













神經輻射場基于點,訓練速度提升30倍,渲染質量超過NeRF
2020 年是立體神經渲染(Volumetric neural rendering)爆發的一年,比如 NeRF 可以生成高質量的視圖合成結果,但這種方法需要對每個場景進行優化,導致重建時間過長。另一方面,深度多視圖立體(multi-view stereo)方法可以通過網絡推理快速重建場景幾何。
來自南加州大學、Adobe Research 的研究者們提出了 Point-NeRF,該方法使用神經 3D 點云及其相關神經特征,將立體神經渲染以及深度多視圖立體方法兩者的優點進行結合,來建模輻射場。
在本文中,從 1000 個點發展出完整的點云:

通過逐步優化最初的 COLMAP 點的渲染結果:

在基于光線行進的渲染 pipeline 中,通過聚合場景表面附近的神經點特征,Point-NeRF 可以被有效渲染。此外,Point-NeRF 可通過對預訓練深度網絡的直接推理進行初始化,產生神經點云;該點云可以被微調,比 NeRF 訓練時間快 30 倍,且重建視覺質量超過 NeRF。Point-NeRF 可以與其他 3D 重建方法相結合,并通過一種新的剪枝和增長機制處理這些方法中的錯誤和異常值。在 DTU、NeRF Synthetics、ScanNet 和 Tanks and Temples 數據集上的實驗表明,Point-NeRF 可以超越現有方法,取得 SOTA 結果。

