













作者 | 游戲算法-陳可
引言
我們說到的 bias,一般是指一種相對不公平、偏離客觀公正的理想狀態(tài),或者在整體的各個方面上表現(xiàn)出 unbalanced issues 的現(xiàn)象。對于“客觀公正的理想狀態(tài)”,在各種場景中沒有一個統(tǒng)一的定義,而是在各自場景的討論中會產(chǎn)生一些達(dá)成共識的概念。然而,這個概念也是隨著人們認(rèn)知的加深而不斷延展的。因此 bias 仍然是一個非常 open 的話題。
推薦系統(tǒng)是一個涉及到眾多環(huán)節(jié)的復(fù)雜系統(tǒng)。在系統(tǒng)中,推薦模型基于發(fā)生過的用戶行為進(jìn)行學(xué)習(xí),對用戶進(jìn)行 item(視頻、文章、商品等)的展現(xiàn),用戶對展現(xiàn)出來的 item 產(chǎn)生反饋,反饋的用戶行為數(shù)據(jù)繼續(xù)被模型學(xué)習(xí)。在整個鏈路中,沒有哪個環(huán)節(jié)是絕對意義上的“因”和“果”,它們是一個相互影響的關(guān)系。(見圖 1)
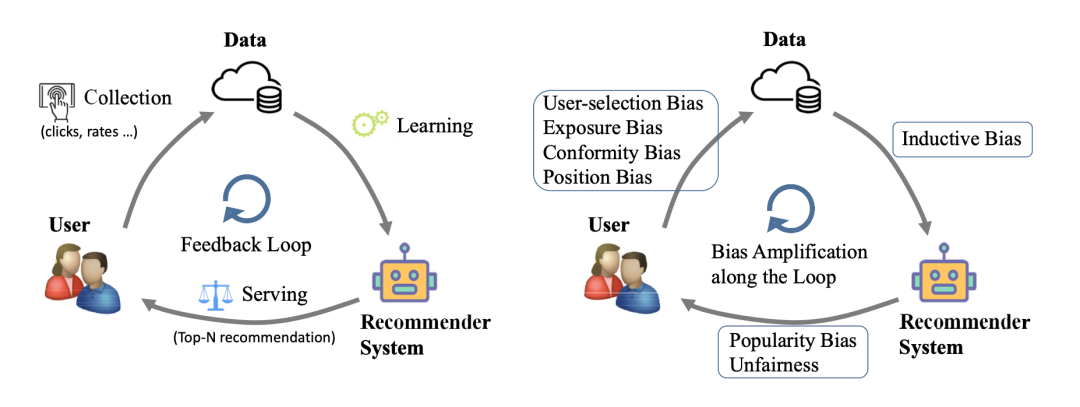
圖 1. 推薦系統(tǒng)中各個環(huán)節(jié)和 bias 產(chǎn)生的階段(來自文獻(xiàn)[1])
推薦系統(tǒng)的各個環(huán)節(jié)都依賴于用戶與 item 的交互,交互是有限且需要花費成本的,在某些情況下不會是客觀事實的充分反映。在此 bias 就會產(chǎn)生,并且對推薦系統(tǒng)的整個鏈路產(chǎn)生著影響。
一些比較公認(rèn)的 bias 包括:
Position bias(位置偏差):
- 概念解釋:用戶的精力是有限的,用戶有更大概率與展現(xiàn)在靠前位置的 item 發(fā)生交互,產(chǎn)生正向行為,而與 item 是否符合用戶偏好無關(guān)。
- 負(fù)面影響:數(shù)據(jù)中的正負(fù)例 label 不一定客觀反映用戶偏好。
- 典型場景:電商/文章 推薦中一個頁面內(nèi)有多個位置展現(xiàn)的點擊行為。
Exposure Bias(曝光偏差):
注意:這里的 exposure 曝光,是指 item 真正被用戶注意到,而不是 item 簡單地在客戶端展現(xiàn)。下文會使用曝光一詞來代指用戶真正注意到了 item,而使用展現(xiàn)一詞來代指 item 在客戶端展現(xiàn)的埋點上報,以此作為區(qū)別。
- 概念解釋:存在于基于隱式反饋(implicit feedback)建模的場景中(比如 CTR 場景),對于全量的 item,用戶只會被曝光到其中的少數(shù)一部分,并與之產(chǎn)生顯式正向行為。那些沒有顯式行為的 item,可能是用戶不感興趣,也可能是沒有曝光給用戶。如果簡單地將它們都處理為負(fù)例用作訓(xùn)練模型,那么將會產(chǎn)生嚴(yán)重的偏差(一些論文將其稱為 positive-unlabeled 問題)。另一方面,在推薦結(jié)果中,熱度越高 item, 會更可能曝光給用戶。對于用戶來說,一個 item 是否會產(chǎn)生顯式正向行為的記錄,是非隨機缺失的(missing not at random,很多論文中又簡稱為 MNAR)。這樣會導(dǎo)致收集到的數(shù)據(jù)分布與真實的分布是不一致的。
- 負(fù)面影響:沒有正向行為的 item,并非都是真實的負(fù)例,簡單粗暴處理會帶來 false negative。在曝光偏差產(chǎn)生的場景中,有的是將未展現(xiàn)給用戶的 item,進(jìn)行隨機負(fù)采樣作為用戶的負(fù)反饋;有的是將展現(xiàn)但未產(chǎn)生互動行為的 item 作為用戶的負(fù)反饋,兩者都會帶來偏差。
