作業幫kubernetes serverless在大規模任務場景下落地和優化
一、背景
在作業幫的云原生容器化改造進程中,各個業務線原本部署在虛擬機上的定時任務逐漸遷移到kubernetes集群cronjob上。開始cronjob規模較小,數量在1000以下時,運行正常,但是隨著cronjob規模的擴大到上萬個后,問題就逐漸顯現出來。
二、問題
當時主要面臨著兩個問題:一是集群內節點穩定性問題,二是集群的資源利用率不高。
第一個問題:集群內節點穩定性
由于業務上存在很多分鐘級執行的定時任務,導致pod的創建和銷毀非常頻繁,單個節點上平均每分鐘有上百個容器創建和銷毀,機器的穩定性問題頻繁出現。
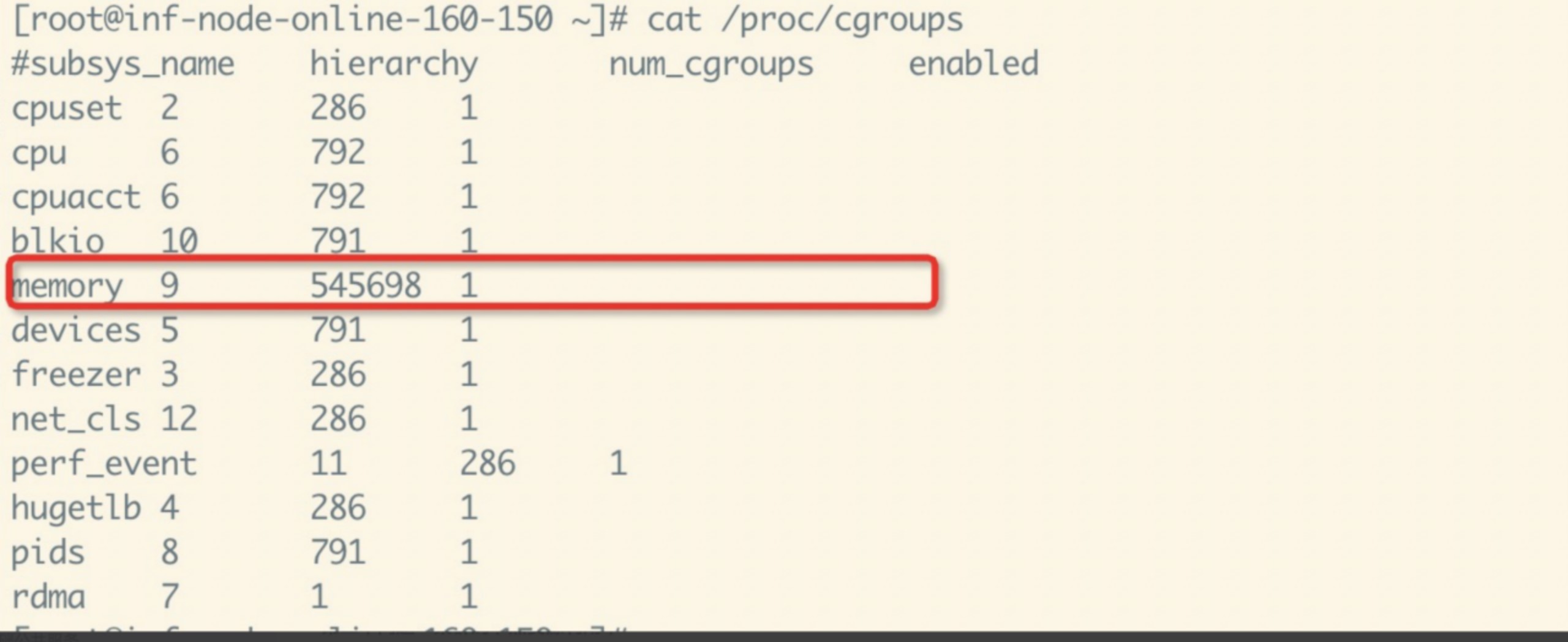
一個典型的問題是頻繁的創建pod導致節點上cgroup過多,特別是memory cgroup不能及時回收,讀取/sys/fs/cgroup/memory/memory.stat變慢,由于kubelet會定期讀取該文件來統計各個cgroup namespace的內存消耗,cpu內核態會逐漸上升,上升到一定程度時,部分cpu核心會長時間陷入內核態,導致明顯的網絡收發包延遲。
在節點上 perf record cat /sys/fs/cgroup/memory/memory.stat 和 perf report 會發現,cpu主要消耗在memcg_stat_show上:
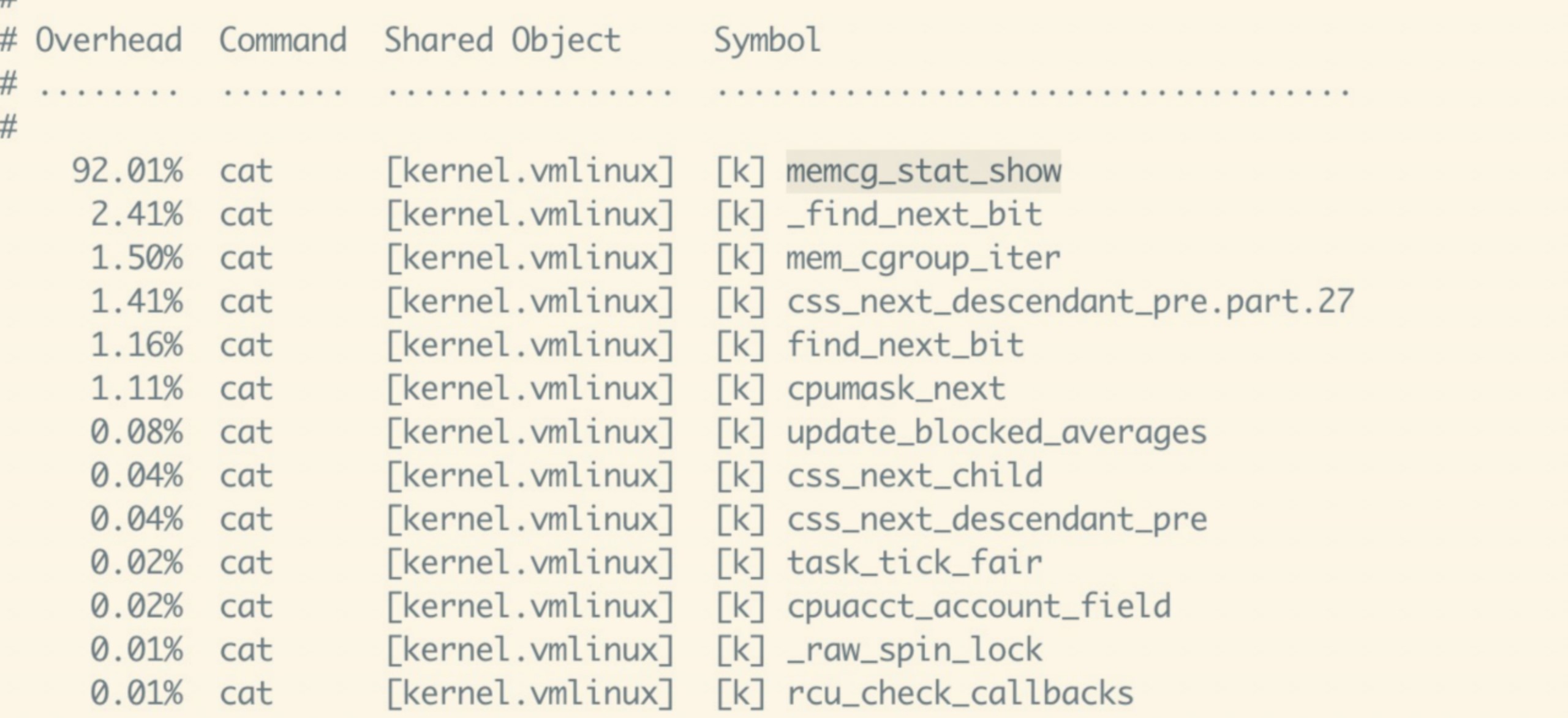
而cgroup-v1的memcg_stat_show函數會對每個cpu核心遍歷多次memcg tree,而在一個memcg tress的節點數量達到幾十萬級別時,其帶來的耗時是災難性的。