- 論文地址:https://arxiv.org/pdf/2201.08845.pdf
- 論文主頁:https://xharlie.github.io/projects/project_sites/pointnerf/
Point-NeRF
Point-NeRF 是基于點的神經輻射場,這是一種高質量神經場景重建和渲染的新方法,圖 2 (b)為架構圖:
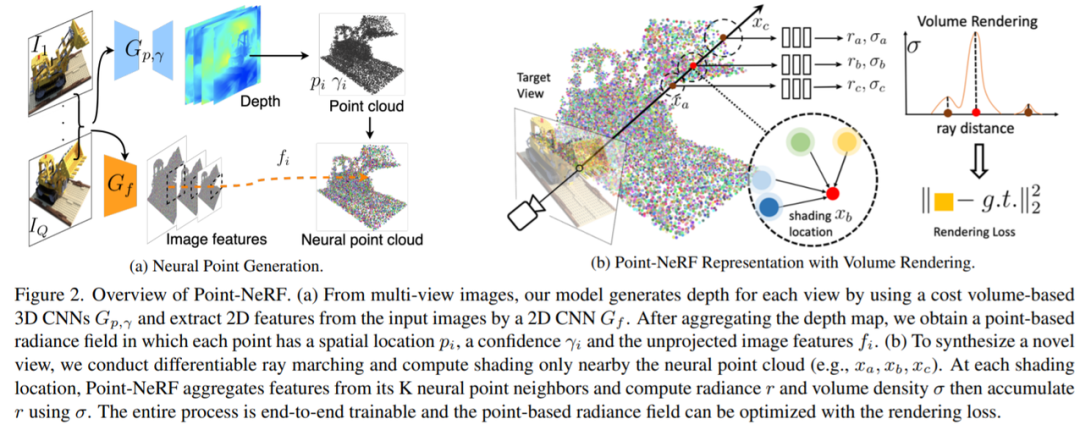
體渲染和輻射場:基于物理的體渲染可以通過可微射線推進(differentiable ray marching)進行數值計算。具體而言,一個像素的輻射可以通過一束光線穿過該像素來計算,在 {x_j | j = 1, ..., M} 中沿射線采樣 M 個著色點,并使用體積密度累積輻射,如:
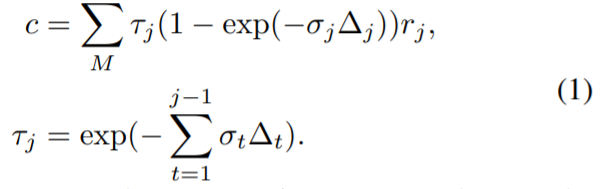
這里τ表示體積透光率,σ_j 和 r_j 是 x_j 處每個著色點 j 的體積密度和輻射度,Δ_t 是相鄰著色樣本之間的距離。NeRF 建議使用多層感知器(MLP)來回歸這樣的輻射場。本研究提出的 Point-NeRF 利用神經點云來計算體積屬性,從而實現更快和更高質量的渲染。
基于點的輻射場:該研究用 P = {(p_i, f_i,γ_i)|i = 1,…N}表示神經點云,P_I 處的每個點為 i,與編碼局部場景內容的神經特征向量 f_i 相關聯。該研究還為每個點分配了一個置信值γ_i∈[0,1],表示該點位于實際場景表面附近的可能性。該研究從這個點云反演輻射場。
給定任意 3D 位置 x,在半徑為 R 的范圍內查詢 K 個相鄰神經點。基于點的輻射場可以抽象為一個神經模塊,它從鄰近的神經點對任何陰影位置 x 上的視覺依賴亮度 r(沿任何視覺方向 d)和體積密度σ進行回歸,如下所示:
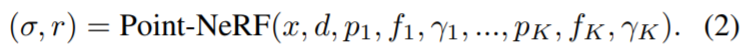
該研究使用具有多個子 MLP 的類似 PointNet 的神經網絡來進行回歸。總體而言,該研究首先對每個神經點進行神經處理,然后聚合多點信息以獲得最終估計。
Point-NeRF 重建
Point-NeRF 重建 pipeline 可用于有效地重建基于點的輻射場。首先利用跨場景訓練的深度神經網絡,通過直接網絡推理生成基于點的初始場。這個初始場通過點增長和剪枝技術進一步優化每個場景,從而實現最終的高質量輻射場重建。圖 3 顯示了這個工作流程,其中包含用于初始預測和場景優化的相應梯度更新。
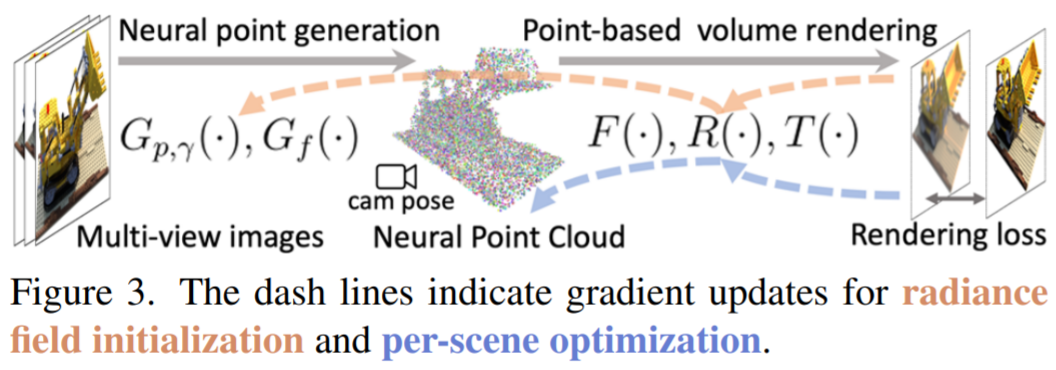
給定一組已知圖像 I_1、...、I_Q 和點云,Point-NeRF 表示可以通過優化隨機初始化的每一個點的神經特征和具有渲染損失的 MLP(類似于 NeRF)來重建。然而,這種純粹的逐場景優化依賴于現有的點云,并且可能非常緩慢。
因此,該研究提出了一個神經生成模塊,通過前饋神經網絡預測所有神經點屬性,包括點位置 p_i 、神經特征 f_i 和點置信度 γ_i ,以實現高效重建。在很短的時間內,渲染質量更好或與 NeRF 相當,而后者需要更長的時間來優化(參見表 1 和表 2)。
端到端重建:該研究結合多視圖點云,得到最終的神經點云。該研究用渲染損失從頭到尾訓練點生成網絡和表示網絡(見圖 3),這允許生成模塊產生合理的初始輻射場。該研究還使用合理的權重在 Point-NeRF 表示中初始化 MLP,從而顯著節省了每個場景的擬合時間。
此外,除了使用完整的生成模塊外,該研究的 pipeline 還支持使用從其他方法(如 COLMAP [44])進行點云重建,其中模型(不包括 MVS 網絡)仍然可以為每個點提供有意義的初始神經特征。
實驗
該研究首先在 DTU 測試集上對模型進行評估,比較內容包括 PixelNeRF 、IBRNet 、MVSNeRF 和 NeRF ,并用 10k 迭代微調所有方法以進行比較。此外,該研究僅用 1k 迭代以展示 Point-NeRF 優化效率。具體結果如下:
表 1 為不同方法定量比較,比較內容包括 PSNR, SSIM, LPIPS,圖 6 為渲染結果。由結果可得,在 10k 次迭代之后,SSIM 和 LPIPS 達到最佳,分別為 0.957 和 0.117,優于 MVSNeRF 和 NeRF 結果。IBRNet 生成的 PSNR 結果稍好一些為 31.35,但 Point-NeRF 可以恢復更精確的紋理細節和高光,如圖 6 所示。
另一方面,IBRNet 的微調成本也更高,相同的迭代次數,比 Point-NeRF 微調多花 1 小時,也就是 5 倍的時間。這是因為 IBRNet 依賴大型的全局 CNN,而 Point-NeRF 利用局部點特征以及 MLP 更容易優化。更重要的是,基于點的表示位于實際場景表面附近,從而避免了在空場景中采樣射線點(ray points),從而實現高效的逐場景優化。


