谷歌DeepMind AI再次完爆人類 讀唇語正確率勝專家
作者| Hal Hodson
策劃 | Aileen 魏子敏
編譯 | 姜范波 Molly
【導語】人工智能正在進軍唇語解讀陣地。谷歌DeepMind和牛津大學應用深度學習實驗室的一個項目正利用BBC的大量節目數據,創造唇語解讀系統,把人類專家遠遠地甩在身后。
這套系統的訓練材料包括約5000小時、6個不同的電視節目,如Newslight,BBC Breakfast 和Question Time。總體而言,視頻包含了118,000個句子。
牛津大學和DeepMind的研究人員用2010年1月至2015年12月播出的節目訓練了這套系統,并用2016年3月至9月的節目來做測試。
這里是一段沒有字幕的剪輯↓↓
同樣一段剪輯,但是人工智能系統已經給出了字幕↓↓

人工智能制勝之道
對數據集中隨機選擇的200個片段,在唇語解讀這件事上,人工智能完勝人類專家。
在測試數據集上,人類專家無錯誤注釋的字數僅有12.4%,而人工智能達到46.8%。同時,它犯的許多錯誤是很小的缺省,如少了一個詞尾的“s”。這樣的成績,也完勝其它的自動唇語解讀系統。
“這是邁向全自動唇語解讀系統的一大步。”芬蘭奧盧大學的周子恒(音譯)說:“沒有那個巨大的數據集,我們無法檢驗像深度學習這樣的新技術。”
兩個星期前,一個名為LipNet的類似深度學習系統——同樣是牛津大學開發的——在一個名為GRID的數據集上勝過了人類。但是GRID只包含了由51個獨立單詞組成的詞表,而BBC數據集包含了近17,500個獨立單詞,挑戰要大得多。
另外,BBC數據集的語法來自廣泛的真實人類語言,而GRID的33,000個句子語法單一,都是同樣的模式,預測起來要簡單得多。
DeepMind向牛津大學的這個小組表示,他們將開放BBC數據集以供訓練用。 來自LipNet的Yannis Assael說,他非常渴望能使用這個數據集。
唇語解讀之路
為了讓BBC數據集可供自動唇語解讀所用,視頻片段需先用機器學習進行處理。問題在于,音頻流和視頻流經常有1秒左右的延遲,這使得人工智能幾乎無法在所說的單詞和相應的口型之間建立聯系。
但是,假設大多數的視頻和音頻對應完好,一個計算機系統可以學會將聲音和口型正確地對應起來。基于這個信息,系統找出那些不匹配的的,將它們重新匹配。這樣自動處理了所有的5000小時的視頻和音頻資料后,唇語解讀的挑戰就可以開始了——這個挑戰對人工而言,是艱巨的。
在此之前,大家已經進行了許多相關的嘗試。他們使用卷積神經網絡(CNNs)來從靜止的圖像中預測音位(phoneme)和視位(viseme)。這兩個概念分別是聲音和圖像中可以辨認出來的語言的最小單位。然后人們接著嘗試去識別詞匯及詞組。
大神們使用離散余弦變換(DCT),深度瓶頸特征(DBF)等等手段來進行詞匯及詞組的預測。總的來講,此前的研究有兩個方面,其一是使用CTC(Connectionist Temporal Classification),這中方法首先在幀的層次上給出預測,然后把輸出的字符流按照合適的方式組合起來。這種方法的缺陷是詞匯與詞匯之間是獨立的。另一個方向是訓練序列-序列模型。這種方式是讀取整個輸入序列,然后再進行預測。對這個系統幫助***的就是Chan等人的論文《Vinyals. Listen, attend and spell》。論文中提出了一種很精致的聲音到文字的序列-序列方法。
這套唇語識別系統由一套“看-聽-同步-寫”網絡組成。它可以在有聲音或沒有聲音的情況下,通過識別講話人的面部,輸出視頻里面講的句子。在輸出向量Y=(y1,y2,...,yl)中,定義每一個輸出字符yi都是前面左右字符y<i的條件分布,輸出圖像序列
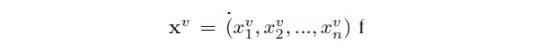
來進行唇語識別,輸入音頻序列
![]()
進行輔助。這樣,模型的輸出的概率分布為
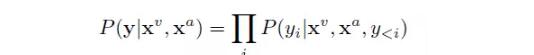
系統由三個主要部分組成:圖像編碼、音頻編碼和文字解碼。
下圖是系統的示意圖↓↓
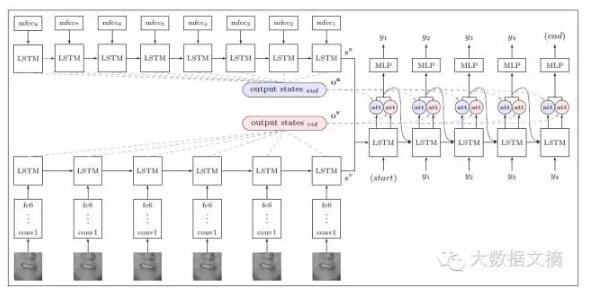
其中,s 為狀態向量,o為編碼器的輸出。***會輸出字符序列的概率分布。

這套系統可以應用在許多方面,當然不包括唇語竊聽:) 。它可以在嘈雜的環境中,向手機發送文字信息,這樣你的siri就可以不必聽你講清楚了。也可以為檔案中無聲的電影進行配音。還可以處理同時有好多人說話的情況。當然,它還有很多可以改進的空間,比如它的輸入是一個視頻的完整的唇語動作。但是在實時的視頻處理中,它只能獲得當前所有的唇語動作,未來的唇語動作顯然是無法獲得的。
接下來的問題是如何應用人工智能的唇語解讀新能力。我們不必擔心計算機通過解讀唇語來偷聽我們的談話,因為長距離麥克風的偷聽能力在多數情況下要好得多。
周子恒認為,唇語解讀最有可能用在用戶設備上,幫助它們理解人類想要說的。
Assael 說:“我們相信,機器唇語解讀器有非常大的應用前景,比如改進助聽器,公共場所的無聲指令(Siri再也不必聽到你的聲音了),嘈雜環境下的語音識別等。”
來源:https://www.newscientist.com/article/2113299-googles-deepmind-ai-can-lip-read-tv-shows-better-than-a-pro/
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】