- 典型場景:使用隱式反饋的電商/視頻等推薦。
Selection Bias(選擇偏差):
- 概念解釋:存在于基于顯式反饋(explicit feedback)建模的場景中(比如商品評分),用戶傾向于對喜好的 item 進(jìn)行評分,并且用戶傾向于對非常好或非常壞的 item 進(jìn)行評分。因此,所觀察到的評分結(jié)果的數(shù)據(jù)分布,并不是真實的全量分布。
- 負(fù)面影響:觀測數(shù)據(jù)的分布是有偏的。
- 典型場景:預(yù)測用戶對電影的評分。
還有其他的 bias 比如 Conformity Bias(人在社會環(huán)境中意見與群體趨同導(dǎo)致的偏差),Popularity Bias(高熱度 item 獲得的流量遠(yuǎn)超過合理水平,造成馬太效應(yīng)),不在該文中做更多討論。
上述 bias 的存在,給推薦系統(tǒng)的服務(wù)效果帶來了負(fù)面影響。在筆者看來,Position bias 和 Exposure Bias 是推薦系統(tǒng)中最重要和常見的兩類 bias。因此,下文針對這兩類 bias,介紹學(xué)術(shù)界過去提出的一些主流 debias(消除偏差)的解決方案。
以筆者之見,從技術(shù)方案的實現(xiàn)角度而言,Position bias 和 Exposure Bias 的主流 debias 方案可以歸類為曝光建模和樣本調(diào)權(quán)兩種思路。
- 曝光建模: 在理論上假設(shè),用戶顯式行為的發(fā)生可以解耦為“item 是否曝光給用戶”和“item 是否符合用戶偏好”兩個事件。在算法設(shè)計中,顯式地對“是否曝光”進(jìn)行建模,從而使模型真正地從數(shù)據(jù)樣本中,學(xué)習(xí)到 item 與用戶相關(guān)性的客觀規(guī)律。曝光建模思路的特點是,需要對“是否曝光”的依賴變量做一定假設(shè),并且需要實際數(shù)據(jù)樣本能反映出假設(shè)的規(guī)律,因此也需要樣本量足夠充分。
- 樣本調(diào)權(quán): 根據(jù)業(yè)務(wù)場景的特性,對不同的樣本賦予不同的權(quán)重,特別是對置信度較小的樣本(例如隱式反饋場景中的負(fù)例)賦予較小的權(quán)重,使得樣本層面上反映出的 bias 得到減輕。另外,根據(jù)業(yè)務(wù)場景中 bias 的產(chǎn)生機理,對于觀測到的樣本,重新定義損失函數(shù),使其近似趨近于無偏的情況,也是一種 debias 的思路。由于重新定義損失函數(shù)的做法,本質(zhì)上也是改變了不同樣本的權(quán)重,本文將這一思路歸類到樣本調(diào)權(quán)的思路下。樣本調(diào)權(quán)思路的特點是,需要較強的人工經(jīng)驗和業(yè)務(wù)理解。
需要注意的是,兩種思路并沒有絕對的區(qū)別。在某些方案中,建模了曝光概率,同時利用模型預(yù)估得到的曝光概率對樣本進(jìn)行調(diào)權(quán)。因為這類思路依賴于對曝光的建模,本文將其歸類到曝光建模之下。
本文內(nèi)容組織主要參考綜述文獻(xiàn) Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. Bias and Debias in Recommender System: A Survey and Future Directions [1].
