美團二面:如何解決 Bin Log 與 Redo Log 的一致性問題
剛看見這個題目的時候還是有點懵逼的,后來才反應過來其實問的就是 redo log 的兩階段提交
老規矩,背誦版在文末。點擊閱讀原文可以直達我收錄整理的各大廠面試真題
為什么說 redo log 具有崩潰恢復的能力
前面我們說過,MySQL Server 層擁有的 bin log 只能用于歸檔,不足以實現崩潰恢復(crash-safe),需要借助 InnoDB 引擎的 redo log 才能擁有崩潰恢復的能力。所謂崩潰恢復就是:即使在數據庫宕機的情況下,也不會出現操作一半的情況
至于為什么說 redo log 具有崩潰恢復的能力,而 bin log 沒有,我們先來簡單看一下這兩種日志有哪些不同點:
1)適用對象不同:
bin log 是 MySQL 的 Server 層實現的,所有引擎都可以使用
而 redo log 是 InnoDB 引擎特有的
2)寫入內容不同:
bin log 是邏輯日志,記錄的是這個語句的原始邏輯,比如 “給 id = 1 這一行的 age 字段加 1”
redo log 是物理日志,記錄的是 “在某個數據頁上做了什么修改”
3)寫入方式不同:
bin log 是可以追加寫入的。“追加寫” 是指 bin log 文件寫到一定大小后會切換到下一個,并不會覆蓋以前的日志
redo log 是循環寫的,空間固定會被用完
可以看到,redo log 和 bin log 的一個很大的區別就是,一個是循環寫,一個是追加寫。也就是說 redo log 只會記錄未刷入磁盤的日志,已經刷入磁盤的數據都會從 redo log 這個有限大小的日志文件里刪除。
而 bin log 是追加日志,保存的是全量的日志。這就會導致一個問題,那就是沒有標志能讓 InnoDB 從 bin log 中判斷哪些數據已經刷入磁盤了,哪些數據還沒有。
舉個例子,bin log 記錄了兩條日志:
- 記錄 1:給 id = 1 這一行的 age 字段加 1
