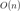譯者 | 朱先忠
審校 | 孫淑娟
引言
模型超參數(或模型設置)的優化可能是訓練機器學習算法中最重要的一步,因為它可以找到最小化模型損失函數的最佳參數。這一步對于構建不易過擬合的泛化模型也是必不可少的。
優化模型超參數的最著名技術是窮舉網格搜索和隨機網格搜索。在第一種方法中,搜索空間被定義為跨越每個模型超參數的域的網格。通過在網格的每個點上訓練模型來獲得最優超參數。盡管網格搜索非常容易實現,但它在計算上變得昂貴,尤其是當要優化的變量數量很大時。另一方面,隨機網格搜索是一種更快的優化方法,可以提供更好的結果。在隨機網格搜索中,通過僅在網格空間的隨機點樣本上訓練模型來獲得最佳超參數。
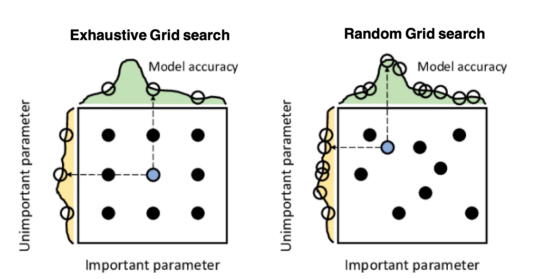
上圖給出了兩種網格搜索類型之間的比較。其中,九個點表示參數的選擇,左側和頂部的曲線表示作為每個搜索維度的函數的模型精度。該數據摘自Salgado Pilario等人發表在《IEEE工業電子學報》上的論文(68,6171–6180,2021)。
長期以來,兩種網格搜索算法都被數據科學家廣泛用于尋找最優模型超參數。然而,這些方法通常會找到損失函數遠離全局最小值的模型超參數。
然而,到了2013年,這一歷史發生了變化。這一年,James Bergstra和他的合作者發表了一篇論文,其中探索了貝葉斯優化技術,以便找到圖像分類神經網絡的最佳超參數,他們將結果與隨機網格搜索的結果進行了比較。最后的結論是,貝葉斯方法優于隨機網格搜索,請參考下圖。
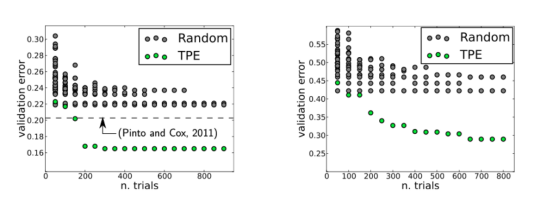
圖中展示的是LFW數據集(左)和PubFig83數據集(右)上的驗證錯誤。其中,TPE,即“Tree Parzen Estimator”,它是貝葉斯優化中使用的一種算法。該圖摘自Bergstra等人發表在《機器學習研究學報》上的論文(28,115–123,2013)。
但是,為什么貝葉斯優化比任何網格搜索算法都好呢?因為這是一種引導方法,它對模型超參數進行智能搜索,而不是通過反復試驗來找到它們。
在本文中,我們將細致剖析上述貝葉斯優化方法,并將通過一個名為Mango的相對較新的Python包來探索這種算法的一種實現版本。
貝葉斯優化
在解釋Mango能夠做什么之前,我們需要先來了解貝葉斯優化是如何工作的。當然,如果您對該算法已經非常理解,您可以跳過本節的閱讀。
歸納來看,貝葉斯優化共有4個部分:
- 目標函數:這是您想要最小化或最大化的真實函數。例如,它可以是回歸問題中的均方根誤差(RMSE)或分類問題中的對數損失函數。在機器學習模型的優化中,目標函數依賴于模型超參數。這就是為什么目標函數也稱為黑箱函數,因為其形狀未知。
- 搜索域或搜索空間:這對應于每個模型超參數具有的可能取值。作為用戶,您需要指定模型的搜索空間。例如,隨機森林回歸模型的搜索域可能是:
