一文梳理視覺Transformer架構(gòu)進(jìn)展:與CNN相比,ViT贏在哪兒?
Transformer 作為一種基于注意力的編碼器 - 解碼器架構(gòu),不僅徹底改變了自然語言處理(NLP)領(lǐng)域,還在計(jì)算機(jī)視覺(CV)領(lǐng)域做出了一些開創(chuàng)性的工作。與卷積神經(jīng)網(wǎng)絡(luò)(CNN)相比,視覺 Transformer(ViT)依靠出色的建模能力,在 ImageNet、COCO 和 ADE20k 等多個(gè)基準(zhǔn)上取得了非常優(yōu)異的性能。
近日,一位名為 Nikolas Adaloglou 的博主撰寫了一篇博客長(zhǎng)文,綜述了 ViT 領(lǐng)域的進(jìn)展以及 ViT 與其他學(xué)科的交叉應(yīng)用。

本文作者 Nikolas Adaloglou。
Nikolas Adaloglou 是一名機(jī)器學(xué)習(xí)工程師,他對(duì)和 AI 相關(guān)的 3D 醫(yī)學(xué)成像、圖像和視頻分析、基于圖的深度學(xué)習(xí)模型以及生成式深度學(xué)習(xí)感興趣,致力于借助機(jī)器學(xué)習(xí)推動(dòng)醫(yī)學(xué)工程的發(fā)展。
以下是博客原文:
ViT 的靈感來源于自然語言處理中的自注意力機(jī)制,其中將詞嵌入替換成了 patch 嵌入。
以合理的規(guī)模訓(xùn)練 ViT
知識(shí)蒸餾
在 Kaggle 等深度學(xué)習(xí)競(jìng)賽中,集成(ensemble)是非常流行的一種方法。集成大體上是指平均多個(gè)已訓(xùn)練模型的輸出以進(jìn)行預(yù)測(cè)。這種簡(jiǎn)單的方法非常適合提高測(cè)試時(shí)的性能,然而它在推理過程中會(huì)慢 N 倍(其中 N 表示模型數(shù)量)。當(dāng)在嵌入式設(shè)備中部署此類神經(jīng)網(wǎng)絡(luò)時(shí),這就成了一個(gè)棘手的問題。解決這個(gè)問題常用的一種方法是知識(shí)蒸餾。
在知識(shí)蒸餾中,小模型(學(xué)生模型)通常是由一個(gè)大模型(教師模型)監(jiān)督,算法的關(guān)鍵是如何將教師模型的知識(shí)遷移給學(xué)生模型。
盡管沒有足夠的基礎(chǔ)理論支持,但知識(shí)蒸餾已被證明是一種非常有效的技巧。關(guān)于為什么集成的輸出分布能提供與集成相當(dāng)?shù)臏y(cè)試性能,還有待發(fā)現(xiàn)。而使用集成的輸出(略有偏差的平滑標(biāo)簽)相對(duì)于真實(shí)標(biāo)簽存在性能增益,這更加神秘。