雖然 IBRNet 中更復雜的特征提取器可以提高質量,但它會增加內存使用,影響訓練效率。更重要的是,Point-NeRF 生成網絡已經提供了高質量的初始輻射場,以支持高效優化。該研究發現,即使經過 2 min / 1K 的微調迭代,Point-NeRF 也能獲得非常高的視覺質量,可與 MVSNeRF 最終的 10k 次迭代結果相媲美,這也證明了 Point-NeRF 方法重建效率的高效性。
雖然 Point-NeRF 是在 DTU 數據集上訓練而來,但其可以很好地泛化到新的數據集。該研究展示了在 NeRF synthetic 數據集中,Point-NeRF 與其他 SOTA 方法比較結果,定性結果如圖 7 ,定量結果如表 2。
實驗結果表明,Point-NeRF_20K 明顯優于 IBRNet 結果,具有更好的 PSNR、SSIM 和 LIPIPS;該研究還通過更好的幾何和紋理細節實現了高質量渲染,如圖 7 所示。
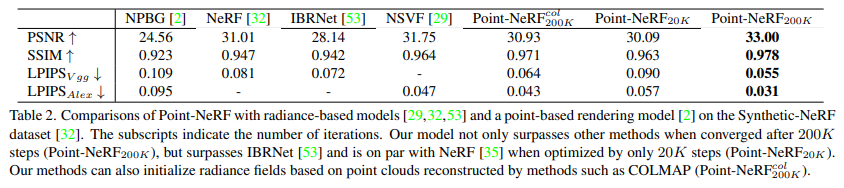

與不同場景的比較:Point-NeRF 在 20K 迭代后,非常接近 NeRF 在 200K 迭代訓練后的結果。從視覺上來講,Point-NeRF 在 20K 迭代后在某些情況下已經有了更好的渲染效果,例如圖 7 中的 Ficus 場景(第四行)。Point-NeRF_20K 只用了 40 分鐘進行優化,而 NeRF 需要 20 + 小時,兩者相比,Point-NeRF 快了近 30 倍,但 NSVF 的優化效果只比 Point-NeRF 的 40 分鐘效果略好。如圖 7 所示,Point-NeRF 200K 結果包含最多的幾何和紋理細節,而且,該方法是唯一可以完全恢復的方法。




