- 記錄 2:給 id = 1 這一行的 age 字段加 1
假設在記錄 1 刷盤后,記錄 2 未刷盤時,數據庫崩潰。重啟后,只通過 bin log 數據庫是無法判斷這兩條記錄哪條已經寫入磁盤,哪條沒有寫入磁盤,不管是兩條都恢復至內存,還是都不恢復,對 id = 1 這行數據來說,都是不對的。
但 redo log 不一樣,只要刷入磁盤的數據,都會從 redo log 中被抹掉,數據庫重啟后,直接把 redo log 中的數據都恢復至內存就可以了。
這就是為什么說 redo log 具有崩潰恢復的能力,而 bin log 不具備。
redo log 兩階段提交
前面我們介紹過一條 SQL 查詢語句的執行過程,簡單回顧:
MySQL 客戶端與服務器間建立連接,客戶端發送一條查詢給服務器;
服務器先檢查查詢緩存,如果命中了緩存,則立刻返回存儲在緩存中的結果;否則進入下一階段;
服務器端進行 SQL 解析、預處理,生成合法的解析樹;
再由優化器生成對應的執行計劃;
執行器根據優化器生成的執行計劃,調用相應的存儲引擎的 API 來執行,并將執行結果返回給客戶端
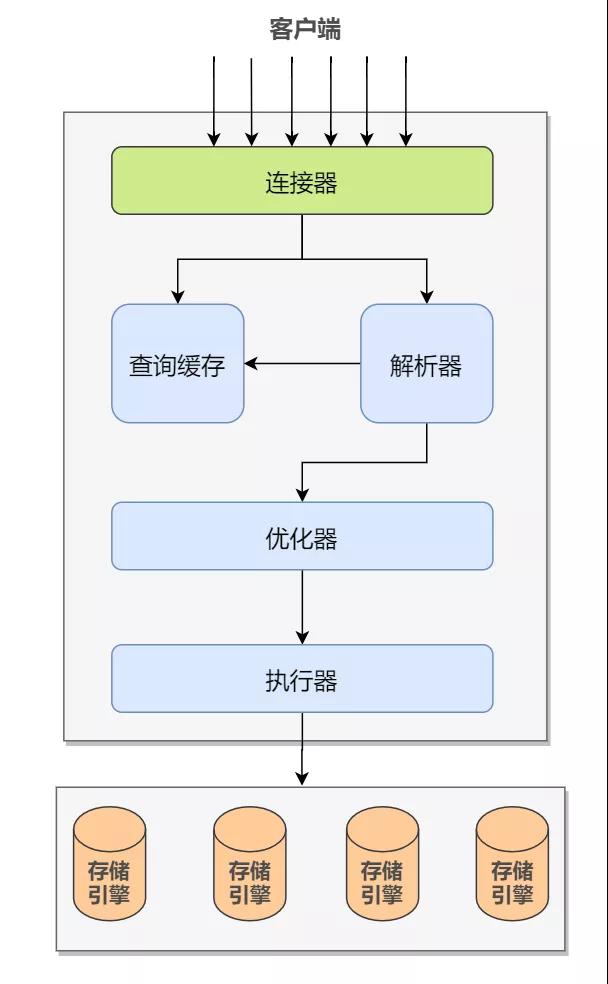
對于更新語句來說,這套流程同樣也是要走一遍的,不同的是,更新流程還涉及兩個重要的日志模塊 bin log 和 redo log。
以下面這條簡單的 SQL 語句為例,我們來解釋下執行器和 InnoDB 存儲引擎在更新時做了哪些事情:
- update table set age = age + 1 where id = 1;
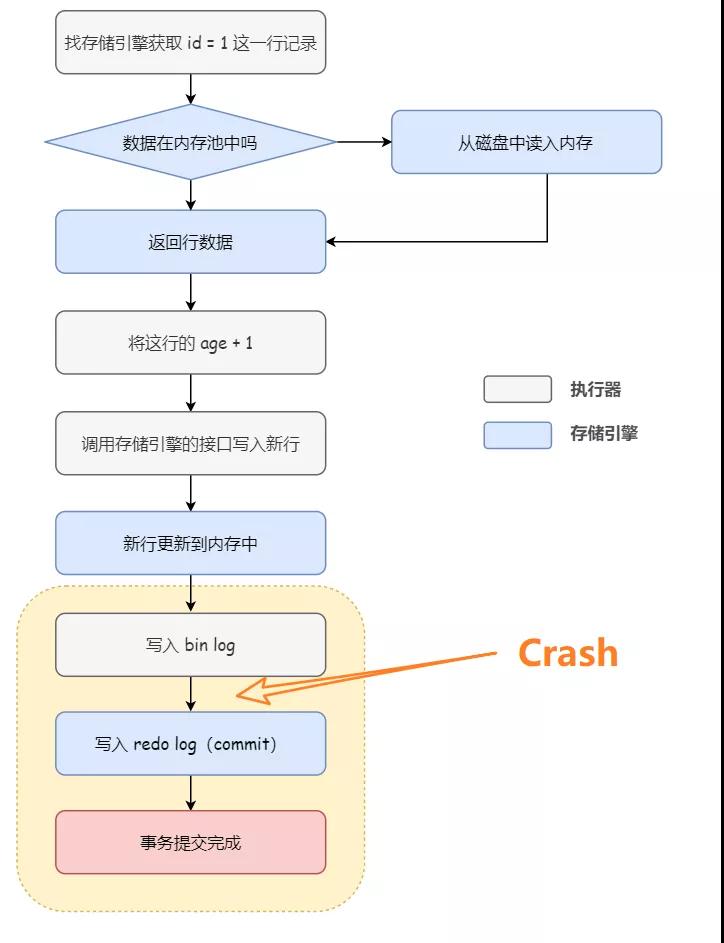
執行器:找存儲引擎取到 id = 1 這一行記錄
存儲引擎:根據主鍵索引樹找到這一行,如果 id = 1 這一行所在的數據頁本來就在內存池(Buffer Pool)中,就直接返回給執行器;否則,需要先從磁盤讀入內存池,然后再返回