本文后續(xù)內(nèi)容安排如下:
- 曝光建模: 介紹曝光建模思路分別在 position bias 和 exposure bias 場景對應(yīng)的具體技術(shù)方案。在每個 bias 場景標(biāo)題的開頭,簡要回顧了 bias 的含義和產(chǎn)生機理。
- 樣本調(diào)權(quán): 介紹樣本調(diào)權(quán)思路分別在 position bias 和 exposure bias 場景的方案。其中,在 exposure bias 標(biāo)題下,將樣本調(diào)權(quán)的方案分為“啟發(fā)式調(diào)權(quán)”和“損失函數(shù)重定義”兩個方向進(jìn)行敘述。
- 評估指標(biāo)的 debias: 介紹在模型評估指標(biāo)(即 metrics)中消除偏差的思路。
曝光建模
Position bias
位置偏差在 learning-to-rank 系統(tǒng)中是一種常見偏差,它的基本假設(shè)是展現(xiàn)在靠前位置的 item 有更大概率被用戶點擊,無論 item 是否符合用戶偏好,在廣告系統(tǒng)和搜索排序場景中都比較常見。
對 position bias 采用曝光建模來 debias,思路是,將用戶點擊行為發(fā)生的中間過程拆分出來,對中間的曝光事件進(jìn)行建模,并利用這些中間過程的模型預(yù)測值進(jìn)行消偏。如何去拆分點擊的中間過程,就涉及到了不同的假設(shè),對應(yīng)著不同的具體方案。
其中一個比較有影響力的方案是PAL(Position-bias Aware Learning)模型 [2],該模型假設(shè):
- 用戶(u)點擊(C,click)事件的發(fā)生,是 item(i)被用戶注意到(E,examined)且 item 有一定概率符合用戶偏好(relevant)兩者同時滿足的結(jié)果;
- 一旦 item 被用戶注意到(E),那么用戶點擊(C)item 的概率,僅僅于 item 與用戶本身有關(guān),而與位置無關(guān);
- item 被用戶注意到的概率(E),僅僅與 item 所在的 position(p)有關(guān), 而與 item 是否符合用戶偏好無關(guān).
總結(jié)起來就是:
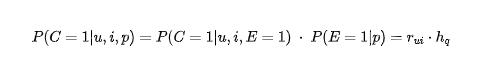
其中,r_ui 是用戶與 item 是否符合的真正概率,h_q 是僅依賴于位置的 item 被用戶注意到的概率。令模型分別建模這兩個行為,然后只取 r_ui 作為線上服務(wù)時排序的依據(jù)。
具體來說,如下圖所示,在深度學(xué)習(xí)模型中,使用位置相關(guān)的特征輸入構(gòu)建一個 tower,其他特征輸入構(gòu)建另一個 tower,兩個 tower 的最終輸出分別經(jīng)過 sigmoid 之后,相乘到一起(pCTR * ProbSeen),作為一個用于計算 loss 的輸出(bCTR)。當(dāng)模型訓(xùn)練時,樣本 label 與 bCTR 計算得到 loss,用于梯度的反向傳播。而在線上預(yù)估服務(wù)時,僅使用 pCTR 的預(yù)估值,因為它是去除了 position 之后的消偏結(jié)果。
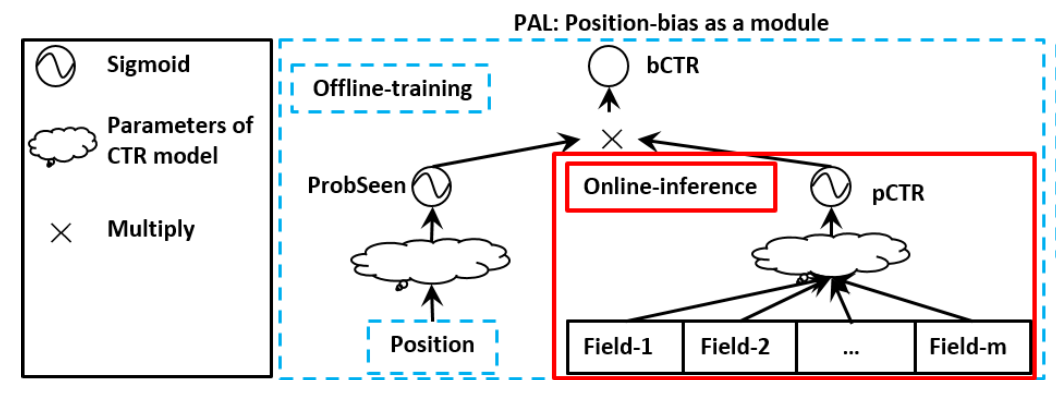
圖 2. PAL 模型示意圖(來自文獻(xiàn)[2])
另一種思路類似的方案是采用級聯(lián)模型(cascade model)[3]。該方案假設(shè)用戶從靠前位置到靠后位置,按順序逐個地瀏覽 item,那么是否點擊某個位置上的 item,就與該位置以及之前所有位置上的 item 有關(guān)。令 E_q 和 C_q 分別代表 q 位置上 item 曝光和被點擊的概率。級聯(lián)模型描述用戶行為的發(fā)生是如下的關(guān)系:

其中,第三個等式假設(shè)了用戶一旦點擊了處于 q 位置的 item,那么就會終止本次閱讀的過程,不再往下瀏覽,否則用戶還會繼續(xù)往下瀏覽。該方案也假設(shè)了在每次瀏覽過程(session)中,最多只能有一次點擊。