DeiT 模型通過注意力訓(xùn)練數(shù)據(jù)高效的圖像 Transformer 和蒸餾,這表明在沒有外部數(shù)據(jù)的情況下,僅在 ImageNet 上訓(xùn)練 ViT 是可以的。該研究使用來自 Resnet 的已訓(xùn)練好的 CNN 模型作為單一教師模型。直觀地講,強(qiáng)大的數(shù)據(jù)假設(shè)(歸納偏置)讓 CNN 比 ViT 更適合做教師網(wǎng)絡(luò)。
自蒸餾
令人驚訝的是,有研究發(fā)現(xiàn)類似方法也可以通過對(duì)同一架構(gòu)的單個(gè)模型(教師網(wǎng)絡(luò))進(jìn)行知識(shí)蒸餾來實(shí)現(xiàn)。這個(gè)過程被稱為自蒸餾,來自于 Zhang et al.2019 年的論文《Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation》。自蒸餾就是一種 N=1 的知識(shí)蒸餾,自蒸餾(使用具有相同架構(gòu)的單個(gè)訓(xùn)練模型)也可以提高測(cè)試準(zhǔn)確率。
ViT 的 Hard-label 蒸餾:DeiT 訓(xùn)練策略
在這種方法中,一個(gè)額外的可學(xué)習(xí)全局 token(即蒸餾 token),與 ViT 的 patch 嵌入相連。最關(guān)鍵的是,蒸餾 token 來自訓(xùn)練有素的教師 CNN 主干網(wǎng)絡(luò)。通過將 CNN 特征融合到 Transformer 的自注意力層中,研究者們?cè)?Imagenet 的 1M 數(shù)據(jù)上訓(xùn)練 DeiT。
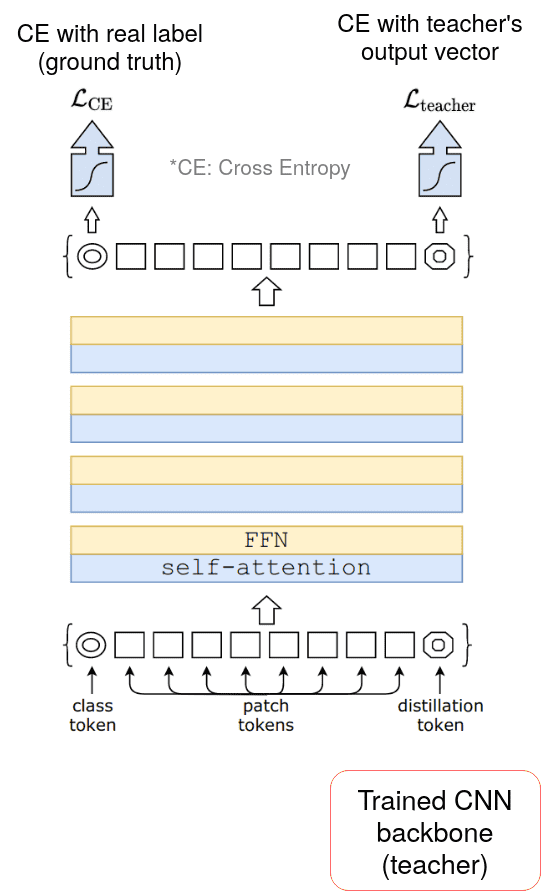
DeiT 模型概覽。
DeiT 使用如下?lián)p失函數(shù)進(jìn)行訓(xùn)練:
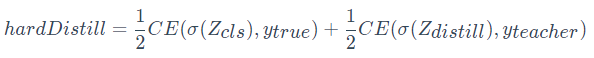
其中 CE 是交叉熵?fù)p失函數(shù),σ 是 softmax 函數(shù)。Z_cls 和 Z_distill 分別是來自類 token 和蒸餾 token 的學(xué)生模型的輸出,ytrue 和 yteacher 分別是 ground truth 和教師模型的輸出。
這種蒸餾技術(shù)使模型用更少的數(shù)據(jù)獲得超強(qiáng)的數(shù)據(jù)增強(qiáng),這可能會(huì)導(dǎo)致 ground truth 標(biāo)簽不精確。在這種情況下,教師網(wǎng)絡(luò)似乎會(huì)產(chǎn)生更合適的標(biāo)簽。由此產(chǎn)生的模型系列,即數(shù)據(jù)高效圖像 Transformer(DeiTs),在準(zhǔn)確率 / 步長(zhǎng)時(shí)間上與 EfficientNet 相當(dāng),但在準(zhǔn)確率 / 參數(shù)效率上仍然落后。
除了蒸餾,還有一些研究大量使用圖像增強(qiáng)來彌補(bǔ)缺乏可用的額外數(shù)據(jù)。此外,DeiT 依賴于隨機(jī)深度等數(shù)據(jù)正則化技術(shù)。最終,強(qiáng)大的增強(qiáng)和正則化限制了 ViT 在小數(shù)據(jù)機(jī)制中的過擬合趨勢(shì)。