執行器:拿到存儲引擎返回的行記錄,把 age 字段加上 1,得到一行新的記錄,然后再調用存儲引擎的接口寫入這行新記錄
存儲引擎:將這行新數據更新到內存中,同時將這個更新操作記錄到 redo log 里面,此時 redo log 處于 prepare 狀態。然后告知執行器執行完成了,隨時可以提交事務
注意不要把這里的提交事務和我們 sql 語句中的提交事務 commit 命令搞混了哈,我們這里說的提交事務,指的是事務提交過程中的一個小步驟,也是最后一步。當這個步驟執行完成后,commit 命令就執行成功了。
執行器:生成這個操作的 bin log,并把 bin log 寫入磁盤
執行器:調用存儲引擎的提交事務接口
存儲引擎:把剛剛寫入的 redo log 狀態改成提交(commit)狀態,更新完成
如下圖所示:
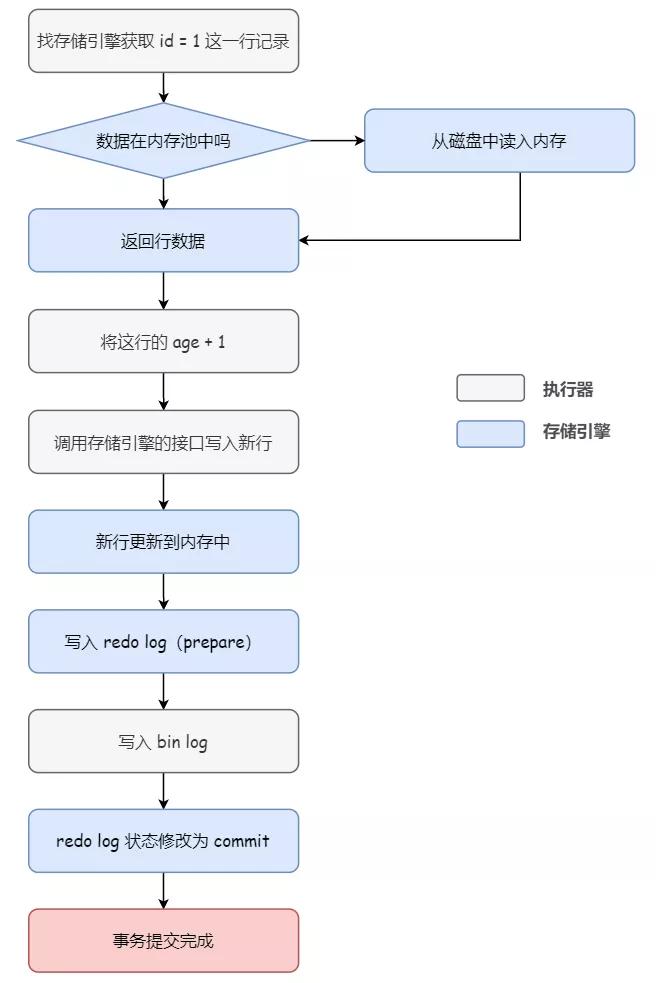
可以看到,所謂兩階段提交,其實就是把 redo log 的寫入拆分成了兩個步驟:prepare 和 commit。
所以,為什么要這樣設計呢?這樣設計怎么就能夠實現崩潰恢復呢?
根據兩階段提交,崩潰恢復時的判斷規則是這樣的:
如果 redo log 里面的事務是完整的,也就是已經有了 commit 標識,則直接提交
如果 redo log 里面的事務處于 prepare 狀態,則判斷對應的事務 binlog 是否存在并完整
- a. 如果 binlog 存在并完整,則提交事務;
- b. 否則,回滾事務。
當然,這樣說小伙伴們肯定沒法理解,下面來看幾個實際的例子:
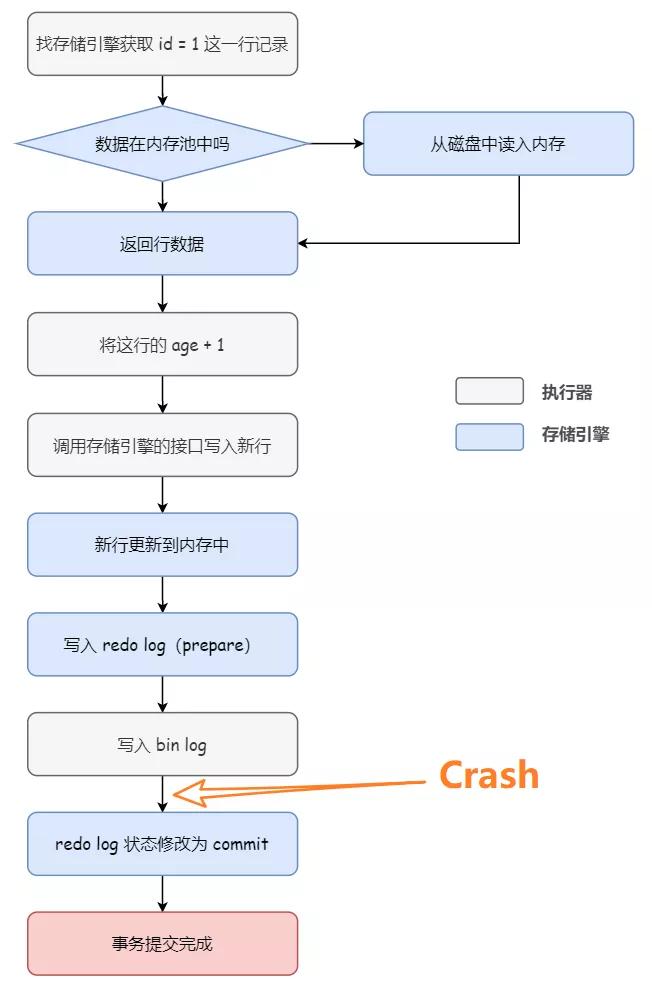
如下圖所示,假設數據庫在寫入 redo log(prepare) 階段之后、寫入 binlog 之前,發生了崩潰,此時 redo log 里面的事務處于 prepare 狀態,binlog 還沒寫(對應 2b),所以崩潰的時候,這個事務會回滾。
Why?