為什么memory cgroup沒有隨著容器的銷毀而立即釋放呢?主要是因為memory cgroup釋放時會遍歷所有緩存頁,這可能很慢,內核會在這些內存需要用到時才回收,當所有內存頁被清理后,相應的memory cgroup才會釋放。整體來看,這個策略是通過延遲回收來分攤直接整體回收的耗時,一般情況下,一臺機器上創建容器不會太多,通常幾百到幾千基本都沒什么問題,但是在大規模定時任務場景下,一臺機器每分鐘都有上百個容器被創建和銷毀,而節點并不存在內存壓力,memory cgroup沒有被回收,一段時間后機器上的memory cgroup數量達到了幾十萬,讀取一次memory.stat,耗時達到了十幾秒,cpu內核態大幅上升,導致了明顯的網絡延遲。
除此之外,還有dockerd負載過高,響應變慢、kubelet PLEG超時導致節點unready等問題。
第二個問題:集群的節點資源利用率
由于我們使用的智能卡的CNI網絡模式,單個節點上是有的pod數量上限的,節點有幾乎一半的pod數量是為定時任務的pod保留的,而定時任務的pod運行的時間普遍很短,資源使用率很低,這就導致了集群為定時任務預留的資源產生了較多的閑置,不利于整體的機器資源使用率提升。
其他問題:調度速度、服務間隔離性
在某些時段,比如每天的0點,會同時產生幾千個JOB需要運行。而原生調度器是k8s調度pod本身是對集群資源的分配,反應在調度流程上則是預選和打分階段是順序進行的,也就是串行。幾千個JOB調度完成需要幾分鐘,而大部分業務是要求00:00:00準時運行或者業務接受誤差在3s內。