Pyramid 視覺 Transformer
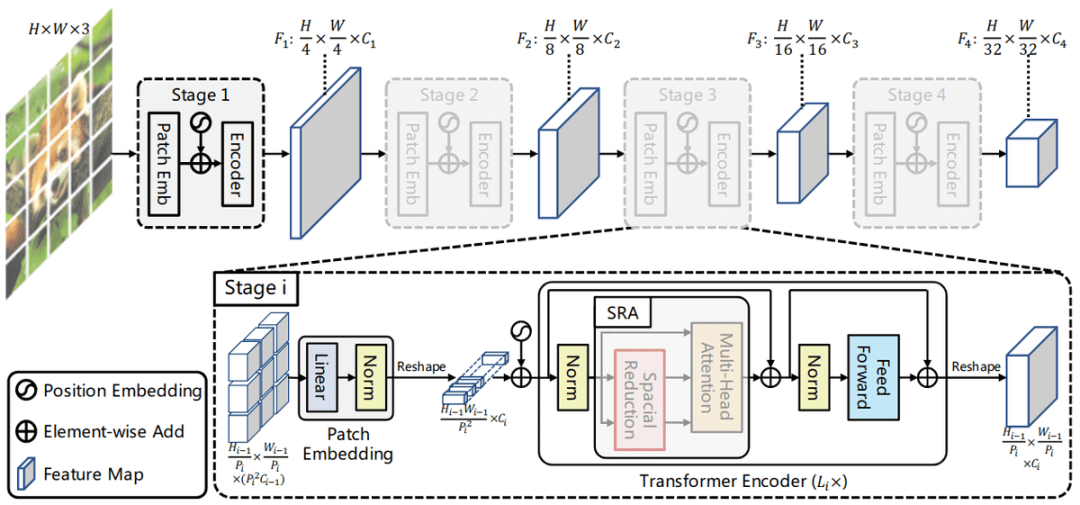
Pyramid 視覺 Transformer(PVT)的總體架構(gòu)。
為了克服注意力機(jī)制的二次復(fù)雜度,Pyramid 視覺 Transformer(PVT)采用一種稱為空間減少注意力 (SRA) 的自注意力變體。其特征是鍵和值的空間減少,類似于 NLP 領(lǐng)域的 Linformer 注意力。
通過應(yīng)用 SRA,整個(gè)模型的特征空間維度緩慢減少,并通過在所有 transformer block 中應(yīng)用位置嵌入來增強(qiáng)順序的概念。PVT 已被用作目標(biāo)檢測(cè)和語義分割的主干網(wǎng)絡(luò),以處理高分辨率圖像。
后來,該研究團(tuán)隊(duì)推出改進(jìn)版 PVT-v2,主要改進(jìn)如下:
- 重疊 patch 嵌入;
- 卷積前饋網(wǎng)絡(luò);
- 線性復(fù)雜度自注意力層。
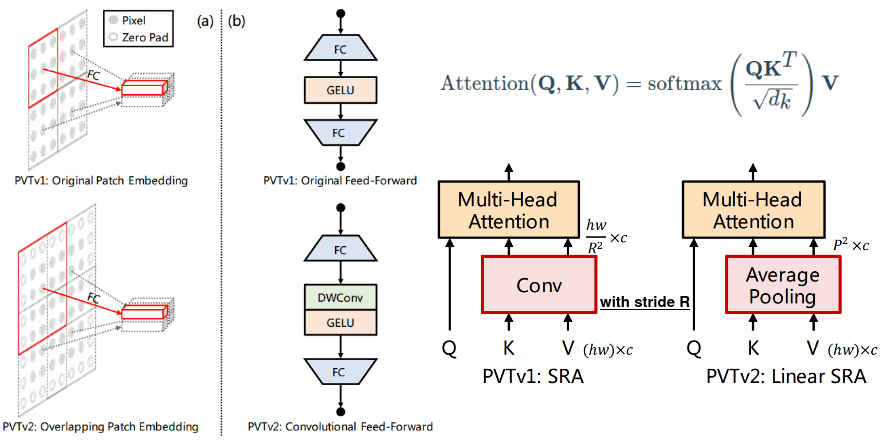
重疊 patch 是改進(jìn) ViT 的一個(gè)簡(jiǎn)單而通用的想法,尤其是對(duì)于密集任務(wù)(例如語義分割)。通過利用重疊區(qū)域 /patch,PVT-v2 可以獲得圖像表征的更多局部連續(xù)性。
全連接層(FC)之間的卷積消除了每一層中對(duì)固定大小位置編碼的需要。具有零填充(zero padding,p=1)的 3x3 深度卷積 (p=1) 旨在補(bǔ)償模型中位置編碼的移除(它們?nèi)匀淮嬖冢淮嬖谟谳斎胫校4诉^程可以更靈活地處理多種圖像分辨率。
最后,使用鍵和值池化(p=7),自注意力層就減小到了與 CNN 類似的復(fù)雜度。
Swin Transformer:
使用移位窗口的分層視覺 Transformer
Swin Transformer 旨在從標(biāo)準(zhǔn) NLP transformer 中建立局部性的思想,即局部或窗口注意力:
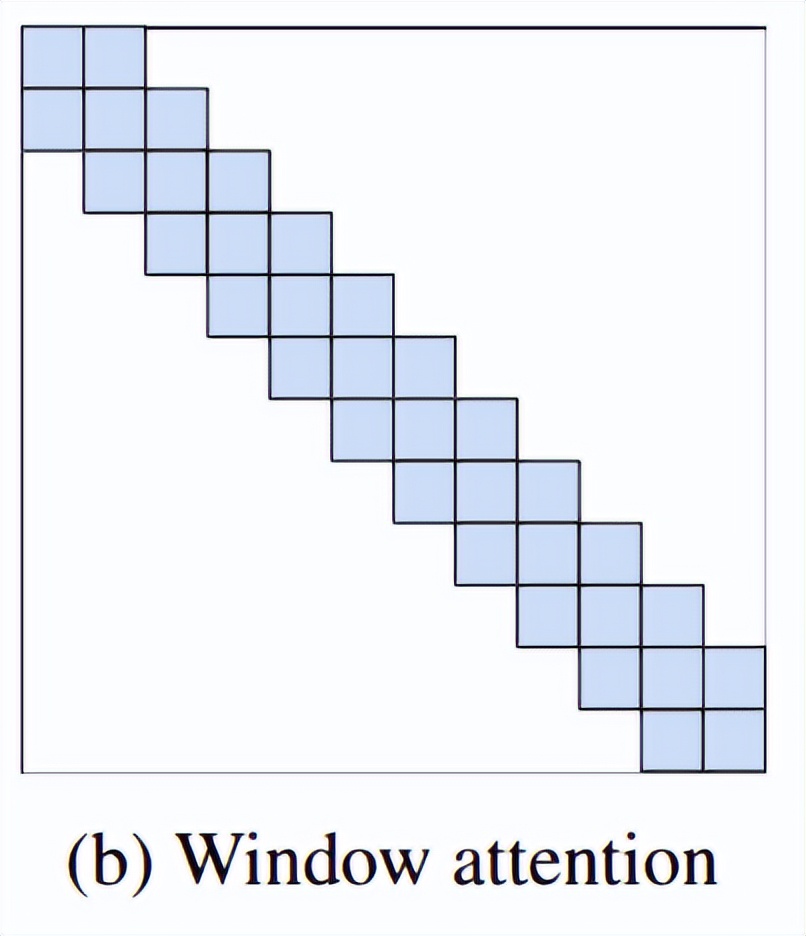
在 Swin Transformer 中,局部自注意力被用于非重疊窗口。下一層的窗口到窗口通信通過逐步合并窗口來產(chǎn)生分層表征。
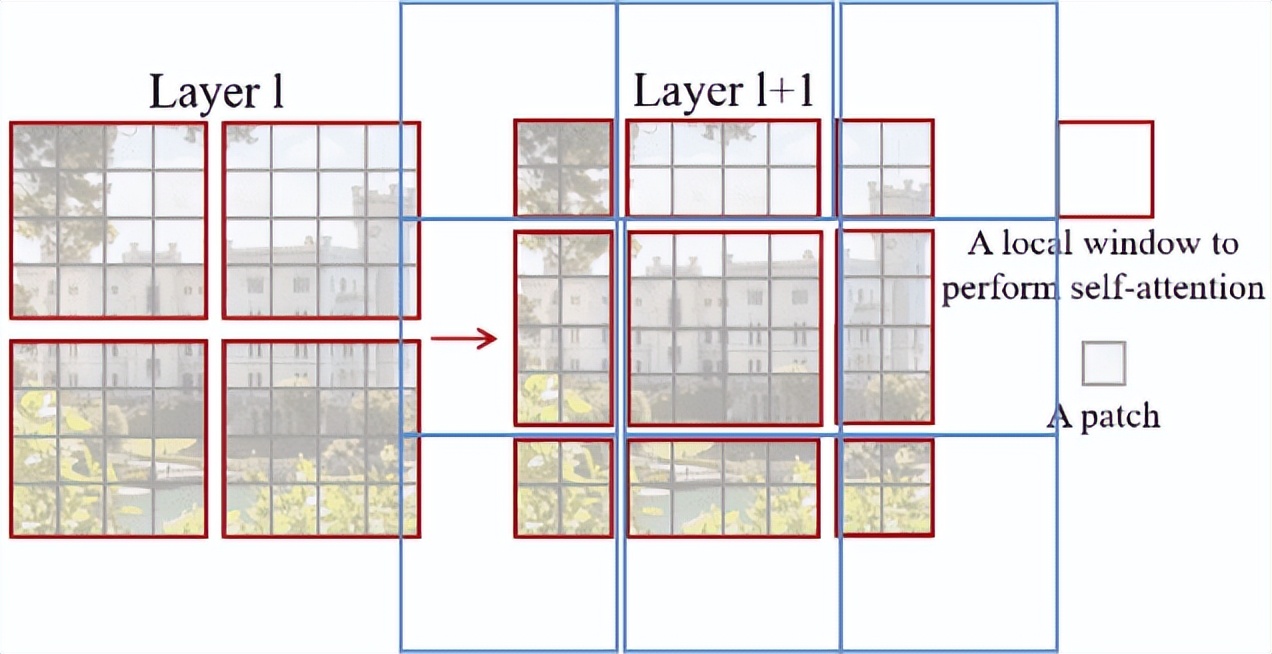
如上圖所示,左側(cè)是第一層的常規(guī)窗口分區(qū)方案,其中在每個(gè)窗口內(nèi)計(jì)算自注意力。右側(cè)第二層中的窗口分區(qū)被移動(dòng)了 2 個(gè)圖像 patch,導(dǎo)致跨越了先前窗口的邊界。
局部自注意力隨圖像大小線性縮放 O (M*N) 而不是 O (N^2),在用于序列長(zhǎng)度 N 和 M 窗口大小。