因為 binlog 還沒有寫入,之后從庫進行同步的時候,無法執行這個操作,但是實際上主庫已經完成了這個操作,所以為了主備一致,在主庫上需要回滾這個事務
并且,由于 binlog 還沒寫,所以也就不會傳到備庫,從而避免主備不一致的情況。
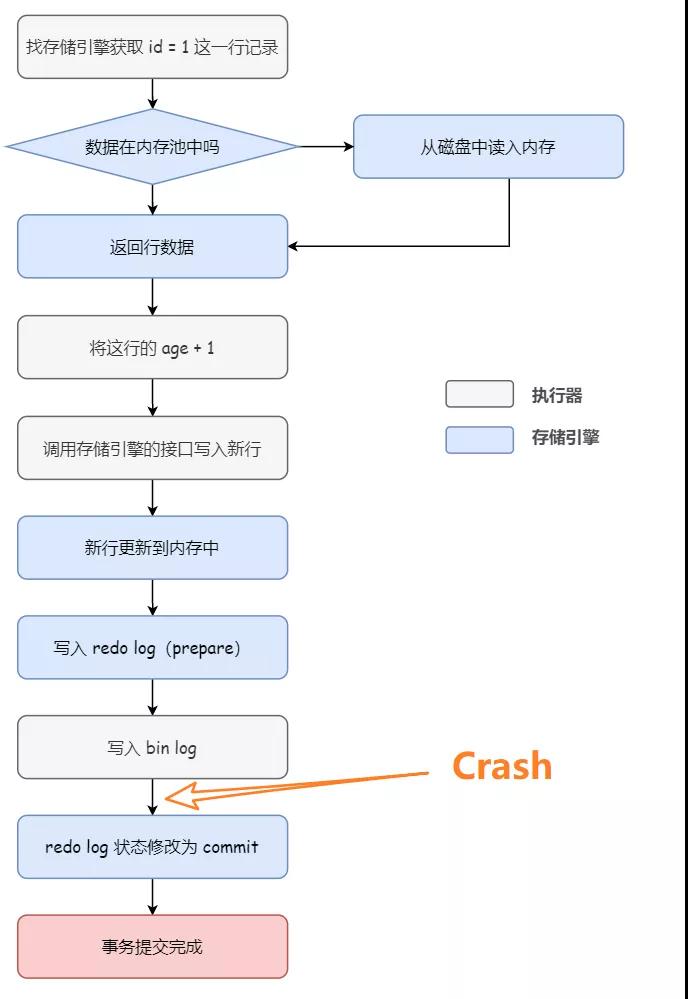
而如果數據庫在寫入 binlog 之后,redo log 狀態修改為 commit 前發生崩潰,此時 redo log 里面的事務仍然是 prepare 狀態,binlog 存在并完整(對應 2a),所以即使在這個時刻數據庫崩潰了,事務仍然會被正常提交。
Why?
因為 binlog 已經寫入成功了,這樣之后就會被從庫同步過去,但是實際上主庫并沒有完成這個操作,所以為了主備一致,在主庫上需要提交這個事務。
所以,其實可以看出來,處于 prepare 階段的 redo log 加上完整的 bin log,就能保證數據庫的崩潰恢復了。
可能有同學就會問了,MySQL 咋知道 bin log 是不是完整的?
簡單來說,一個事務的 binlog 是有完整格式的(這個我們在后面的文章中會詳細解釋):
- statement 格式的 bin log,最后會有 COMMIT
- row 格式的 bin log,最后會有 XID event
而對于 bin log 可能會在中間出錯的情況,MySQL 5.6.2 版本以后引入了 binlog-checksum 參數,用來驗證 bin log 內容的正確性。
思考一個問題,兩階段提交是必要的嗎?可不可以先 redo log 寫完,再寫 bin log 或者反過來?