param_space = {'max_depth': range(3, 10),
'min_samples_split': range(20, 2000),
'min_samples_leaf': range(2, 20),
'max_features': ["sqrt", "log2", "auto"],
'n_estimators': range(100, 500)
}
貝葉斯優化使用定義的搜索空間對目標函數中評估的點進行采樣。
- 代理模型:評估目標函數非常昂貴,因此在實踐中,我們只在少數地方知道目標函數的真實值。然而,我們需要知道其他地方的值。這正是代理模型出場的時候,代理模型是建模目標函數的工具。代理模型的常見選擇是所謂的高斯過程(GP:Gaussian Processes),因為它能夠提供不確定性估計。
在貝葉斯優化開始時,代理模型從先驗函數開始,該先驗函數沿搜索空間以均勻的不確定性分布:
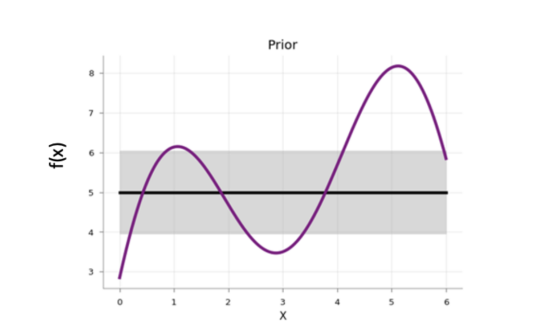
圖中展示了代理模型的先驗函數取值情況。其中,陰影區域代表不確定性,而黑線代表其平均值,紫色線表示一維目標函數。此圖片摘自2020年一篇??探索貝葉斯優化的博客文章??,作者是Aporv Agnihotri和Nipun Batra。
每次在目標函數中評估搜索空間中的樣本點時,該點處代理模型的不確定性變為零。經過多次迭代后,代理模型將類似于目標函數:
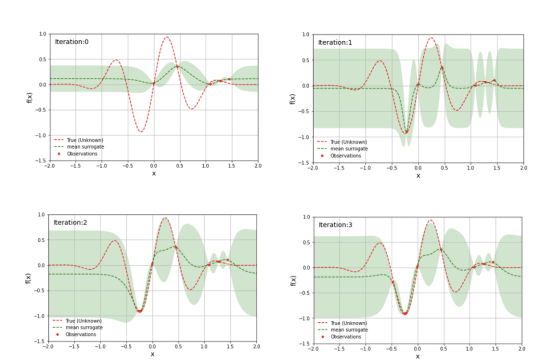
簡單一維目標函數的代理模型
然而,貝葉斯優化的目標不是對目標函數建模,而是以盡可能少的迭代次數找到最佳模型超參數。為此,需要使用一種采集(acquisition)函數。
- 采集函數:該函數是在貝葉斯優化中引入的,用于指導搜索。采集函數用于評估是否需要基于當前代理模型對點進行評估。一個簡單的采集函數是對代理函數的平均值最大化的點進行采樣。
貝葉斯優化代碼的步驟是:
選擇用于建模目標函數的代理模型,并定義其先驗for i = 1, 2,..., 迭代次數:
- 給定目標中的一組評估,使用貝葉斯方法以獲得后驗。
- 使用一個采集函數(這是一個后驗函數)來決定下一個采樣點。
- 將新采樣的數據添加到觀測集。
下圖顯示了簡單一維函數的貝葉斯優化:
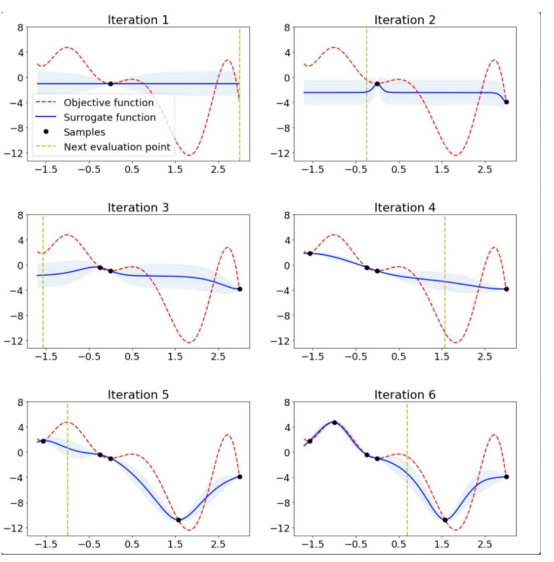
?上圖給出了一維函數的貝葉斯優化。圖片摘自ARM research的博客文章??《AutoML的可伸縮超參數調整》??。
其實,有不少Python軟件包都在幕后使用貝葉斯優化來獲得機器學習模型的最佳超參數。例如:Hyperopt;Optuna;Bayesian optimization;Scikit-optimize (skopt);GPyOpt;pyGPGO和Mango,等等。這里僅列舉了其中的一部分。
現在,讓我們正式開始Mango的探討。
Mango:為什么這么特別?
