語義Web信任綜述
引 言
在信息時代,通過Internet向物聯網和語義網的轉變,人與計算機的協作成為解決社會問題的主要途徑。語義Web創建的主要目的不僅是幫助人與機器之間的交互,而且是幫助機器與機器之間的交互。事實上,語義Web可以被看作是一個鏈接信息的網絡,它在全球范圍內促進了機器處理。語義Web也可以看作是Web上實體之間的關系集合,這些聯系也可以看作是圖,其中謂詞作為邊,類作為節點。
從一開始,人們就清楚地認識到,在一個巨大而開放的信息空間中,信息的可靠性和安全性將成為挑戰。從Web上獲取信息變得越來越普遍,用戶通過各種來源獲取信息,從個人網頁、政府機構到科學門戶。人類用戶往往會使用不同的方法來決定是否信任某個來源,例如依賴于他們以前的經驗或其他用戶的意見;但眾所周知,語義Web尋求不同的目標,即賦予計算機代理與Web內容和其他代理交互的能力,從而決定選擇合適的服務或信息提供者。在這種情況下,計算機代理如何能夠信任信息源?它如何識別獲取信息的正確性?又如何實現安全通信?
本文綜述了語義Web安全層和語義Web棧信任層的相關研究工作,包括研究信任和聲譽的各種定義,從不同的角度對信任進行分類,并引入開放式挑戰。
1、信任和聲譽的定義
1.1 信任
信任具有不同的含義,這取決于它所使用的上下文和領域。在計算機網絡中,它是指保證網絡安全和訪問控制的機制。在分布式系統和基于Agent的系統中,它被認為是一種度量可靠性的工具。在博弈論和政策學中,它被看作是系統在不確定條件下做出正確決策的速率。信任可以分為兩大類,即可靠性信任和決策信任,每一種信任都有不同的描述。當每個子A要求被信任人B執行某一任務時,被信任人A所看到的被信任人B的可靠性(概率)取決于預期任務的執行情況。
決策信任是指在一定的環境下,即使在勝算不大的情況下,信任方愿意依賴被信任方以獲得安全感的程度。在這種情況下所做的決定,取決于信任方所接受的風險程度,以及它以前對信任方的消極或積極的經驗。信任也被定義為對一個實體在特定背景下可靠、安全和可靠地行事的能力的堅定信念。
信任在計算機系統中并不是一個新的話題,但它是計算機科學范圍內的重要問題之一。圖 1 顯示Google Scholar報告的語義Web中與信任主題相關的文章數量。

圖1:關于語義web層的信任出版物的數量
1.2 聲譽
關于一個人或一件事的一般想法被稱為聲譽。聲譽可以是基于社區成員給一個人的累積成績或分數。為了計算一個實體的評級,可以采用不同的方法,例如平均值。通常,某一組的成員從其他用戶那里得到幾乎相同的評分,當一個組在某一主題上很有名時,該組的所有成員通常得到與他們組相同的評分。
此外,聲譽可以被認為是一個實體對其他實體在某些主題上的行為的信念或經驗。在這種情況下,聲譽評級應該基于第一手經驗,或者基于加權度量除以單個個人提供的引用總量,如谷歌頁面排名使用的方法。Repution方法可以是集中式的,由權威機構給出;也可以是分布式的,基于人群的已知邊。
2、信任分類
2.1 基于政策的信任
語義Web棧中唯一的垂直層稱為數字簽名,它利用XML的數字簽名能力,如簽名引用、信息和消解值來標記任何Web內容。連同證明、邏輯和信任層本身,這些層負責語義Web進程的可信任性。由于XML文檔的結構類似于圖表,主要的挑戰是通過對用戶和文檔實施策略來指定哪些用戶可以訪問文檔的哪些部分。也就是說,需要語義Web代理來確保信息和Web服務的安全免受未經授權的訪問。為了滿足這一需求,存在著多種安全策略,如身份驗證、數據完整性和隱私、訪問控制、授權和機密性等。
語義Web的XML特性使其具有使用元數據而不是數據本身的優勢,即使用有關數據的信息而不是整個數據本身。一個是元數據的規模相對較小,使數據更容易被發現。元數據也有缺點,由于元數據生成器的可信度不統一,需要每個用戶了解每個元數據的可信度水平,以充分利用元數據的優勢。
目前,我們的網站配備了各種工具,以確保信息交流的安全。數字簽名、公鑰、Web證書和加密等工具。為了保證商業伙伴之間在信任網絡中內容交換的安全性,引入了幾個安全標準。例如,W3C為基于XML的Web服務引入的WS-Security策略,它描述了將簽名和加密頭或安全令牌附加到SOAP MES-SAGE的方法,或者由OASIS Security Services提供的SAML策略,它提供了一種授權和授權的方法,但它不能給出任何關于信任的建議。
Kerberos票據發行系統是麻省理工學院為雅典娜項目創建的,是目前廣泛使用的可信第三方認證技術之一。WS-Trust作為前面提到的WS-Security的擴展,指定了通過授權、身份證明和實體性能獲得信任的方法。