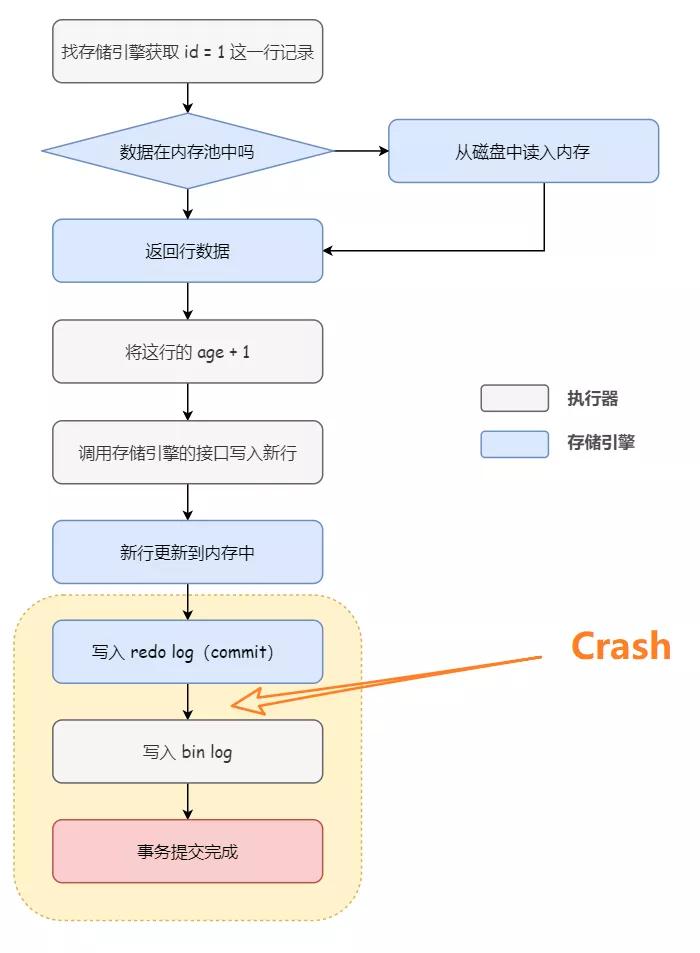
1)對于先寫完 redo log 后寫 bin log 的情況:
假設在 redo log 寫完,bin log 還沒有寫完的時候,MySQL 崩潰。主庫中的數據確實已經被修改了,但是這時候 bin log 里面并沒有記錄這個語句。因此,從庫同步的時候,就會丟失這個更新,和主庫不一致。
2)對于先寫完 binlog 后寫 redo log 的情況:
如果在 bin log 寫完,redo log 還沒寫的時候,MySQL 崩潰。因為 binlog 已經寫入成功了,這樣之后就會被從庫同步過去,但是實際上 redo log 還沒寫,主庫并沒有完成這個操作,所以從庫相比主庫就會多執行一個事務,導致主備不一致
最后放上這道題的背誦版:
面試官:
- 問法 1:如何解決 bin log 與 redo log 的一致性問題?
- 問法 2:一條 SQL 更新語句是如何執行的?
- 問法 3:講一下 redo log / redo log 兩階段提交原理
小牛肉:
所謂兩階段提交,其實就是把 redo log 的寫入拆分成了兩個步驟:prepare 和 commit。
首先,存儲引擎將執行更新好的新數據存到內存中,同時將這個更新操作記錄到 redo log 里面,此時 redo log 處于 prepare 狀態。然后告知執行器執行完成了,隨時可以提交事務
然后執行器生成這個操作的 bin log,并把 bin log 寫入磁盤
最后執行器調用存儲引擎的提交事務接口,存儲引擎把剛剛寫入的 redo log 狀態改成提交(commit)狀態,更新完成
如果數據庫在寫入 redo log(prepare) 階段之后、寫入 binlog 之前,發生了崩潰:
此時 redo log 里面的事務處于 prepare 狀態,binlog 還沒寫,之后從庫進行同步的時候,無法執行這個操作,但是實際上主庫已經完成了這個操作,所以為了主備一致,MySQL 崩潰時會在主庫上回滾這個事務
而如果數據庫在寫入 binlog 之后,redo log 狀態修改為 commit 前發生崩潰,此時 redo log 里面的事務仍然是 prepare 狀態,binlog 存在并完整,這樣之后就會被從庫同步過去,但是實際上主庫并沒有完成這個操作,所以為了主備一致,即使在這個時刻數據庫崩潰了,主庫上事務仍然會被正常提交。