近年來,各行業數據量大幅增長。這對數據科學家來說是一個挑戰,這需要他們的機器學習管道具有可擴展性。分布式計算可能會解決這個問題。
分布式計算指的是一組計算機,它們在相互通信的同時執行共同的任務;這與并行計算不同。在并行計算中,任務被劃分為多個子任務,這些子任務被分配給同一計算機系統上的不同處理器。
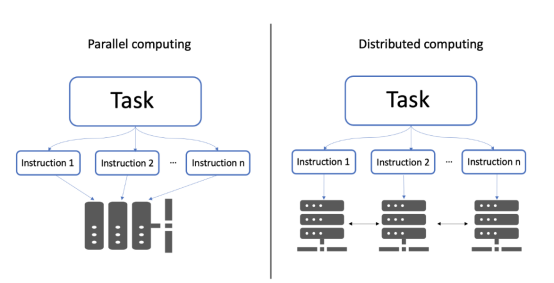
并行計算與分布式計算架構示意圖。
盡管有相當多的Python庫使用貝葉斯優化來優化模型超參數,但它們都不支持任何分布式計算框架上的調度。Mango開發者的動機之一是,創建一種能夠在分布式計算環境中工作的優化算法,同時保持貝葉斯優化的能力。
Mango體系結構的秘密是什么?使其在分布式計算環境中工作良好?Mango采用模塊化設計構建,其中優化器與調度器是解耦設計的。這種設計允許輕松擴展使用大量數據的機器學習管道。然而,這種架構在優化方法中面臨挑戰,因為傳統的貝葉斯優化算法是連續的;這意味著,采集函數僅提供單個下一個點來評估搜索。
Mango使用兩種方法來并行化貝葉斯優化:一種是稱為批高斯過程的方法bandits,另一種方法是k-means聚類。在本博客中,我們將不解釋批量高斯過程。
關于聚類方法,IBM的一組研究人員于2018年提出了使用k-means聚類來橫向擴展貝葉斯優化過程(有關技術細節,請參閱論文https://arxiv.org/pdf/1806.01159.pdf)。該方法包括從搜索域中采樣的聚類點,這些點在采集函數中生成高值(參見下圖)。在開始時,這些聚類在參數搜索空間中彼此遠離。當發現代理函數中的最佳區域時,參數空間中的距離減小。k-means聚類方法水平擴展優化,因為每個聚類用于作為單獨的過程運行貝葉斯優化。這種并行化導致更快地找到最優模型超參數。
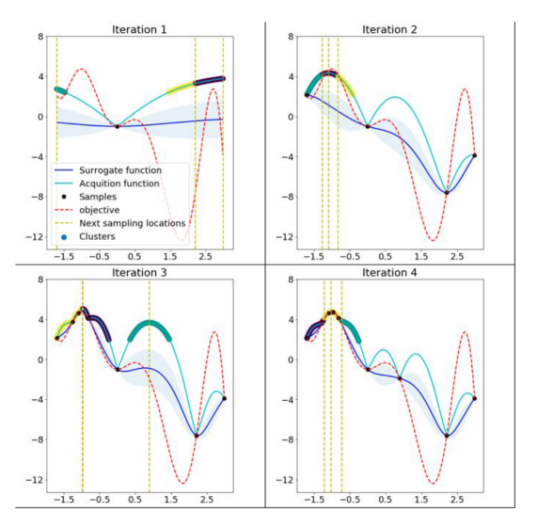
Mango使用聚類方法來擴展貝葉斯優化方法。采集函數上的彩色區域是由搜索空間中具有高采集函數值的采樣點構建的聚類。開始時,聚類彼此分離,但由于代理函數與目標相似,它們的距離縮短。(圖片摘自ARM research的博客文章《AutoML的可伸縮超參數調整》)
除了能夠處理分布式計算框架之外,Mango還與Scikit-learn API兼容。這意味著,您可以將超參數搜索空間定義為Python字典,其中的鍵是模型的參數名,每個項都可以用scipy.stats中實現的70多個分布中的任何一個來定義。所有這些獨特的特性使Mango成為希望大規模利用數據驅動解決方案的數據科學家的好選擇。
簡單示例
接下來,讓我們通過一個實例展示Mango是如何在優化問題中工作的。首先,您需要創建一個Python環境,然后通過以下命令安裝Mango:
pip install arm-mango
在本例中,我們使用可直接從Scikit-learn加載的加州住房數據集(有關此鏈接的更多信息請參考https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html):
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
import time
from mango import Tuner
housing = fetch_california_housing()
# 從輸入數據創建數據幀
# 注:目標的每個值對應于以100000為單位的平均房屋價值
features = pd.DataFrame(housing.data, columns=housing.feature_names)
target = pd.Series(housing.target, name=housing.target_names[0])
該數據集共包含20640個樣本。每個樣本包括房屋年齡、平均臥室數量等8個特征。此外,加州住房數據集還包括每個樣本的房價,單位為100000。房價分布如下圖所示:
