今年英語高考,CMU用重構(gòu)預(yù)訓(xùn)練交出134高分,大幅超越GPT3
我們存儲數(shù)據(jù)的方式正在發(fā)生變化,從生物神經(jīng)網(wǎng)絡(luò)到人工神經(jīng)網(wǎng)絡(luò),其實最常見的情況是使用大腦來存儲數(shù)據(jù)。隨著當今可用數(shù)據(jù)的不斷增長,人們尋求用不同的外部設(shè)備存儲數(shù)據(jù),如硬盤驅(qū)動器或云存儲。隨著深度學(xué)習技術(shù)的興起,另一種有前景的存儲技術(shù)已經(jīng)出現(xiàn),它使用人工神經(jīng)網(wǎng)絡(luò)來存儲數(shù)據(jù)中的信息。
研究者認為,數(shù)據(jù)存儲的最終目標是更好地服務(wù)于人類生活,數(shù)據(jù)的訪問方式和存儲方式同樣重要。然而,存儲和訪問數(shù)據(jù)的方式存在差異。歷史上,人們一直在努力彌補這一差距,以便更好地利用世界上存在的信息。如圖 3 所示:
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
- 在生物神經(jīng)網(wǎng)絡(luò)(如人腦)方面,人類在很小的時候就接受了課程(即知識)教育,以便他們能夠提取特定的數(shù)據(jù)來應(yīng)對復(fù)雜多變的生活。
- 對于外部設(shè)備存儲,人們通常按照某種模式(例如表格)對數(shù)據(jù)進行結(jié)構(gòu)化,然后采用專門的語言(例如 SQL)從數(shù)據(jù)庫中有效地檢索所需的信息。
- 對于基于人工神經(jīng)網(wǎng)絡(luò)的存儲,研究人員利用自監(jiān)督學(xué)習存儲來自大型語料庫的數(shù)據(jù)(即預(yù)訓(xùn)練),然后將該網(wǎng)絡(luò)用于各種下游任務(wù)(例如情緒分類)。
來自 CMU 的研究者提出了一種訪問包含各種類型信息數(shù)據(jù)的新方法,這些信息可以作為指導(dǎo)模型進行參數(shù)優(yōu)化的預(yù)訓(xùn)練信號。該研究以信號為單位結(jié)構(gòu)化地表示數(shù)據(jù)。這類似于使用數(shù)據(jù)庫對數(shù)據(jù)進行存儲的場景:首先將它們構(gòu)造成表或 JSON 格式,這樣就可以通過專門的語言 (如 SQL) 準確地檢索所需的信息。
此外,該研究認為有價值的信號豐富地存在于世界各類的數(shù)據(jù)中,而不是簡單地存在于人工管理的監(jiān)督數(shù)據(jù)集中, 研究人員需要做的是 (a) 識別數(shù)據(jù) (b) 用統(tǒng)一的語言重組數(shù)據(jù)(c)將它們集成并存儲到預(yù)訓(xùn)練語言模型中。該研究稱這種學(xué)習范式為重構(gòu)預(yù)訓(xùn)練(reStructured Pre-training,RST)。研究者將這個過程比作「礦山尋寶」。不同的數(shù)據(jù)源如維基百科,相當于盛產(chǎn)寶石的礦山。它們包含豐富的信息,比如來自超鏈接的命名實體,可以為模型預(yù)訓(xùn)練提供信號。一個好的預(yù)訓(xùn)練模型 (PLM) 應(yīng)該清楚地了解數(shù)據(jù)中各種信號的組成,以便根據(jù)下游任務(wù)的不同需求提供準確的信息。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
論文地址:https://arxiv.org/pdf/2206.11147.pdf
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
預(yù)訓(xùn)練語言模型尋寶
該研究提出自然語言處理任務(wù)學(xué)習的新范式, 即 RST,該范式重新重視數(shù)據(jù)的作用,并將模型預(yù)訓(xùn)練和下游任務(wù)的微調(diào)視為數(shù)據(jù)的存儲和訪問過程。在此基礎(chǔ)上,該研究實現(xiàn)了一個簡單的原則,即良好的存儲機制不僅應(yīng)該具有緩存大量數(shù)據(jù)的能力,還應(yīng)該考慮訪問的方便性。
在克服了一些工程挑戰(zhàn)后,該研究通過對重構(gòu)數(shù)據(jù)(由各種有價值的信息而不是原始數(shù)據(jù)組成)進行預(yù)訓(xùn)練來實現(xiàn)這一點。實驗證明,RST 模型不僅在來自各種 NLP 任務(wù)(例如分類、信息抽取、事實檢索、文本生成等)的 52/55 流行數(shù)據(jù)集上表現(xiàn)大幅超過現(xiàn)有最好系統(tǒng)(例如,T0),而且無需對下游任務(wù)進行微調(diào) 。在每年有數(shù)百萬學(xué)生參加的中國最權(quán)威的高考英語考試中也取得了優(yōu)異的成績。
具體而言,本文所提出的高考 AI (Qin) 比學(xué)生的平均分數(shù)高出 40 分,比使用 1/16 參數(shù)的 GPT3 高出 15 分。特別的 Qin 在 2018 年英語考試中獲得了 138.5 的高分(滿分 150)。
此外,該研究還發(fā)布了高考基準(Gaokao Benchmark)在線提交平臺,包含 2018-2021 年至今 10 篇帶注釋的英文試卷(并將每年進行擴展),讓更多的 AI 模型參加高考,該研究還建立了一個相對公平的人類和 AI 競爭的測試平臺,幫助我們更好地了解我們所處的位置。另外,在前幾天(2022.06.08)的 2022 年高考英語測試中,該 AI 系統(tǒng)獲得了 134 分的好成績,而 GPT3 只獲得了 108 分。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
該研究的主要貢獻包括:
(1)提出 NLP 方法的演進假說。該研究試圖通過探索現(xiàn)代 NLP 技術(shù)發(fā)展之間的內(nèi)在聯(lián)系,從全局的角度建立了「NLP 技術(shù)演進假說」。簡而言之,該假說的核心思想是:技術(shù)的迭代總是沿著這樣的方向發(fā)展:即開發(fā)者只需做更少的事情便可以來設(shè)計更好、更通用的系統(tǒng)。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
到目前為止,NLP 技術(shù)演進已經(jīng)經(jīng)歷了如圖 2 所示的多次迭代:特征工程→架構(gòu)工程→目標工程→prompt 工程,正在朝著更實際有效的以數(shù)據(jù)為中心的工程邁進。研究者希望未來能激發(fā)更多的科研人員批判性地思考這個問題,把握技術(shù)進步的核心驅(qū)動力,找到學(xué)術(shù)發(fā)展「梯度上升」路徑,做更多有科學(xué)意義的工作。
(2)基于演進假說新范式:重構(gòu)預(yù)訓(xùn)練(reStructured Pre-training)。該范式將模型預(yù)訓(xùn)練 / 微調(diào)視為數(shù)據(jù)存儲 / 訪問過程,并聲稱良好的存儲機制應(yīng)該使預(yù)期數(shù)據(jù)易于訪問。有了這樣一個新范式,該研究能夠從 10 個數(shù)據(jù)源(例如 Wikipedia)中統(tǒng)一世界上 26 種不同類型的信號(例如句子的實體)。在此基礎(chǔ)上訓(xùn)練的通用模型在各種任務(wù)上取得了很強的泛化能力,其中包括 55 個 NLP 的數(shù)據(jù)集。
(3)用于高考的 AI。基于上述范式,該研究開發(fā)了一個專門用于高考英語測試任務(wù)的 AI 系統(tǒng)——Qin。這是世界上第一個基于深度學(xué)習的高考英語人工智能系統(tǒng)。Qin 在多年的高考試題上都取得了卓越的成績:比普通人高出 40 分,僅用 GPT-3 1/16 的參數(shù)量就獲得了比 GPT-3 高 15 分的成績。特別是在 2018 年英語試題上,QIN 獲得了 138.5 分(滿分 150 分)的高分,聽力和閱讀理解都滿分。
(4) 豐富的資源。(1) 為了跟蹤現(xiàn)有 AI 技術(shù)在實現(xiàn)人類智能方面的進展,該研究發(fā)布了一種新基準——Gaokao Benchmark。它不僅提供對現(xiàn)實世界場景中各種實際任務(wù)和領(lǐng)域的綜合評估,還可以提供人類的表現(xiàn)成績,以便人工智能系統(tǒng)可以直接與人類進行比較。(2)該研究使用 ExplainaBoard(Liu et al., 2021b)為 Gaokao Benchmark 設(shè)置了一個交互式排行榜,以便更多的 AI 系統(tǒng)可以輕松參加 Gaokao Benchmark 并自動獲得分數(shù)。(3)所有資源都可以在 GitHub 上找到。
此外,AI 在高考英語測試任務(wù)上的成功為研究者提供了很多新的思考:AI 技術(shù)可以賦能教育,幫助解決教育和教學(xué)中的一系列問題。
例如,(a) 幫助教師自動評分,(b) 幫助學(xué)生回答有關(guān)作業(yè)的問題并詳細解釋,以及 (c) 更重要的是,促進教育公平,讓大多數(shù)家庭都能獲得同等質(zhì)量的教育服務(wù)。這項工作首次以統(tǒng)一的方式整合了世界上 26 個不同的信號,而不是試圖區(qū)分有監(jiān)督和無監(jiān)督的數(shù)據(jù),而是關(guān)心我們可以多少使用大自然給我們的信息以及如何使用。來自各種 NLP 任務(wù)的 50 多個數(shù)據(jù)集的出色表現(xiàn)顯示了以數(shù)據(jù)為中心的預(yù)訓(xùn)練的價值,并激發(fā)了更多的未來探索。
重構(gòu)預(yù)訓(xùn)練
解決 NLP 任務(wù)的范式正在迅速變化,并且仍在持續(xù),下表列出了 NLP 中的五種范式:
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
與現(xiàn)有的以模型為中心的設(shè)計范式不同,該研究更多地從數(shù)據(jù)的角度思考,以最大限度地利用已有數(shù)據(jù)。具體來說,該研究采用數(shù)據(jù)存儲和訪問視圖,其中預(yù)訓(xùn)練階段被視為數(shù)據(jù)存儲過程,而基于預(yù)訓(xùn)練模型的下游任務(wù)(例如,情感分類)被視為來自預(yù)訓(xùn)練模型的數(shù)據(jù)訪問過程,并聲稱良好的數(shù)據(jù)存儲機制應(yīng)該使存儲的數(shù)據(jù)更易于訪問。
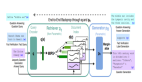
為了實現(xiàn)這一目標,該研究將數(shù)據(jù)視為由不同信號組成的對象,并認為一個好的預(yù)訓(xùn)練模型應(yīng)該(1)覆蓋盡可能多的信號類型,(2)當下游任務(wù)需要時,為這些信號提供精確的訪問機制。一般來說,這個新范式包含三個步驟:重構(gòu)、預(yù)訓(xùn)練、微調(diào)。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
重構(gòu)、預(yù)訓(xùn)練、微調(diào)的新范式凸顯了數(shù)據(jù)的重要性,研究人員需要在數(shù)據(jù)處理上投入更多的工程精力。
重構(gòu)工程
信號定義
信號是數(shù)據(jù)中存在的有用信息,可以為機器學(xué)習模型提供監(jiān)督,表示為 n 元組。例如「莫扎特出生在薩爾茨堡」,「莫扎特」、「薩爾茨堡」可以被認為是命名實體識別的信號。通常,可以從不同的角度對信號進行聚類,如下圖 6 所示。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
數(shù)據(jù)挖掘
現(xiàn)實世界的數(shù)據(jù)中包含很多不同類型的信號。重構(gòu)預(yù)訓(xùn)練使這些信號能夠充分被利用。該研究將收集到的信號(n 元組)組織在樹形圖中,如下圖 10 所示。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
信號提取
下一步該研究進行了信號提取和處理,涉及從不同模態(tài)的數(shù)據(jù)挖掘中獲取原始數(shù)據(jù)、數(shù)據(jù)清洗和數(shù)據(jù)規(guī)范化。現(xiàn)有的方法大致分為兩種:(1)基于規(guī)則的,(2)基于機器學(xué)習的。在這項工作中,該研究主要關(guān)注基于規(guī)則的信號提取策略,并為未來的工作留下更多高覆蓋率的方法。
信號重構(gòu)
在從各種數(shù)據(jù)挖掘中提取出不同的信號之后,接下來重要的一步是將它們統(tǒng)一成一個固定的形式,以便在預(yù)訓(xùn)練期間將所有信息一致存儲在模型中。prompt 方法(Brown et al., 2020; Liu et al., 2021d)可以實現(xiàn)這個目標,原則上,通過適當?shù)?prompt 設(shè)計,它幾乎可以將所有類型的信號統(tǒng)一為一種語言模型風格。
該研究將信號分為兩大類:通用信號和任務(wù)相關(guān)信號。前者包含基本的語言知識,可以在一定程度上使所有下游任務(wù)受益,而后者則可以使某些特定的下游任務(wù)受益。
在 55 種常用的 NLP 數(shù)據(jù)集上的實驗
該研究在 55 個數(shù)據(jù)集上進行評估,然后將它們分別與 GPT3 和 T0pp 進行比較。與 GPT3 比較的結(jié)果如圖所示:在除 cb 數(shù)據(jù)集之外的四個數(shù)據(jù)集上,RST-All 和 RST-Task 都具有比 GPT3 的小樣本學(xué)習更好的零樣本性能。此外,cb 數(shù)據(jù)集是這些數(shù)據(jù)集中最小的,驗證集中只有 56 個樣本,因此不同的 prompt 在該數(shù)據(jù)集上的性能會有較大的波動。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
與 T0pp 比較結(jié)果如表 4-6 所示。例如在 55 個測量的平均性能中,RST-All 在 49 個數(shù)據(jù)集上擊敗了 T0pp,并在 47/55 示例上以最大性能勝出。此外,在 55 個數(shù)據(jù)集的平均性能測試中,RST-Task 在 52 個數(shù)據(jù)集上優(yōu)于 T0pp,并在 50/55 個示例下超越 T0pp。這說明重構(gòu)學(xué)習的優(yōu)越性。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
性能最佳的模型 RST-Task 擅長哪些任務(wù)?為了回答這個問題,該研究將 RST-Task 模型在零樣本設(shè)置中的性能與當前 SOTA 模型進行比較,結(jié)果如圖 13 所示。RST-Task 擅長主題分類、情感分類和自然語言推理任務(wù),但在信息提取任務(wù)中表現(xiàn)較差。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
高考實驗:邁向人類水平的 AI
該研究收集了 10 份高考英語試卷,包括 2018 年國考 I/III、2019 年國考 I/II/III、2020 年國考 I/II/III、2021 年全國卷 A/B。這些試卷遵循相同的題型,他們將所有考試題型分為以下七個子類別,如表 7 所示:
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
每篇高考英語試卷滿分 150 分。聽力、完形填空、閱讀、寫作分別占 30、45、40、35。通常,寫作部分是主觀的,需要人工評估,而其他部分是客觀的,可以自動評分。如表 8 所示:
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
使用表 1 中所示的重構(gòu)工程循環(huán)來構(gòu)建高考英語 AI 系統(tǒng),即 Qin。整個過程如圖 14 所示:
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
該研究使用以下 prompt 將原始信號元組轉(zhuǎn)換為 prompt 樣本,如表 9 所示:
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
實驗結(jié)果如表 10-11 所示,我們可以得出以下結(jié)論:在每一份英語試卷中,RST 在兩套聽力考試中取得了最高的總分,平均分數(shù)為 130.6 分;與 T0pp 相比,RST 的性能要遠遠優(yōu)于相同模型大小下的 T0pp。在所有設(shè)置中,RST 獲得的總分平均比 T0pp 高出 54.5 分,最高差距為 69 分(占總分的 46%);與 GPT3 相比,RST 可以在模型大小小 16 倍的情況下取得明顯更好的結(jié)果。在所有考慮的設(shè)置中,RST 獲得的總分平均比 T0pp 高 14.0 分,最高為 26 分(占總分的 17%);對于 T0pp,使用黃金和語音轉(zhuǎn)文本成績單獲得的聽力分數(shù)差異很大,平均為 4.2 分。相比之下,GPT3 和 RST 分別為 0.6 和 0.45,表明 T0pp 的性能對文本質(zhì)量很敏感。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
該研究進行了細粒度分析,以了解不同模型在不同問題子類別上的表現(xiàn)。在圖 15-(a) 中,很明顯 RST 和 GPT3 在每個問題子類別上都優(yōu)于 T0pp。
圖 15-(b)為近年來模型的表現(xiàn)和學(xué)生在全國試卷上的平均表現(xiàn)。很明顯,T0pp 在 9/10 試卷上的總分低于學(xué)生的平均水平,而 RST 和 GPT3 的表現(xiàn)則超過了學(xué)生的平均水平。尤其是這十份試卷中有五份,RST 的總分超過了 130(通常被認為是學(xué)生爭取的目標分數(shù))。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")
2022 年高考 - 英語考試(2022.06.08)剛剛結(jié)束,了解到模型在最近一年的高考試卷中的表現(xiàn)。該研究用 GPT3 和 RST 進行實驗。結(jié)果顯示 RST 總分達到 134,遠高于 GPT3 達到的 108 分。
預(yù)訓(xùn)練交出134高分,大幅超越GPT3")