級聯(lián)模型建模各個位置處的 E_q 和 C_q,同樣使用消偏之后的 r_uq,i 來作為真實的排序依據(jù)。
曝光建模的思路有兩個缺點,一是對點擊行為中間過程的拆分需要大量的數(shù)據(jù)來支持模型學(xué)習(xí),尤其是 user-item 之間的數(shù)據(jù)是較為稀疏的,在一些數(shù)據(jù)量偏少的場景中使用難度大;二是引入了人為假設(shè),如果假設(shè)不正確,那么就會導(dǎo)致最終結(jié)果與預(yù)期的南轅北轍。
Exposure Bias
Exposure bias(曝光偏差)產(chǎn)生于需要利用用戶的隱式反饋(implicit feedback)來建模的場景中。用戶的顯式行為(比如點擊、評論、收藏)只會發(fā)生在極少數(shù)的 item 上,因為用戶只會被到少量的 item 曝光到。因此,把未觀察到互動行為的 item 都作為用戶的負(fù)反饋,會造成偏差(positive-unlabelled問題)。另一方面,高熱的 item 相對中長尾 item,獲得了更多的曝光,更可能產(chǎn)生顯式正向行為的樣本。因此所觀測數(shù)據(jù)中的正向行為,是非隨機缺失的(Missing-not-at-Random,MNAR問題),與真實分布不一致。
因為 exposure bias 產(chǎn)生的直接原因是濫用了并非真實的負(fù)樣本,在這些負(fù)樣本中無法直接區(qū)分哪些是曝光了但用戶不感興趣了、哪些是沒有實際上曝光的。那么,如果能對 item 是否曝光進(jìn)行建模,然后削弱那些曝光概率低的負(fù)樣本的權(quán)重,是會減輕 bias 的影響的。
具體地,訓(xùn)練模型學(xué)習(xí)一個 item 是否曝光給用戶的概率,item 曝光的概率越高(對應(yīng)地,item 在客戶端展現(xiàn)的次數(shù)越多),那么說明 item 對應(yīng)的隱式反饋樣本的置信度也就越大。因此,可以將模型學(xué)習(xí)到的曝光概率賦值給損失函數(shù)里面樣本的權(quán)重。
在早期樸素的 WMF 思路影響下,研究者考慮在矩陣分解的過程中,加入 item 是否曝光給用戶的隱變量 O_ui, 通過模型學(xué)習(xí)到 O_ui,來更好地輔助損失函數(shù)里面的權(quán)重賦值[12],被稱為ExMF(Exposure Matrix Factorization,含有曝光的矩陣分解)方法。具體地,考慮如下的概率生成過程:

其中 N 表示高斯分布,Bern 表示伯努利分布,μ_u,i 是 item i 曝光給用戶 u 的概率,U,V 分別是儲存用戶向量和 item 向量的矩陣,

代表用戶 u 對 item i 的偏好程度;
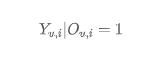
表示在用戶 u 被 item i 曝光后,是否與 item 產(chǎn)生顯式正向行為的變量;
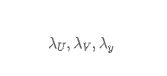
都是表達(dá)高斯分布方差的超參數(shù)。
要確定用戶和 item 矩陣 U,V 以及曝光矩陣 μ,就需要采用極大似然法最大化以下概率:
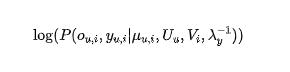
由于是否曝光{o_u,i}是隱變量,需要采用一個類似 EM 的算法來不斷更新參數(shù),最終,可以獲得 E[Ou,i|Yu,i=0]的先驗概率,來對損失函數(shù)中的樣本置信度賦值。
樣本調(diào)權(quán)
樣本調(diào)權(quán)思路,從邏輯上說是直觀的:在有 bias 的場景下,某些樣本攜帶的信息可信度小,但是不能完全丟棄它們,因此賦予較小權(quán)重,使得它們對模型整體的影響減輕;或者,同樣是展現(xiàn)給用戶的 item,某些 item 有更高的曝光幾率,它們的正反饋占比更高,因此它們的正樣本權(quán)重應(yīng)當(dāng)被削弱,而另外一些 item 的正樣本權(quán)重應(yīng)該被增強。
Position bias