建立信任的另一個挑戰是提供一種手段來揭示憑據,同時防止隱私和對信息的控制的損失。為了解決這個問題,引入了不同的機制和策略,例如TrustBuilder,它旨在以不會導致隱私損失的方式為證書權衡提供機制。由于信任決策是一種行為,它要求接受一定程度的暴露憑據的風險,以獲得贏得信任的好處。建議促進其他制度憑據交換的協商稱為PeerTrust,它是一種較新的策略和信任協商方法。
2.2 基于聲譽的信任
基于聲譽的信任的目的是通過個人或他人的經驗,或者在某些情況下通過個人和全球經驗的結合來做出信任決策。在基于聲譽的信任中,社區成員根據他們的交易、產品質量和服務一致性來判斷他們網絡中的其他成員。換句話說,網絡成員將在一個團隊中實施合作制裁,以激勵網絡中質量較差的服務提供者提供更好的服務。一個基于信任的網絡可以被看作是一個圖,其中的成員是節點,節點的邊根據成員從其他用戶那里感知到的信任性能進行加權。通過信任網絡,用戶可以通過個人經驗直接信任資源,也可以通過信任傳播方法間接信任其他受信任的用戶。
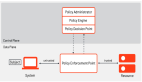
聲譽網絡可以從不同的角度來看待。它可以分為集中式和分布式兩種體系結構。在集中式信譽系統中,與任何成員的質量和性能相關的信息都是從與網絡中特定節點有過直接經驗的其他用戶那里收集的。然后,一個通常稱為聲譽中心的中央機構收集所有的評級,為節點的每個成員計算一個分數,并公布分數。社區成員在與網絡中其他成員的交易決策中可以使用分布式信譽評分。這個系統背后的理念是,與信譽評分較高的成員進行交易通常會產生更好的結果。圖 2,顯示集中式模型的架構。

圖2:集中式模型的模式
在一個分布式系統中,沒有信譽中心,而是有多個信譽庫,每個成員可以提交關于其他成員的經驗,甚至成員可以從不同的用戶那里獲得他們需要的關于某個社區成員的信息,這些用戶以前有過關于該成員的經驗。對等系統是分布式系統的一個例子。
在一些研究工作中,將分布式構造劃分為全局和局部兩個子類。在全球模型中,聲譽是基于社會成員的受歡迎程度。在第一次交互之后,社會的每一個MEM-BER為網絡的每一個其他MEM-BER創建一個配置文件,并保存關于每一個事務的經驗。一個人可以使用其他鄰居的經驗檔案來決定是否信任一個來源。然而,由于網絡的性質,區分正確和錯誤的信息是一個相當復雜的過程。因此,基于網絡用戶給出的總分來計算聲譽可能并不完全正確,人們可以嘗試信任網絡中某些節點計算出的分數,這些節點也可以作為社會的權威節點,通過其較高的社會網絡分數來獲得自己的能力。一個節點的鏈接越多,它就越能被信任。Eigentrust Algo-Rithm是全球信任性能排名的一個例子。圖 3,顯示分布式模型的架構。在局部模型中,該思想基于信譽的傳遞性,雖然在該模型中的條件下信任是個人的,并且因節點而異,但在任何情況下,一個節點沒有關于新受信者的任何信息,它可以依賴于封閉可信節點的經驗。如果一個人沒有任何關于別人的信息,他/她通常更信任他的朋友和親戚,而不是不認識的人或者消息來源。根據小世界假說,從信任者到受信者會有一條路徑,通過信任的親密朋友鏈。

圖3:分布式模型的模式
流模型在流方法中,信譽是通過網絡成員鏈傳遞的Itraton來計算的。對于信任網絡如何在網絡成員之間均勻或不均勻地分布,有些模型假設了一個恒定的信譽權重。由于網絡的總重量是不變的,每個成員的聲譽只能以其他成員的代價來提高。因此,每個節點信譽的增減程度是網絡內信譽分數輸入輸出流的函數。
由于信任和聲譽在本質上是多上下文的,因此建立多維模型來計算信任和聲譽具有重要意義。多維模型具有modu-lar結構,在這種體系結構中創建的代理能夠以一種最大限度地增加其表征能力的方式利用多個邏輯。
2.3 基于內容的信任
Web內容在語義Web中被表示為公理和本體。在下面的文章中,我們將探討使用Web事務的內容來獲得信任的可能性。語義Web信任層從不考慮Web上交換的信息內容。該問題通過認證、識別和證據檢查來解決。然而,語義Web使得直接交互和利用Web內容成為可能。因此,它提供了一個獨特的機會來使用網絡資源的內容作為判斷其創作者身份的手段。所有其他類型的信任評估方法都是基于信息提供者的聲譽、行為和實施策略來考慮信息提供者的合法性,而基于內容的信任更多地涉及Web上給出的內容的性質。在現實生活中,一個可能的選擇是信任資源所提供的信息,但如果許多低信任資源提供的信息是相同的,會導致受信任的信息資源沖突,那么人們可能會選擇相信來自于許多的信息,即使他們可能不是合法的。因此,可以說,每一個維度的聲譽和認證只是一個創建一個名為信任的現象。
本文提出了影響用戶選擇可信資源決策的各種因素,具體如下:
- 特定主題的權威可信信息提供程序在其他主題領域可能不受信任。人們可以信任世界衛生組織提供的有關疾病的信息,但同一組織提供的經濟信息不被用戶信任。