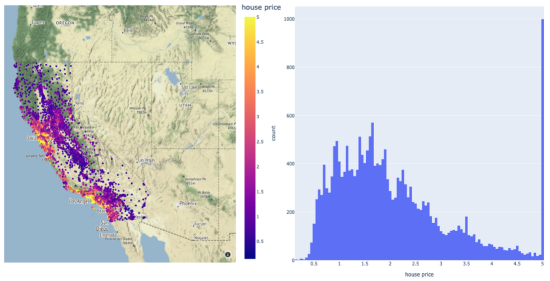
在圖示的左面板中,顯示了加利福尼亞數據集中房價的空間分布。右邊給出的是相應于同一變量的直方圖。
請注意,房價的分布有點偏左。這意味著,在目標中需要一些預處理。例如,我們可以通過Log或Box-Cox變換將目標的分布轉換為正態形狀。由于目標方差的減小,這種預處理可以提高模型的預測性能。我們將在超參數優化和建模期間執行此步驟。現在,讓我們將數據集拆分成訓練集、驗證集和測試集三部分:
# 將數據集拆分成訓練集、驗證集和測試集
x_train, x_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
x_train, x_validation, y_train, y_validation = train_test_split(x_train, y_train, test_size=0.2, random_state=42)
到目前,我們已經準備好使用Mango來優化機器學習模型。首先,我們定義Mango從中獲取值的搜索空間。在本例中,我們使用了一種稱為“極端隨機樹(Extreme Randomized Trees)”的算法,這是一種與隨機森林非常相似的集成方法,不同之處在于選擇最佳分割的方式是隨機的。該算法通常以偏差略微增加為代價來減少方差。
極端隨機化樹的搜索空間可以按如下方式定義:
# 第一步:定義算法的搜索空間(使用range而不是uniform函數來確保生成整數)
param_space = {'max_depth': range(3, 10),
'min_samples_split': range(int(0.01*features.shape[0]), int(0.1*features.shape[0])),
'min_samples_leaf': range(int(0.001*features.shape[0]), int(0.01*features.shape[0])),
'max_features': ["sqrt", "log2", "auto"]
}
定義參數空間后,我們再指定目標函數。在這里,我們使用上面創建的訓練和驗證數據集;但是,如果您想運行k倍交叉驗證策略,則需要在目標函數中由您自己來實現它。
# 第二步:定義目標函數
# 如果要進行交叉驗證,則在目標中定義交叉驗證
#在這種情況下,我們使用類似于1倍交叉驗證的方法。
def objective(list_parameters):
global x_train, y_train, x_validation, y_validation
results = []
for hyper_params in list_parameters:
model = ExtraTreesRegressor(**hyper_params)
model.fit(x_train, np.log1p(y_train))
prediction = model.predict(x_validation)
prediction = np.exp(prediction) - 1 # to get the real value not in log scale
error = np.sqrt(mean_squared_error(y_validation, prediction))
results.append(error)
return results
關于上述代碼,有幾點需要注意:
- 目標函數旨在找到使均方根誤差(RMSE)最小化的最佳模型參數。
- 在Scikit-learn中,回歸問題的極端隨機化樹的實現稱為ExtraTreesRegressor。
- 請注意,訓練集中的房價要經過對數變換。因此,驗證集上的預測被轉換回其原始規模。
優化模型超參數所需的最后一步是實例化類Tuner,它負責運行Mango:
#第三步:通過Tuner運行優化
