括報告風險,并確保有適當的數據和信息安全控制措施。”
AI法律服務商Luminance總法律顧問Harry Borovick表示,合規需要一致性。他說:“近幾個月來對監管制度不斷的解釋,為AI開發商和采用AI的企業構建了一個合規雷區。由于開發AI競賽并不會很快放緩,因此對明確而一致的監管指導的需求從未像現在這樣迫切。然而需要記住的是,AI技術以及它做出決定的方式是無法解釋的。這就是在制定法規時,科技和AI專家的正確結合是如此重要的原因。”