Propensity Score(傾向性打分,下文簡稱 PS)是修正位置偏差的一種通用方法[4],在計算每條樣本的 loss 時,每條樣本基于它所在的位置被重新賦予了權(quán)重。這個權(quán)重是和位置相關(guān)的,該方案里正樣本對應(yīng)的 loss 函數(shù)被修正為:

對應(yīng)著在模型 f 下(u,i)這條樣本的 loss;ρ(q)是傾向性打分(即 PS),僅僅與位置 q 有關(guān),這也是傾向性打分這一方法中的一個重要假設(shè)。如果一個 item 展現(xiàn)的位置越靠前,它的 PS 就越高,那么這條樣本對應(yīng)的 loss 被降權(quán)得越厲害。同時,那么展現(xiàn)在靠后位置的 item,它們的 loss 將可能被加權(quán)。由于傾向性打分方法做了一個非常強的假設(shè)(傾向性打分僅僅與位置相關(guān), 而與用戶和 item 無關(guān)),因此估算各個位置上的 PS 就變得非常簡單。一個很直接的做法是 result randomization(結(jié)果隨機化):將模型排序的結(jié)果打亂,展現(xiàn)在用戶面前,然后收集各個位置上的用戶點擊率。因為在各個位置上,item 與用戶的相關(guān)性已經(jīng)是均等的了,因此不同位置上的點擊率就是各個位置上的傾向性打分的無偏估計。但是這種做法對自然推薦的結(jié)果進(jìn)行了人為干預(yù),有損用戶體驗,并不是一個最優(yōu)的辦法。除了這種簡單粗暴的 result randomization 之外,人們也提出了一些基于模型的方法來學(xué)習(xí)各個位置上的傾向性得分。將 item 是否被用戶注意到作為一個隱變量,設(shè)計了一個包含傾向性打分模型和推薦模型的 EM 算法來求解該問題。[5,6]
Exposure Bias
在利用隱式反饋的場景中,為了提取負(fù)反饋的信息,一般會將未觀察到顯式反饋的 item 一律作為負(fù)例,然后對每個負(fù)例賦予一定的置信度。對應(yīng)的損失函數(shù)表達(dá)如下:
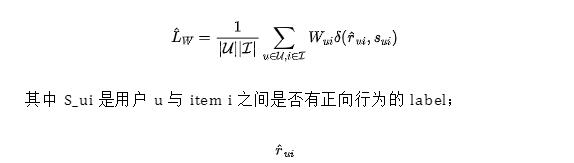
是推薦模型 r 預(yù)估的正向行為發(fā)生概率;W_ui 是表達(dá)置信度的權(quán)重;δ 是損失函數(shù)的具體表達(dá)式(比如交叉熵代價函數(shù))。在模型訓(xùn)練中的 debias 相關(guān)思路,一般是圍繞如何給隱式反饋的負(fù)例賦予恰當(dāng)?shù)臋?quán)重來進(jìn)行的。
啟發(fā)式調(diào)權(quán)
對隱式反饋的負(fù)例進(jìn)行調(diào)權(quán),針對的更多是 positive-unlabeled 問題。一個早期的樸素思路是加權(quán)分解矩陣(weighted factorization matrix,簡稱 WMF)[8]。該思路采用:
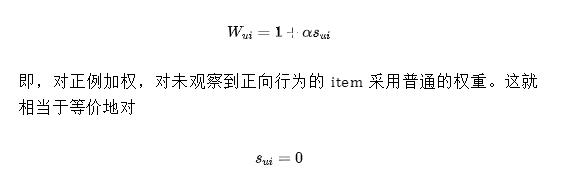
的樣本降權(quán)。這種做法背后的動機是,未觀察到正向行為的樣本,無法確定用戶是否真的不喜歡,因此需要降低樣本的置信度。
在此基礎(chǔ)上利用更多的用戶信息或 item 信息,提出的其他方案包括:利用用戶的活躍度進(jìn)行權(quán)重賦值:

因為有更多正向行為的用戶,其對應(yīng)的樣本的置信度越大[9];利用 item 的熱度進(jìn)行權(quán)重賦值,因為越流行的 item,有更高的幾率曝光,樣本的置信度也應(yīng)當(dāng)越大[10];利用用戶與 item 的特征相似度來確定權(quán)重[11]。
雖然方法眾多,啟發(fā)式調(diào)權(quán)仍然是一個有較大難度的方案,其一是用戶與 item 之間隱式反饋樣本的置信度的確定,需要大量數(shù)據(jù)與計算資源;其二是權(quán)重的設(shè)定,也引入了人為的經(jīng)驗與假設(shè),如果人為的經(jīng)驗就是帶有偏差的,那么會加重偏差。
損失函數(shù)重定義
在 exposure-based model 方案中,曝光概率越高的 item,對應(yīng)的樣本的置信度越高。但是它沒有處理另一個問題,那就是隱式反饋建模中的非隨機缺失(missing not at random)問題。