通過合并添加許多局部層,有一個(gè)全局表示。此外,特征圖的空間維度已顯著降低。作者聲稱在 ImageNet-1K 和 ImageNet-21K 上都取得了有希望的結(jié)果。
視覺 Transformer 的自監(jiān)督訓(xùn)練:DINO
Facebook AI 的研究提出了一個(gè)強(qiáng)大的框架用于訓(xùn)練大規(guī)模視覺數(shù)據(jù)。提議的自監(jiān)督系統(tǒng)創(chuàng)建了如此強(qiáng)大的表征,你甚至不需要在上面微調(diào)線性層。這是通過在數(shù)據(jù)集的凍結(jié)訓(xùn)練特征上應(yīng)用 K - 最近鄰 (NN) 來觀察到的。作者發(fā)現(xiàn),訓(xùn)練有素的 ViT 可以在沒有標(biāo)簽的情況下在 ImageNet 上達(dá)到 78.3% 的 top-1 準(zhǔn)確率。
該自監(jiān)督框架如下圖所示:
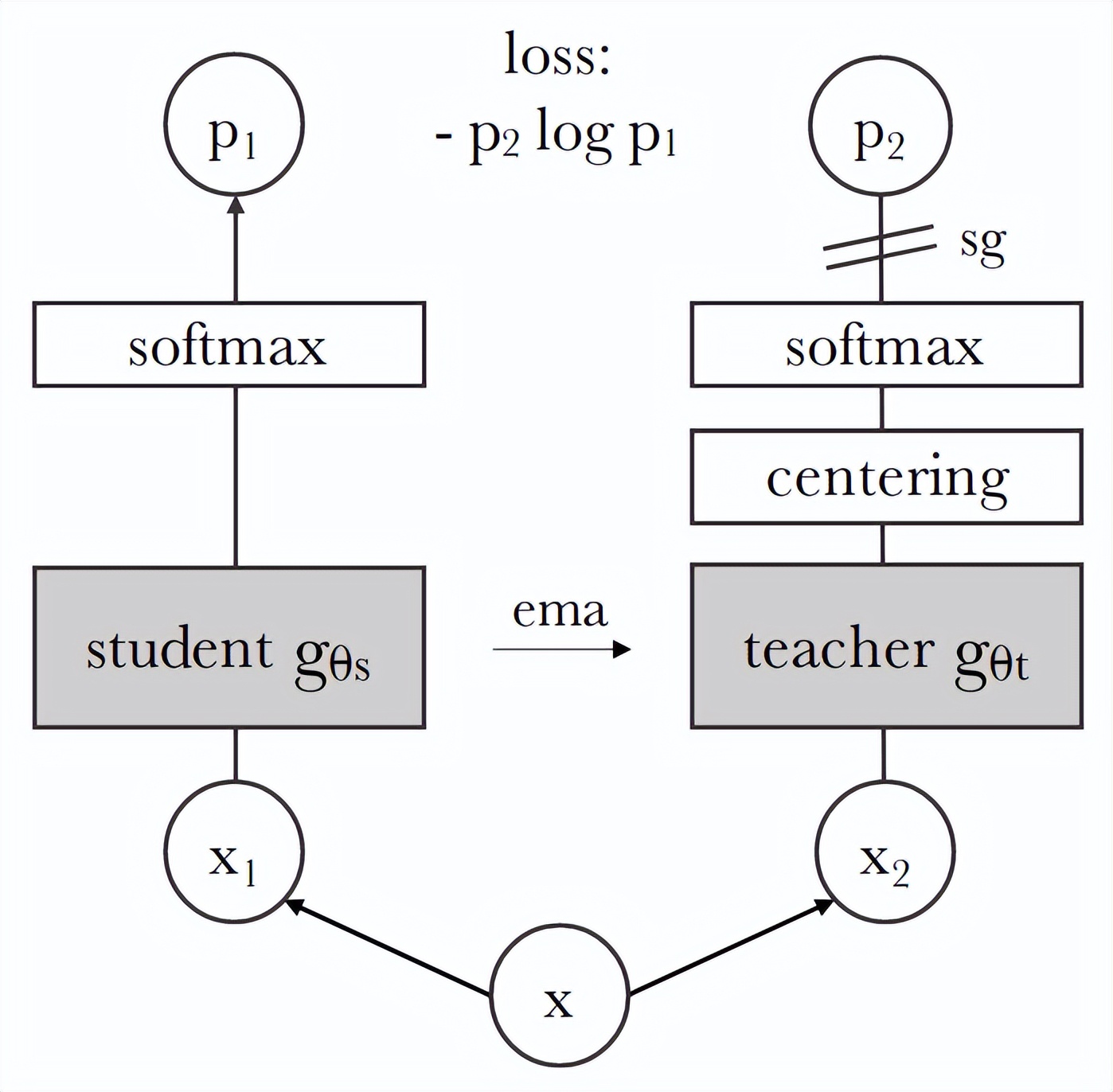
與其他自監(jiān)督模型相比,他們使用了交叉熵?fù)p失,就像在典型的自蒸餾場(chǎng)景中所做的那樣。盡管如此,這里的教師模型是隨機(jī)初始化的,其參數(shù)是根據(jù)學(xué)生參數(shù)的指數(shù)移動(dòng)平均值更新的。為了讓它 work,研究者將帶溫度參數(shù)的 softmax 應(yīng)用于具有不同溫度的教師和學(xué)生模型。具體來說,教師模型得到的溫度參數(shù)更小,這意味著更敏銳的預(yù)測(cè)。最重要的是,他們使用了從 SWAV 中獲得的多重裁剪方法,效果更佳,在這種情況下教師只能看到全局視圖,而學(xué)生可以訪問轉(zhuǎn)換后的輸入圖像的全局和局部視圖。
對(duì)于 CNN 架構(gòu)來說,該框架并不像對(duì)視覺 Transformer 那樣有益。那又該如何從圖像中提取什么樣的特征?

作者將經(jīng)過訓(xùn)練的 VIT 的自注意力頭輸出可視化。這些注意力圖說明模型自動(dòng)學(xué)習(xí)特定于類的特征,導(dǎo)致無監(jiān)督的對(duì)象分割,例如前景與背景。
此屬性也出現(xiàn)在自監(jiān)督預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)中,但需要一種特殊的方法來可視化特征。更重要的是,自注意力頭學(xué)習(xí)補(bǔ)充信息并通過為每個(gè)頭部使用不同的顏色來說明。默認(rèn)情況下,這根本不是通過自注意力獲得的。

DINO 多注意力頭可視化。
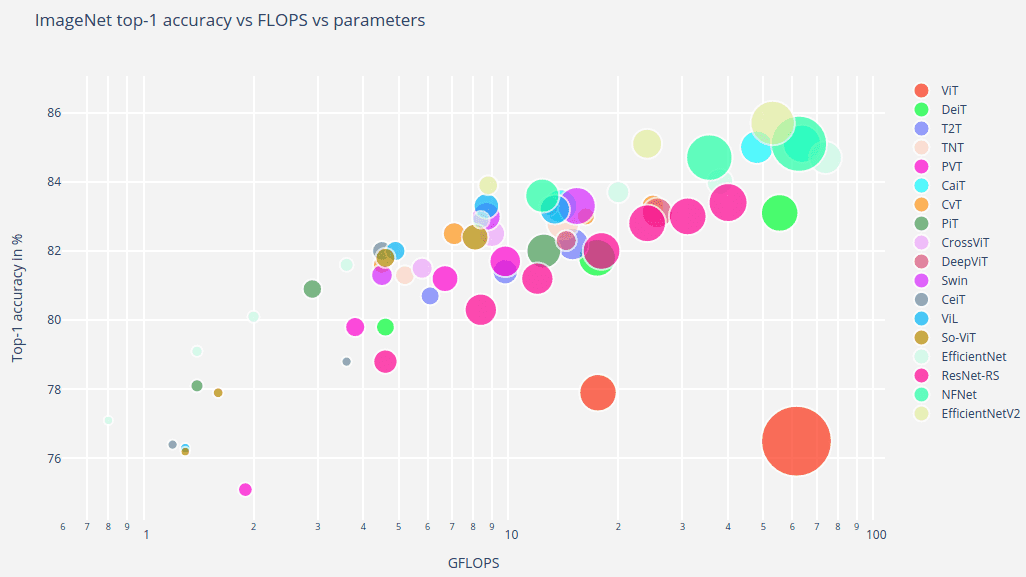
Scaling 視覺 Transformer