- 合法性的傳遞性與網絡上高度可信和授權的實體有關,可以將部分信任傳遞給與它們有關的其他實體。例如大學向醫科學生提供的證書。
- 實體生成的譜系內容可以從其創作者那里獲得信用和信任。科學網站提供的信息比匿名資源更容易被用戶接受。
- 在某些情況下,資源提供的信息可能是不完整或不充分的,例如藥品生產廠家可能忽視與某些治療條件有關的副作用,而專注于試驗結果。偏差的指定需要擴展和專業。
- 提供準確信息的動機,如果信息提供者有動機和興趣支持更準確的信息,那么用戶更有可能相信該信息。
- 在網絡上,惡意信息資源的欺騙行為是很自然的,因此,應該提醒用戶注意以下事實:資源和它們的同伙可能并不是它們看起來的樣子。
3、公開的挑戰和問題
- 在回顧文獻之后,我們認識到在本研究的范圍內有許多開放的挑戰和問題。總之,仍然需要:
- 改進語義Web信任算法的性能。
- 無縫集成和協作各種信任管理模型,實現語義Web中的整體信任管理。
- 功率有效的信任管理模型,以及更快和更少能耗的機制來支持IoT中支持語義的設備。
- 克服不同網絡間信任傳遞和計算困難的方法。
- 人的私密性和業務過程的保密性。
- 自主信任管理算法。
- 可信的數據融合。
參考文獻
1. Glimm B, Stuckenschmidt H (2016) 15 years of semantic web: an incomplete survey. KI-KünstlicheIntelligenz 30(2):117–130.
https ://doi.org/10.1007/s1321 8-016-0424-1
2. Yinan X (2016) A study on trust management algorithms for the social internet of things. Xie yinan school of computer science and engineering, a dissertation submitted in partial fulfilment of the requirement for the degree of master of science in digital media technology
3. Michele Nitti RG, Atzori L, Iera A, Morabito G (2012) A subjective model for trustworthiness evaluation in the social internet of things. In: 23rd annual IEEE international symposium on personal, indoor and mobile radio communications
4. Liu L, Loper ML, Ozkaya Y, Yasar A, Yigitoglu E (2016) Machine to machine trust in the IoT era. TRUST@AAMAS
5. Bao F, Chen I-R (2012) Dynamic trust management for internet of things applications. Self-IoT’12, San Jose, California, ACM978-1-4503-1753
6. Jingpei Wang SB, Yu Y, Xinxin N (2013) Distributed trust management mechanism for the internet of things. In: Proceedings of the 2nd international conference on computer science and electronics engineering (ICCSEE 2013)
7. Ben Saied Y, Olivereau A, Zeghlache D, Laurent M (2013) Trust management system design for the internet of things: a context-aware and multi-service approach. Comput Secur 39:351–365.
https ://doi.org/10.1016/j.cose.2013.09.001
8. Nitti RGM, Atzori L (2014) Trustworthiness management in the social internet of things. IEEE Trans Knowl Data Manag6(5):1253–1266