高曝光概率 item,一般也是高熱度的 item。通過調(diào)大它們的樣本的權(quán)重,模型將會偏向于對高熱度的 item 學(xué)習(xí)更準(zhǔn),而在中長尾的 item 上的學(xué)習(xí)變差。
因此,將是否曝光與曝光后是否發(fā)生顯式反饋這兩個變量進(jìn)行進(jìn)一步的解耦,并重新定義損失函數(shù),使之完全依賴于客觀的 user-item 相關(guān)性,是一種更進(jìn)一步的思路[13]。
基于以上的動機,研究者將顯式反饋的發(fā)生解耦為“曝光”(O_u,i = 1)與“item 符合用戶偏好”(R_u,i = 1)同時發(fā)生。
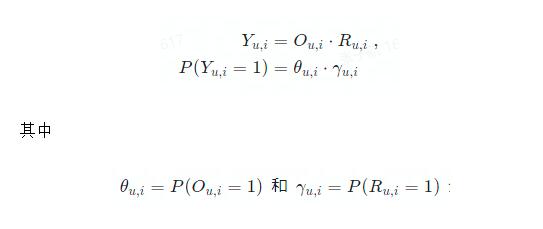
分別表示 item i 曝光給用戶 u 的概率,和 item i 符合用戶 u 的偏好的概率(又稱 item 與用戶的相關(guān)性)。
如果把模型的評估指標(biāo),從擬合 click 數(shù)據(jù):

其中 δ(·)為具體的損失函數(shù)(比如交叉熵代價函數(shù));
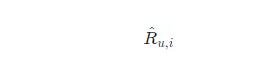
為模型預(yù)估的用戶 u 與 item i 的相關(guān)性;
括號里的兩項分別代表 item 與用戶有相關(guān)性,或沒有相關(guān)性的預(yù)估損失。
可以證明的是,以上兩種方法(Heuristic Weighting 和 Exposure-based model)定義的損失函數(shù),都不是上述理想損失函數(shù)的無偏估計。
實際上,可以證明,理想損失函數(shù)的無偏估計的表達(dá)式為:

那么,問題就轉(zhuǎn)移到了,如何去估計 item i 對用戶 u 的曝光概率,這是一個傾向性打分的估計問題。最簡單的做法是,使用 item 的相對熱度來估算傾向性打分,即:
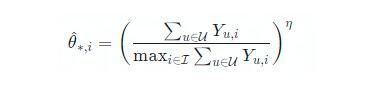
其中分母是正向行為次數(shù)最多的 item 對應(yīng)的總次數(shù),分子是當(dāng)前 item 的正向行為次數(shù)。?≤1 作為一個超參數(shù)來調(diào)節(jié)曝光概率的大小,因為相對于統(tǒng)計得到的后驗點擊率,曝光概率應(yīng)當(dāng)大于后驗點擊率。需要注意到,這個估算是對用戶無差別的,存在一定局限性。(文獻(xiàn)[13]中的做法)更多地傾向性打分的估算思路,可以參考上文“啟發(fā)式調(diào)權(quán)”。
評估指標(biāo)的 debias
在樣本層面就包含了 bias 的場景中,人們把所有樣本一視同仁地加入到模型的評估指標(biāo)中,也會造成評估指標(biāo)的 bias,所以需要矯正評估指標(biāo)當(dāng)中的偏差。
一個比較直接的辦法是利用 inverse propensity score(傾向性打分的倒數(shù),下文簡稱 IPS)來矯正評估指標(biāo)中的偏差[7]。從直觀上去理解 IPS 方法,即對那些頻繁出現(xiàn)的 item 降權(quán),而對那些較少出現(xiàn)的 item 做加權(quán)。
對于推薦系統(tǒng)而言,理想情況下的評估指標(biāo)都可以表達(dá)成如下的形式:

U 是用戶 u 的集合,c(·)是待評估指標(biāo)的具體表達(dá)式,與指標(biāo)定義有關(guān),比如對于 AUC 來說,它的表達(dá)式為:

表示用戶對曝光的 item 發(fā)生了正向行為的 item 集合;指標(biāo)的下角標(biāo) AOA 表示 Average-over-all。可以發(fā)現(xiàn),在實際的評估指標(biāo)中,指標(biāo)也受曝光變量 O 的影響。
曝光變量 O_ui 即 item i 是否曝光給用戶 u,并不是無偏的,往往高熱 item 更可能曝光給用戶。具體來說,會導(dǎo)致


該指標(biāo)被證明了在數(shù)據(jù)量 n 極大的情況下,將會收斂到