深度學(xué)習(xí)和規(guī)模是相關(guān)的。事實(shí)上,規(guī)模是很多 SOTA 實(shí)現(xiàn)的關(guān)鍵因素。在這項(xiàng)研究中,來自 Google Brain Research 的作者訓(xùn)練了一個(gè)稍微修改過的 ViT 模型,它有 20 億個(gè)參數(shù),并在 ImageNet 上達(dá)到了 90.45 % 的 top-1 準(zhǔn)確率。這種過度參數(shù)化的一般化模型在少樣本學(xué)習(xí)上進(jìn)行了測(cè)試,每類只有 10 個(gè)示例情況下。在 ImageNet 上達(dá)到了 84.86% 的 top-1 準(zhǔn)確率。
小樣本學(xué)習(xí)是指在樣本數(shù)量極其有限的情況下對(duì)模型進(jìn)行微調(diào)。小樣本學(xué)習(xí)的目標(biāo)通過將獲得的預(yù)訓(xùn)練知識(shí)稍微適應(yīng)特定任務(wù)來激勵(lì)泛化。如果成功地預(yù)訓(xùn)練了大型模型,那么在對(duì)下游任務(wù)非常有限的理解(僅由幾個(gè)示例提供)的情況下表現(xiàn)良好是有意義的。
以下是本文的一些核心貢獻(xiàn)和主要結(jié)果:
- 模型大小可能會(huì)限制表征質(zhì)量,前提是有足夠的數(shù)據(jù)來提供它;
- 大型模型受益于額外的監(jiān)督數(shù)據(jù),甚至超過 1B 圖像。
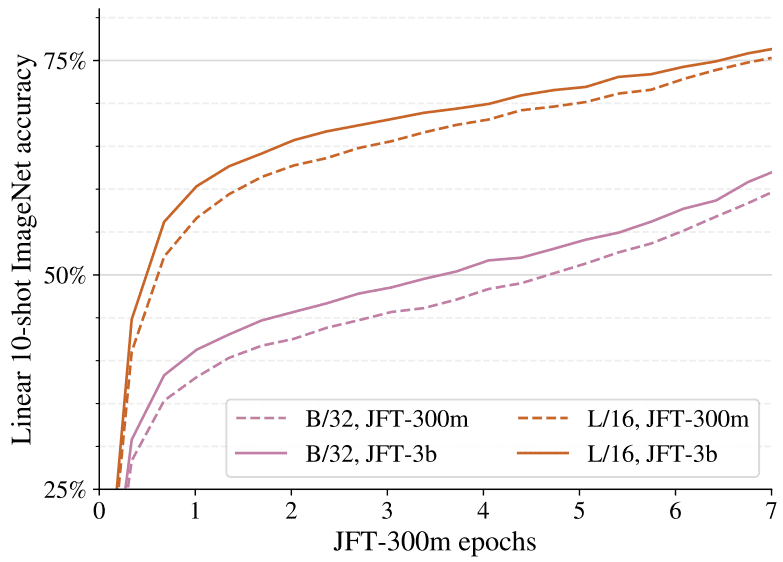
上圖描繪了從 300M 圖像數(shù)據(jù)集 (JFT-300M) 切換到 30 億圖像 (JFT-3B) 而不進(jìn)行任何進(jìn)一步縮放的效果。中型 (B/32) 和大型 (L/16) 模型都受益于添加數(shù)據(jù),大致是一個(gè)常數(shù)因子。結(jié)果是在整個(gè)訓(xùn)練過程中通過小樣本(線性)評(píng)估獲得的。
- 大模型的樣本效率更高,以更少的可見圖像達(dá)到相同的錯(cuò)誤率水平。
- 為了節(jié)省內(nèi)存,他們刪除了類 token (cls)。相反,他們?cè)u(píng)估了全局平均池化和多頭注意力池化,以聚合所有 patch token 的表征。
- 他們對(duì)頭部和稱為「主干」的其余層使用了不同的權(quán)重衰減。作者在下圖中很好地證明了這一點(diǎn)。框值是小樣本精度,而橫軸和縱軸分別表示主干和頭部的權(quán)重衰減。令人驚訝的是,頭部的更強(qiáng)衰減會(huì)產(chǎn)生最好的結(jié)果。作者推測(cè),頭部的強(qiáng)烈權(quán)重衰減會(huì)導(dǎo)致表示具有更大的類之間的余量。
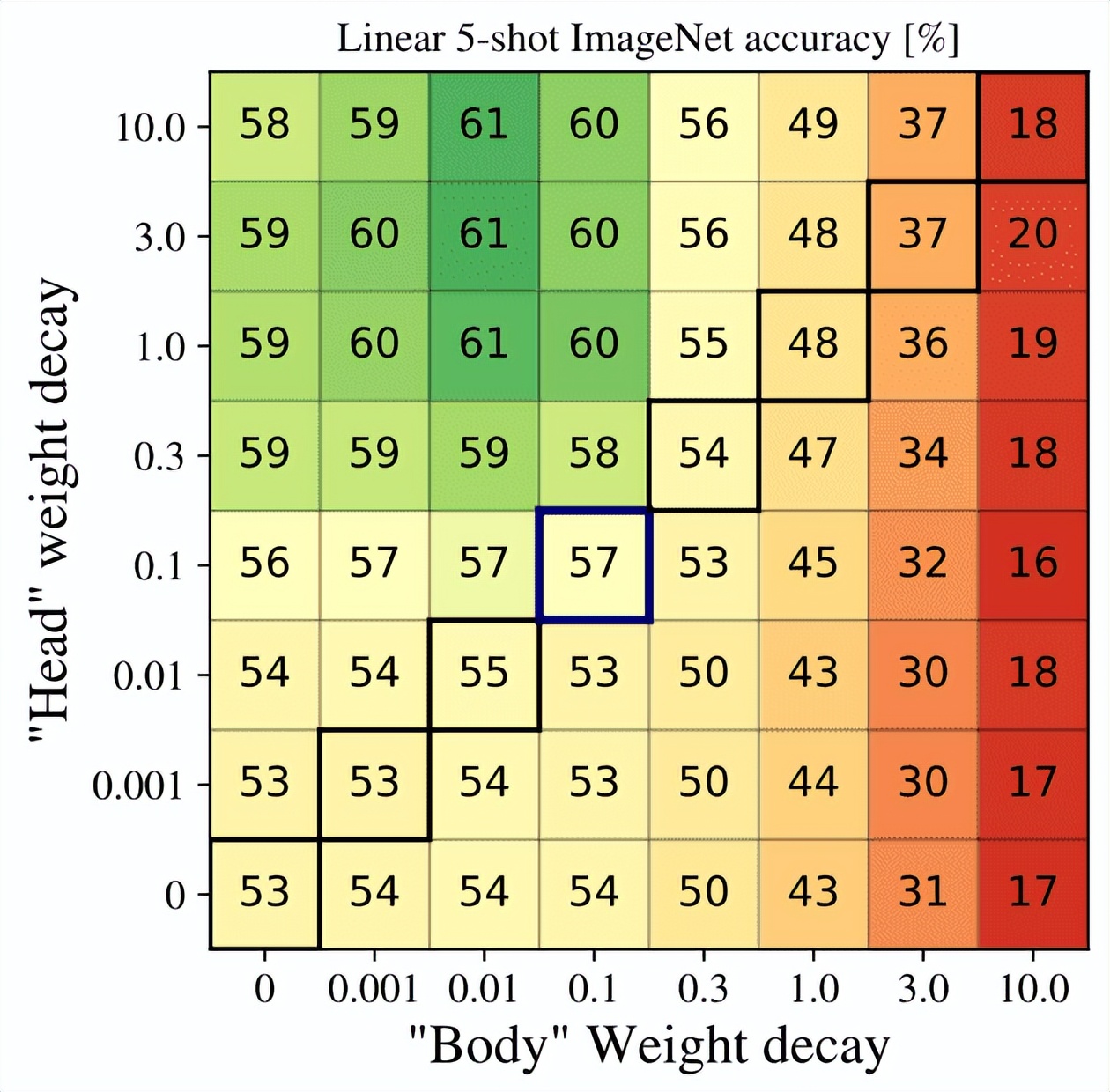
這或許是可以更廣泛地應(yīng)用于預(yù)訓(xùn)練 ViT 的最有趣的發(fā)現(xiàn)。