有些服務POD是計算或者IO密集型,這種服務會大量搶占節點CPU或者IO,而cgroup的隔離并不徹底,所以會干擾其他正常在線服務運行。
三、在k8s集群中使用serverless
所以對CRONJOB型任務我們需要一個更徹底的隔離方式,更細粒度的節點,更快的的調度模式。
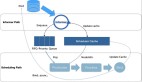
為了解決上述問題我們考慮將定時任務POD和普通在線服務的POD隔離開,但是由于很多定時任務需要和集群內服務互通,最終確定了一種將定時任務的pod在集群內隔離開來的解決辦法 —— k8s serverless。我們引入了虛擬節點,來實現在現有的k8s體系下使用k8s serverless。部署在虛擬節點上的 POD 具備與部署在集群既有節點上的 POD 一致的安全隔離性、網絡連通性,又具有無需預留資源,按量計費的特性。如圖所示:
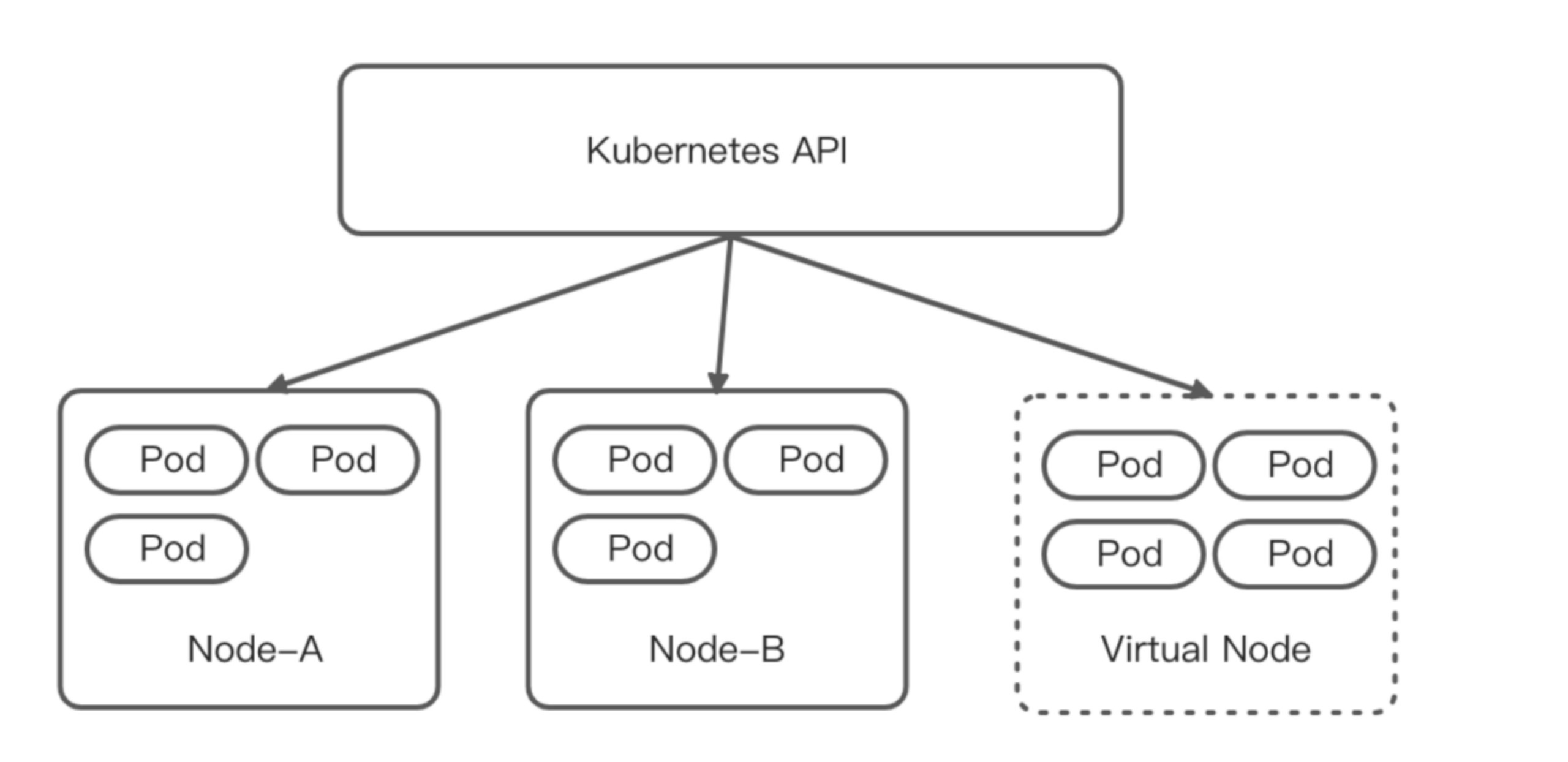
任務調度器
所有cronjob型workload都使用任務調度器,任務調度器批量并行調度任務POD到serverless的節點,調度上非串行,實現完整并行,調度速度ms級。也支持serverless節點故障時或者資源不足時調度回正常節點。
解決和正常節點上POD差異
在使用k8s serverless前首先要解決serverless pod和運行在正常節點上的POD的差異,做到對業務研發無感。
1.日志采集統一