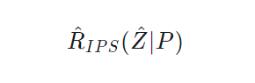
在該框架下,問題即轉(zhuǎn)換成為了如何去估計 IPS,則成為一個較為開放的問題,有相關(guān)的各種解決方案。(參考上文“啟發(fā)式調(diào)權(quán)”)
參考文獻(xiàn)
[1] Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2020. Bias and Debias in Recommender System: A Survey and Future Directions.
[2] Huifeng Guo, Jinkai Yu, Qing Liu, Ruiming Tang, Yuzhou Zhang. 2019. PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems.
[3] Nick Craswell, Onno Zoeter, Michael Taylor, and Bill Ramsey. 2008. An experimental comparison of click position-bias models.
[4] Aman Agarwal, Kenta Takatsu, Ivan Zaitsev, and Thorsten Joachims. 2019. A general framework for counterfactual learning-to-rank.
[5] Qingyao Ai, Keping Bi, Cheng Luo, Jiafeng Guo, and W Bruce Croft. 2018. Unbiased learning to rank with unbiased propensity estimation.
[6] Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. 2017. Unbiased learning-to-rank with biased feedback.
[7] LongqiYang, YinCui, YuanXuan, ChenyangWang, SergeBelongie, and DeborahEstrin. 2018. Unbiased offline recommender evaluation for missing-not-at-random implicit feedback.
[8] Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative filtering for implicit feedback datasets.
[9] Rong Pan and Martin Scholz. 2009. Mind the gaps: weighting the unknown in large-scale one-class collaborative filtering.
[10] Xiangnan He, Hanwang Zhang, Min-Yen Kan, and Tat-Seng Chua. 2016. Fast matrix factorization for online recommendation with implicit feedback.
[11] Yanen Li, Jia Hu, ChengXiang Zhai, and Ye Chen. 2010. Improving one-class collaborative filtering by incorporating rich user information.
[12] Dawen Liang, Laurent Charlin, James McInerney, and David M Blei. 2016. Modeling user exposure in recommendation.
[13] Yuta Saito. 2020. Unbiased Pairwise Learning from Biased Implicit Feedback.

