他們?cè)谟?xùn)練開始時(shí)使用了熱身階段,在訓(xùn)練結(jié)束時(shí)使用了冷卻階段,其中學(xué)習(xí)率線性退火為零。此外,他們使用了 Adafactor 優(yōu)化器,與傳統(tǒng)的 Adam 相比,內(nèi)存開銷為 50%。
在同一個(gè)波長(zhǎng),你可以找到另一個(gè)大規(guī)模的研究:《如何訓(xùn)練你的 ViT?視覺 Transformer 中的數(shù)據(jù)、增強(qiáng)和正則化》(How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers)
替代自注意力:獨(dú)立 token + 通道混合方式
眾所周知,自注意力可以作為一種具有快速權(quán)重的信息路由機(jī)制。到目前為止,有 3 篇論文講述了同樣的故事:用 2 個(gè)信息混合層替換自注意力;一種用于混合 token(投影 patch 向量),一種用于混合通道 / 特征信息。
MLP-Mixer
MLP-Mixer 包含兩個(gè) MLP 層:第一個(gè)獨(dú)立應(yīng)用于圖像 patch(即「混合」每個(gè)位置的特征),另一個(gè)跨 patch(即「混合」空間信息)。

MLP-Mixer 架構(gòu)。
XCiT:互協(xié)方差圖像 Transformer
另一個(gè)是最近的架構(gòu) XCiT,旨在修改 ViT 的核心構(gòu)建 block:應(yīng)用于 token 維度的自注意力。
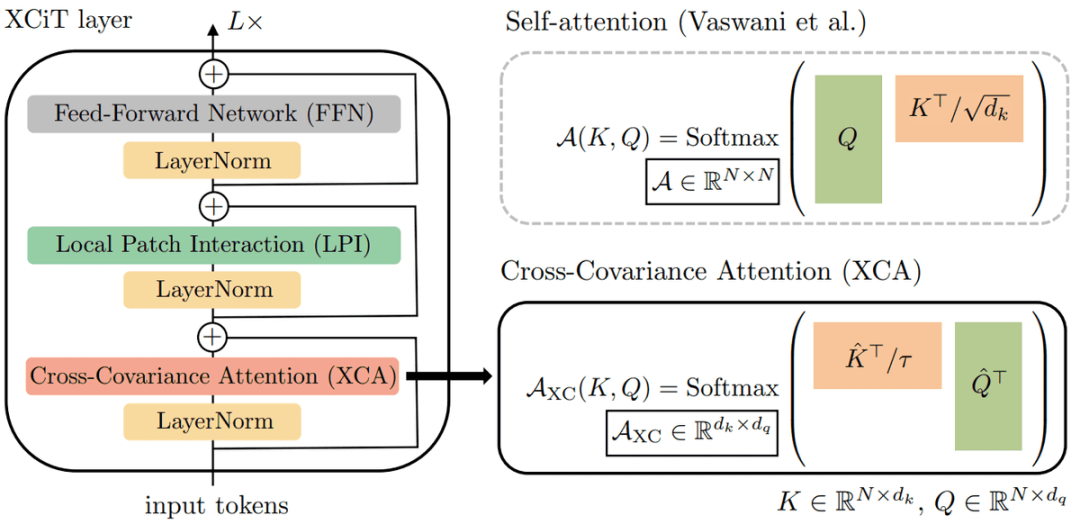
XCiT 架構(gòu)。
XCA:對(duì)于信息混合,作者提出了一種交叉協(xié)方差注意力 (XCA) 函數(shù),該函數(shù)根據(jù) token 的特征維度而不是根據(jù)其本身進(jìn)行操作。重要的是,此方法僅適用于 queries、keys、values 集的 L2 歸一化。L2 范數(shù)用 K 和 Q 字母上方的 hat 表示。乘法的結(jié)果在 softmax 之前也歸一化為 [-1,1] 。
局部 Patch 交互:為了實(shí)現(xiàn) patch 之間的顯式通信,研究者添加了兩個(gè) depth-wise 3×3 卷積層,中間有批歸一化和 GELU 非線性。Depth-wise 卷積獨(dú)立應(yīng)用于每個(gè)通道(這里的 patch)。
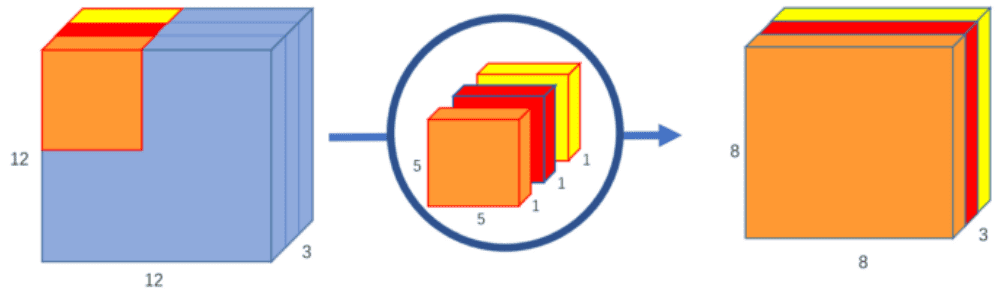
ConvMixer(加鏈接:patch 成為了 ALL You Need?挑戰(zhàn) ViT、MLP-Mixer 的簡(jiǎn)單模型來了)
自注意力和 MLP 理論上是更通用的建模機(jī)制,因?yàn)樗鼈冊(cè)试S更大的感受野和內(nèi)容感知行為。盡管如此,卷積的歸納偏差在計(jì)算機(jī)視覺任務(wù)中具有不可否認(rèn)的成果。