start_time = time.time()
tuner = Tuner(param_space, objective, dict(num_iteration=40, initial_random=10)) #初始化Tuner
optimisation_results = tuner.minimize()
print(f'The optimisation in series takes {(time.time()-start_time)/60.} minutes.')
#檢查結果
print('best parameters:', optimisation_results['best_params'])
print('best accuracy (RMSE):', optimisation_results['best_objective'])
# 使用測試集上的最佳超參數運行模型
best_model = ExtraTreesRegressor(n_jobs=-1, **optimisation_results['best_params'])
best_model.fit(x_train, np.log1p(y_train))
y_pred = np.exp(best_model.predict(x_test)) - 1 # 獲取實際值
print('rmse on test:', np.sqrt(mean_squared_error(y_test, y_pred)))
上述代碼在MacBook Pro(處理器為2.3 Ghz四核英特爾酷睿i7)上運行了4.2分鐘。
最佳超參數和最佳RMSE分別為:
best parameters: {‘max_depth’: 9, ‘max_features’: ‘auto’, ‘min_samples_leaf’: 85, ‘min_samples_split’: 729}
best accuracy (RMSE): 0.7418871882901833
當在具有最佳模型參數的訓練集上訓練模型時,測試集上的RMSE為:
rmse on test: 0.7395178741584788
免責聲明:運行此代碼時可能會得到不同的結果。
讓我們簡要回顧一下上面代碼中使用的類Tuner。此類有許多配置參數,但在本例中,我們只嘗試了其中兩個:
- num_iteration:這些是Mango用于找到最佳值的迭代總數。
- initial_random:該變量設置測試的隨機樣本數。注意:Mango將所有隨機樣本一起返回。這非常有用,尤其是在優化需要并行運行的情況下。
注意:本博客中發布的示例僅使用了一個小數據集。然而,在許多實際應用程序中,您可能會處理需要并行實現Mango的大型數據文件。如果您轉到我的??GitHub源碼倉庫??,您可以找到此處顯示的完整代碼以及大型數據文件的實現。
總之,Mango用途廣泛。您可以在廣泛的機器和深度學習模型中使用它,這些模型需要并行實現或分布式計算環境來優化其超參數。因此,我鼓勵您訪問Mango的??GitHub存儲庫??。在那里,您可以找到許多工程源碼,展示Mango在不同計算環境中的使用。
總結
在本博客中,我們認識了Mango:一個Python庫,用于進行大規模貝葉斯優化。此軟件包將使您能夠:
- 擴展模型超參數的優化,甚至可以在分布式計算框架上運行。
- 輕松將scikit-learn模型與Mango集成,生成強大的機器學習管道。
- 使用scipy.stats中實現的任何概率分布函數,用于聲明你的搜索空間。
所有這些特性使Mango成為一個獨特的擴展您的數據科學工具包的Python庫。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:??Mango: A new way to do Bayesian optimization in Python??,作者:Carmen Adriana Martinez Barbosa