在日志采集方面,由于虛擬節點是云廠商維護的,無法運行DaemonSet,而我們的日志采集組件是以DaemonSet的形式運行的,這就需要對虛擬節點上的日志做單獨的采集方案。云廠商將容器的標準輸出收集到各自的日志服務里,各個云廠商日志服務的接口各不一樣,所以我們自研了日志消費服務,通過插件的形式集成云廠商日志client,消費各個云廠商的日志,和集群統一的日志組件采集的日志打平后放到統一kafka集群里以供后續消費。
2.監控報警統一
在監控方面,我們對serverless上的pod 做了實時的cpu/內存/磁盤/網絡流量等監控,做到了和普通節點上的pod一致,暴露pod sanbox 的export接口。我們的promethus負責統一采集。遷移到serverless時做到了業務完全無感。
提升啟動性能
Serverless JOB 需要具備秒級的啟動速度才能滿足定時任務對啟動速度的要求,比如業務要求00:00:00準時運行或者業務接受誤差在3s內。
主要耗時在以下兩個步驟:
1. 底層sanbox的創建或者運行環境初始化
2. 業務鏡像拉取
主要是做到同一個workload的sanbox能夠被復用,這樣主要耗時就在服務啟動時長,除了首次耗時較長,后續基本在秒級啟動
四、總結
通過自定義job調度器、解決和正常節點上POD的差異、提升serverless POD啟動性能措施,做到了業務無感的切換到serverless,有效的利用serverless免運維、強隔離、按量計費的特性,既實現了和普通業務pod隔離,使得集群不用再為定時任務預留機器資源,釋放了集群內自有節點的上萬個pod,約占總量的10%;同時避免了節點上pod創建過于頻繁引發的問題,業務對定時任務的穩定性也有了更好的體驗。定時任務遷移到serverless,釋放了整個集群約10%的機器,定時任務的資源成本降低了70%左右。