受此啟發(fā),研究者提出了另一種基于卷積網(wǎng)絡(luò)的變體,稱為 ConvMixer。主要思想是它直接對(duì)作為輸入的 patch 進(jìn)行操作,分離空間和通道維度的混合,并在整個(gè)網(wǎng)絡(luò)中保持相同的大小和分辨率。
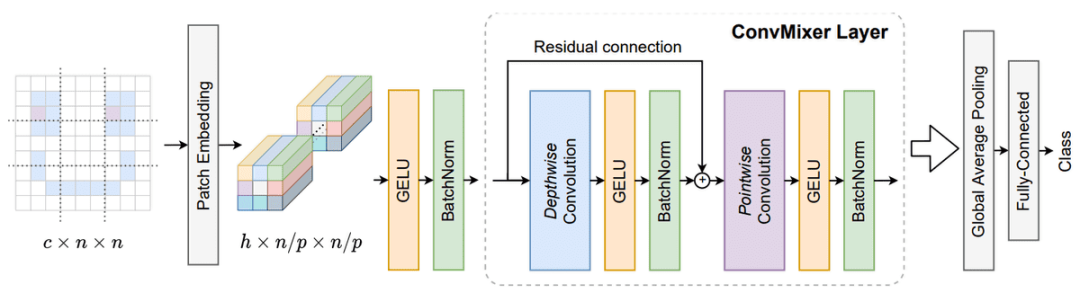
更具體地說,depthwise 卷積負(fù)責(zé)混合空間位置,而逐點(diǎn)卷積(1x1x 通道內(nèi)核)用于混合通道位置,如下圖所示:
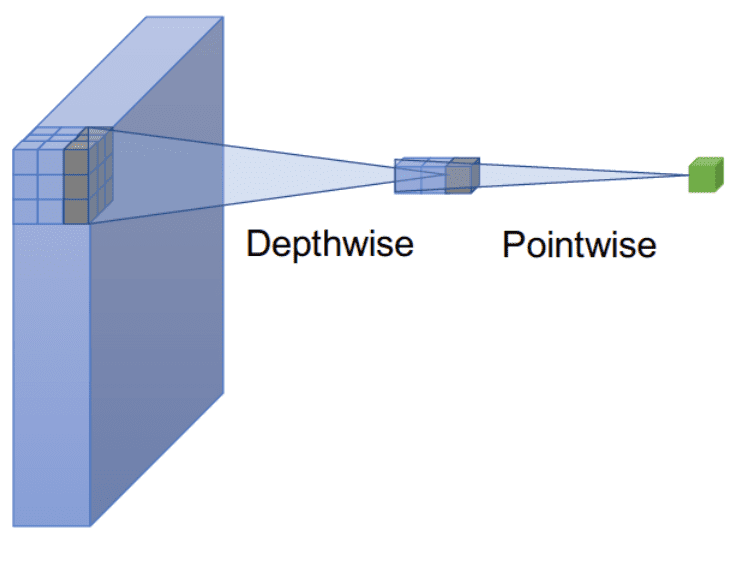
通過選擇較大的內(nèi)核大小來創(chuàng)建較大的感受野,可以實(shí)現(xiàn)遠(yuǎn)距離空間位置的混合。
多尺度視覺 Transformer
CNN 主干架構(gòu)受益于通道的逐漸增加,同時(shí)降低了特征圖的空間維度。類似地,多尺度視覺 Transformer (MViT) 利用了將多尺度特征層次結(jié)構(gòu)與視覺 Transformer 模型相結(jié)合的想法。在實(shí)踐中,作者從 3 個(gè)通道的初始圖像大小開始,逐漸擴(kuò)展(分層)通道容量,同時(shí)降低空間分辨率。
因此,創(chuàng)建了一個(gè)多尺度的特征金字塔。直觀地說,早期層將學(xué)習(xí)高空間與簡(jiǎn)單的低級(jí)視覺信息,而更深層負(fù)責(zé)復(fù)雜的高維特征。
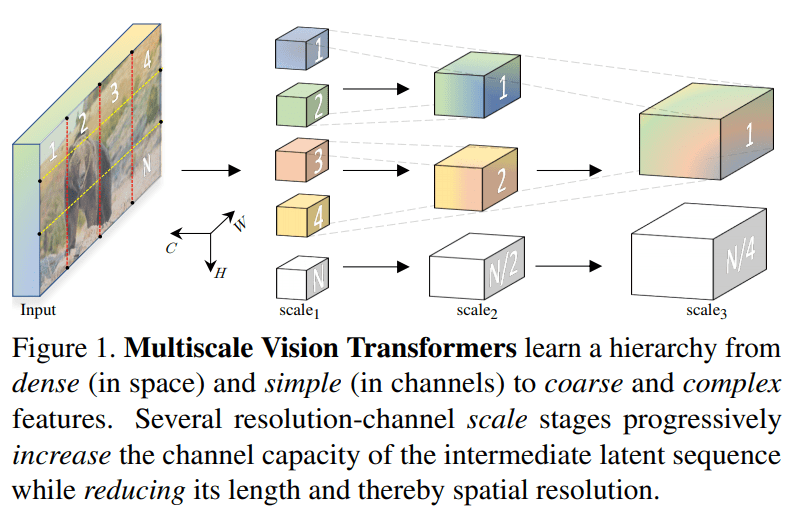
視頻分類:Timesformer
在圖像任務(wù)成功后,視覺 Transformer 被應(yīng)用于視頻識(shí)別。這里介紹兩種架構(gòu):
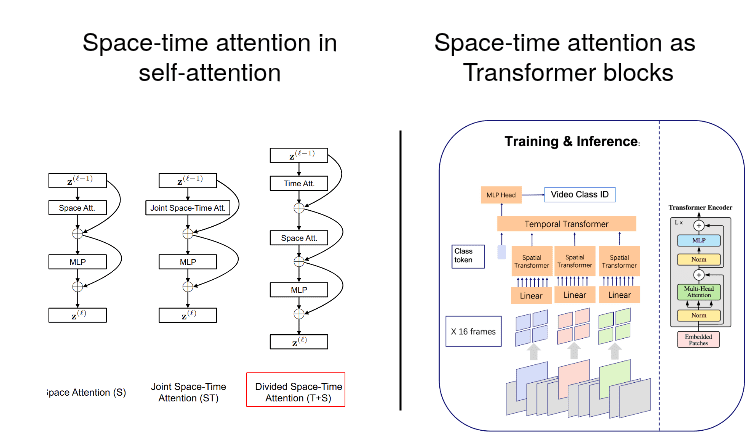
用于視頻識(shí)別的基于 block 與基于架構(gòu) / 基于模塊的時(shí)空注意力架構(gòu)。
- 右圖:縮小架構(gòu)級(jí)別。所提出的方法將空間 Transformer 應(yīng)用于投影圖像 block,然后有另一個(gè)網(wǎng)絡(luò)負(fù)責(zé)捕獲時(shí)間相關(guān)性。這類似于基于視頻處理的 CNN+LSTM 獲勝策略。
- 左圖:可以在自注意力級(jí)別實(shí)現(xiàn)的時(shí)空注意力,紅框中是最佳組合。通過首先將圖像幀視為 token 來在時(shí)域中順序應(yīng)用注意力。然后,在 MLP 投影之前應(yīng)用兩個(gè)空間維度的組合空間注意力。下面是該方法的 t-SNE 可視化:
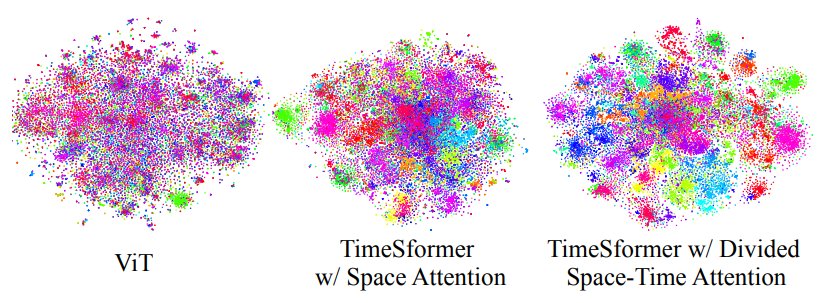
使用 Timesformer t-SNE 進(jìn)行特征可視化。
「每個(gè)視頻都可視化為一個(gè)點(diǎn)。屬于同一動(dòng)作類別的視頻具有相同的顏色。具有分割時(shí)空注意力的 TimeSformer 比具有僅空間注意力或 ViT 的 TimeSformer 在語義上學(xué)習(xí)更多可分離的特征。」
