如何在云原生混部場景下利用資源配額高效分配集群資源?
精選01 引言
在阿里集團,離線混部技術從 2014 年開始,經歷了七年的雙十一檢驗,內部已實現大規模落地推廣,每年為阿里集團節省數十億的資源成本,整體資源利用率為 70%左右,達到業界領先水平。這兩年,我們開始把集團內的混部技術通過產品化的方式輸出給業界,通過插件化的方式無縫安裝在標準原生的 K8s 集群上,配合混部管控和運維能力,提升集群的資源利用率和產品的綜合用戶體驗。
由于混部是一個復雜的技術及運維體系,包括 K8s 調度、OS 隔離、可觀測性等等各種技術,之前的一篇文章《 歷經 7 年雙 11 實戰,阿里巴巴是如何定義云原生混部調度優先級及服務質量的? 》,主要聚焦在調度優先級和服務質量模型上,今天我們來關注一下資源配額多租相關的內容。
02 資源配額概述
首先想提一個問題,在設計上,既然 K8s 的調度器已經可以在沒有資源的情況下,讓 pod 處于 pending 狀態,那為什么,還需要有一個資源配額(Resource Quota)的設計?
我們在學習一個系統時,不但要學習設計本身,還需要考慮為什么這個設計是必須的?如果把這個設計從系統中砍掉,會造成什么后果?因為在一個系統中增加任何一項功能設計,都會造成好幾項邊際效應(Side Effect),包括使用這個系統的人的心智負擔,系統的安全性、高可用性,性能,都需要納入考慮。所以,功能不是越多越好。越是優秀的系統,提供的功能反而是越少越好。例如 C 語言只有 32 個關鍵字,而用戶可以通過自定義組合這些基礎能力,實現自己想要的任何需求。
回到原問題,一個集群的資源一定是有限的,無論是物理機上的 CPU、內存、磁盤,還有一些別的資源例如 GPU 卡這些。光靠調度,是否能解決這個問題呢?如果這個集群只有一個用戶,那么這個問題其實還是能忍受的,例如看到 pod pending了,那就不創建新的 pod 了;如果新的 pod 比較重要,這個用戶可以刪掉舊的 pod,然后再創建新的。但是,真實的集群是被多個用戶或者說團隊同時使用的,當 A 團隊資源不夠了,再去等 B 團隊的人決策什么應用可以騰挪出空間,在這個時候,跨團隊的交流效率是非常低下的。所以在調度前,我們就需要再增加一個環節。如下圖所示:

在這個環節內,引入了資源配額和租戶這 2 個概念。租戶,是進行資源配額調配的團隊單位。配額,則是多個租戶在使用有限的集群資源時,互相在事先達成的一個共識。事先是一個非常重要的關鍵詞,也就是說不能等到 pod 到了調度時、運行時,再去告訴創建者這個 pod 因為配額不足而創建不出來,而是需要在創建 pod 之前,就給各個團隊一個對資源的心理預期,每年初在配置資源配額時,給 A 團隊或者 B 團隊定一個今年可以使用的配額總量,這樣當 A 團隊配額用完時,A 團隊內部可以先進行資源優先級排序,把不重要的 pod 刪除掉,如果還不夠,那就再和 B 團隊商量,是否可以從 B 團隊的配額劃分一些配額過來。這樣的話,就無需任何情況下都要進行點對點的低效率溝通。A 團隊和 B 團隊在年初的時候就需要對自己的業務的資源用量,做一個大概的估算,也就是資源預算。
所以從這個角度來說,資源配額,是多個租戶之間低頻高效率溝通合作的一種方式。如果把配額這個概念放到經濟學中,是不是就有點計劃經濟的感覺了呢?其實里面的核心思想是一致的,都是在有限的資源情況下,各個組織之間在事先達成一個高效率的合作溝通方案。
K8s | 經濟學 | 公司財務 | 抽象概念相同處 |
配額 | 計劃經濟 | 預算 | 事先的,低頻的,少數大的組織之間進行溝通 |
調度優先級 | 市場經濟 | 執行 | 事中的,高頻的,大量小的個體之間進行溝通 |
服務質量 | 決算 | 事后統計的,實際發生的值 |
03 低優資源配額從哪里來?
apiVersion: v1
kind: Pod
metadata:
annotations:
alibabacloud.com/qosClass: BE # {LSR,LS,BE}
spec:
containers:
- resources:
limits:
alibabacloud.com/reclaimed-cpu: 1000 # 單位 milli core,1000表示1Core
alibabacloud.com/reclaimed-memory: 2048 # 單位 字節,和普通內存一樣。單位可以為 Gi Mi Ki GB MB KB
requests:
alibabacloud.com/reclaimed-cpu: 1000
alibabacloud.com/reclaimed-memory: 2048
再回到今天想討論的話題,云原生混部的資源配額,和 K8s 社區原生的資源配額有什么區別?從上面的 yaml 配置可以看到,低優資源我們使用了社區的擴展資源來進行管理,所以,很順理成章的就是對低優 CPU 和低優內存做一個配額總量的控制,并且這些總量會在不同部門之間進行事先的預算分配,這些邏輯和社區的資源配額邏輯是一樣的,在這里就不贅述了,大家可以看社區的官方文檔:《資源配額》
但是低優資源還有一些邏輯是和社區資源配額是不一樣的,并且,由于 CPU 和內存這 2 種資源天生的特性不同,所以還有區別,接下來用一張表來展現這個概念。
CPU | 內存 | |
集群機器的所有資源總量 | 100C | 100G |
混部參數 | 低優 CPU 超賣比:60% | 低優內存分配比:40% |
K8s 原生資源配額總量(對應于混部的高、中優總配額) | 100C | 60G |
混部低優配額總量 | 60C | 40G |
可以看到,由于 CPU 是可壓縮資源,我們引入了 低優 CPU 超賣比 這個參數,在原有集群 100C 的基礎上,可以另外超賣出 60C 的資源,給所有的低優任務使用。而對于內存這種不可壓縮資源而言,總體 100G,按照 低優內存分配比 這個參數,劃分了 40G 之后,剩下給高中優的用量就只剩 60G 了。因為在混部集群的管理中,由此得到的一個結論就是,要給集群的機器配置更多的內存,這樣才有足夠的數量不影響在線業務使用。
注:可壓縮資源(例如 CPU 循環,disk I/O 帶寬)都是速率性的可以被回收的,對于一個 task 可以降低這些資源的量而不去殺掉 task;和不可壓縮資源(例如內存、硬盤空間)這些一般來說不殺掉 task 就沒法回收的。
《在 Google 使用 Borg 進行大規模集群的管理 5-6》- 6.2 性能隔離
這里順便賣個關子,具體這個配比多少是合適的,包括這幾個參數到底設置多少是合理的,在阿里云的商用產品 ACK 敏捷版混部里面會有具體內容輸出。
04 基于容量的彈性配額調度
云原生混部在配額方面,和社區的第二個區別在哪里呢?可以看到的是,引入混部后會引入大量的離線運算任務,和比較有規律的在線業務相比,離線任務像洪水一樣是一波一波的,在整個時間區間內更不規律。有可能 A 團隊在跑大數據計算,把自己的低優配額都跑完了,但是 B 團隊的大數據計算這個時候還沒跑,還有空閑的配額。
那么,是否可以把這部分的配額利用起來,先“借”給 A 部門使用呢?這里就可以引入另外一個能力,基于容量的配額調度。
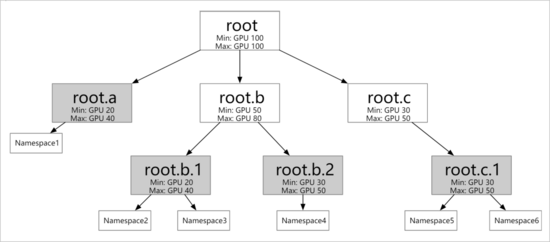
- 支持定義不同層級的資源配額。如上圖所示,您可以根據具體情況(比如:公司的組織結構)配置多個層級的彈性配額。彈性配額組的葉子節點可以對應多個 Namespace,但同一個 Namespace 只能歸屬于一個葉子節點。
- 支持不同彈性配額之間的資源借用和回收。
- Min:您可以使用的保障資源(Guaranteed Resource)。當整個集群資源緊張時,所有用戶使用的 Min 總和需要小于集群的總資源量。
- Max:您可以使用的資源上限。
引入了這個彈性配額調度后,我們發現組織中多個團隊在使用低優資源時的“彈性”更強了,當 B 團隊有空閑的配額時,可以動態的“借”給 A 團隊使用,反之亦然。這樣集群在全時間段里面的利用率進一步提升,更充分和有效的利用了集群的資源。
05 相關解決方案介紹
進入了 2022 年,混部在阿里內部已經成為了一個非常成熟的技術,為阿里每年節省數十億的成本,是阿里數據中心的基本能力。而阿里云也把這些成熟的技術經過兩年的時間,沉淀成為混部產品,開始服務于各行各業。
在阿里云的產品族里面,我們會把混部的能力通過 ACK 敏捷版 , 以及 CNStack(CloudNative Stack)產品家族 ,對外進行透出,并結合龍蜥操作系統(OpenAnolis),形成完整的 云原生數據中心混 部的 一體化解決方案 ,輸出給我們的客戶。