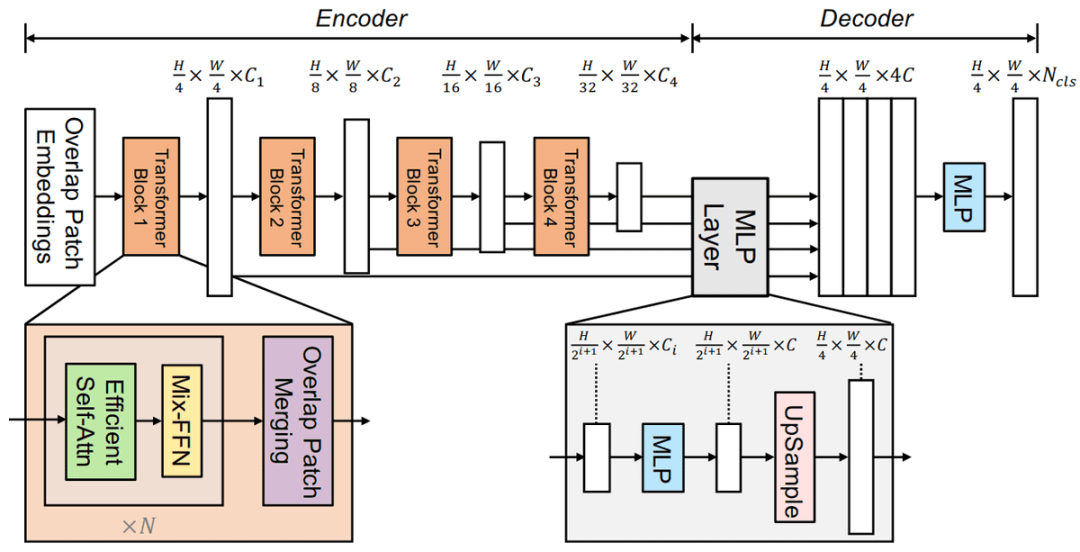
語義分割中的 ViT:SegFormer
英偉達(dá)提出了一種配置良好的設(shè)置,名為 SegFormer。SegFormer 的設(shè)計(jì)組件很有趣。首先,它由一個(gè)輸出多尺度特征的分層 Transformer 編碼器組成。其次,它不需要位置編碼,因?yàn)楫?dāng)測(cè)試分辨率與訓(xùn)練不同時(shí),這會(huì)降低性能。
SegFormer 使用一個(gè)超級(jí)簡(jiǎn)單的 MLP 解碼器來聚合編碼器的多尺度特征。與 ViT 不同的是,SegFormer 采用了小的圖像 patch,例如 4 x 4 這種,眾所周知,這有利于密集預(yù)測(cè)任務(wù)。所提出的 Transformer 編碼器輸出 1/4、1/8、1/16、1/32 多級(jí)特征的原始圖像分辨率。這些多級(jí)特征提供給 MLP 解碼器來預(yù)測(cè)分割掩碼。
Mix-FFN:為了減輕位置編碼的影響,研究者使用 零填充的 3 × 3 卷積層來泄漏位置信息。Mix-FFN 可以表述為:
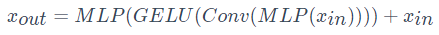
高效的自注意力是 PVT 中提出的,它使用縮減比率來減少序列的長(zhǎng)度。結(jié)果可以通過可視化有效感受野 (ERF) 來定性測(cè)量:
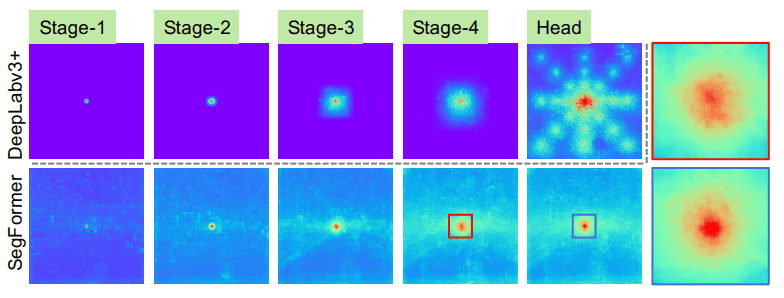
「SegFormer 的編碼器自然地產(chǎn)生局部注意力,類似于較低階段的卷積,同時(shí)能夠輸出高度非局部注意力,有效地捕捉第 4 階段的上下文。如放大補(bǔ)丁所示,MLP 頭部(藍(lán)色框)的 ERF 與 Stage-4(紅色框)不同,除了非局部注意力之外,局部注意力明顯更強(qiáng)。」
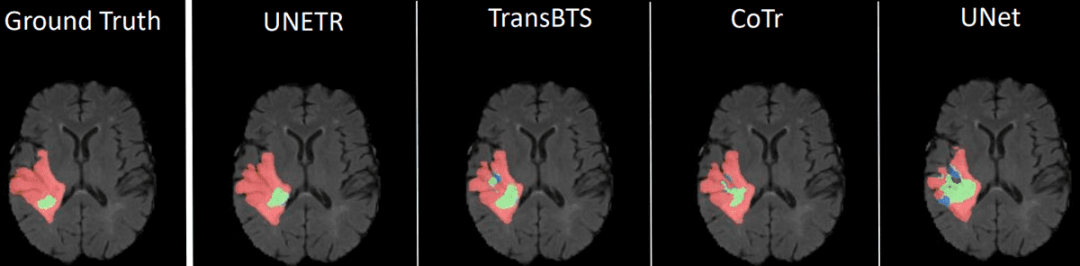
醫(yī)學(xué)成像中的視覺 Transformer:Unet + ViT = UNETR
盡管在醫(yī)學(xué)成像方面還有其他嘗試,但 UNETR 提供了最有說服力的結(jié)果。在這種方法中,ViT 適用于 3D 醫(yī)學(xué)圖像分割。研究表明,簡(jiǎn)單的適應(yīng)足以改善幾個(gè) 3D 分割任務(wù)的基線。
本質(zhì)上,UNETR 使用 Transformer 作為編碼器來學(xué)習(xí)輸入音頻的序列表示。與 Unet 模型類似,它旨在有效捕獲全局多尺度信息,這些信息可以通過長(zhǎng)殘差連接傳遞給解碼器,以不同的分辨率形成殘差連接以計(jì)算最終的語義分割輸出。
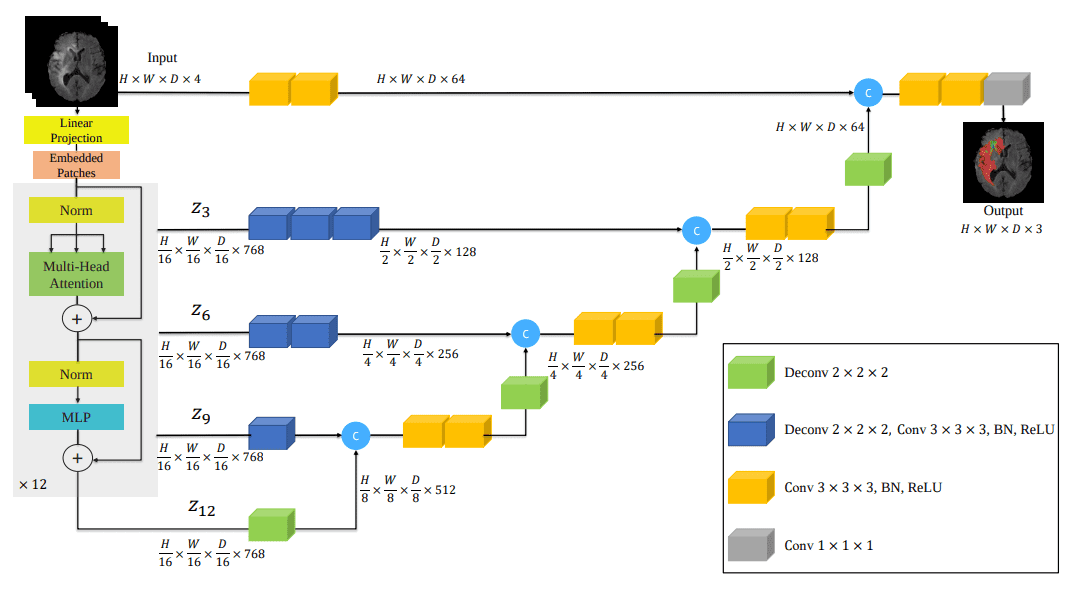
UNETR 架構(gòu)。
以下是論文的一些分割結(jié)果: