Pod 調(diào)度概覽及 Kubernetes 調(diào)度器介紹
Kubernetes 有 5 大核心組件:kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy。這 5 大核心組件缺一不可,每個組件負責不同的功能。其中,kube-scheduler 主要用來負責 Pod 的調(diào)度。那么 Kubernetes 中 Pod 有哪些調(diào)度方法?Kubernetes 調(diào)度器又是什么,負責什么樣的功能呢?
本章將會詳細介紹 Pod 的調(diào)度方法及 Kubernetes 調(diào)度器的核心內(nèi)容。

一、Kubernetes 中的 Pod 調(diào)度方法
Kubernetes 調(diào)度器用來調(diào)度 Kubernetes 集群中的 Pod。其實,在 Kubernetes 中 Pod 的調(diào)度方式有很多,其中調(diào)度器是最主要的 Pod 調(diào)度方式。本節(jié)課,我來詳細給你介紹 Kubernetes 中 Pod 的調(diào)度方法。
1. 什么是 Pod 調(diào)度?

在 Kubernetes 中,Pod 調(diào)度,指的是通過一系列的調(diào)度算法、調(diào)度邏輯,最終決定將 Pod 調(diào)度到哪個節(jié)點運行。
假設(shè)你創(chuàng)建一個 Deployment 資源,副本數(shù)是 100,那么這時候,Kubernetes 集群中就會新增 100 個 待調(diào)度的 Pod,Pod 狀態(tài)為 Pending。這時候,kube-scheduler 調(diào)度器會根據(jù) Pod 的 Spec 定義、集群中當前節(jié)點列表及節(jié)點資源信息,根據(jù)配置的調(diào)度插件(每個插件實現(xiàn)一類調(diào)度策略/算法),從這些 Node 列表中,選擇出最適合調(diào)度 Pod 的節(jié)點,并將 Pod 調(diào)度到該節(jié)點上(設(shè)置 Pod 的 spec.nodeName字段值為節(jié)點的名字即可)。之后,該節(jié)點的 kubelet 就會根據(jù) Pod 的 Spec 定義在幾點上啟動 Pod。
2. 為什么要實現(xiàn) Pod 調(diào)度?
一個 Kubernetes 集群中,包括很多個 Node 節(jié)點,v1.24 及以上的版本,支持多達 5000 個 Node。這些 Node 存在著或多或少的差異,例如:
- 機型不同、配置不同:例如有些節(jié)點可能是 16C256G,有的節(jié)點可能是 32C512G;
- 機器部署的環(huán)境不同:不同的節(jié)點環(huán)境會影響 Pod 的運行。例如:位于不同的機架、機房、是否支持 IPV6 等,會直接影響 Pod 的網(wǎng)絡(luò)環(huán)境;
- 機器上的可用資源量不同:有的節(jié)點當前 CPU 或內(nèi)存資源已經(jīng)分配完成,有的節(jié)點空閑資源還很多;
- 節(jié)點的可用性不同:有的節(jié)點處在健康的狀態(tài),有的節(jié)點可能因為各種原因處在宕機、網(wǎng)絡(luò)不可達、高負載的等狀態(tài);
- 節(jié)點的設(shè)備資源不同:有的節(jié)點只有 CPU,而有的節(jié)點可能會有 GPU 卡。
上面這些異同,會直接影響到 Pod 在這些節(jié)點上能否成功運行,以及能否穩(wěn)定的運行。
此外,企業(yè)為了降本增效,期望整個集群的資源利用率處在一個較高的水位,但同時整個集群的 Pod 、節(jié)點等資源又能夠穩(wěn)定運行,處在一個健康的水位:
- Pod 穩(wěn)定運行:Pod 能夠穩(wěn)定運行和調(diào)度;
- 高資源利用率:在保證 Pod 穩(wěn)定運行的前提下,盡可能提高整個集群的資源利用率。集群的資源利用率越高,企業(yè)的成本越低,因為可以將空閑的節(jié)點退掉,或者減少機器的采購數(shù)量。
Pod 穩(wěn)定運行和高資源利用率,在資源利用率達到一定閾值之后,二者往往呈現(xiàn)出一種互斥的關(guān)系:

因為節(jié)點/集群資源利用率越高,意味著節(jié)點/集群的負載越高,節(jié)點負載過高,會影響 Pod 的穩(wěn)定運行,因為 Pod 中的進程可能因為高負載導(dǎo)致無法調(diào)度或延時調(diào)度,這就會導(dǎo)致一些請求超時失敗,驗證的甚至?xí)?dǎo)致機器宕機。
在提高集群資源利用率的過程中, 提高 Pod 一個有效的解決辦法時,將負載均衡到所有節(jié)點,避免單節(jié)點負載過高。。這就需要,Pod 在調(diào)度的時候,能夠根據(jù) Pod 數(shù)量、Pod 過往的 CPU 和內(nèi)存利用率、節(jié)點的負載和數(shù)量等數(shù)據(jù),將 Pod 調(diào)度到空閑的節(jié)點上,以分擔其他節(jié)點的壓力。
另外,在降本場景下,我們還希望能夠在節(jié)點負載達到某個閾值之前(根據(jù)過往經(jīng)驗,在節(jié)點負載在 40% ~ 45% 以下時,其上的 Pod 絕大部分情況下可以穩(wěn)定運行不受影響),盡可能將 Pod 調(diào)度到節(jié)點上,以空出其他節(jié)點,從而銷毀空閑節(jié)點,從而節(jié)省企業(yè)成本。這也需要 Pod 在調(diào)度的時候,能夠盡量將 Pod 調(diào)度到一個節(jié)點上。
另外,在一個節(jié)點上的 Pod 因為節(jié)點故障而異常、或者 Panic 退出之后,Kubernetes 也需要將 Pod 調(diào)度到其他健康的節(jié)點上,并啟動。這種自愈能力,也是 Kubernetes 如此受歡迎的一個重要原因。
另外,在很多時候,我們?yōu)榱藢崿F(xiàn)應(yīng)用的高可用,往往需要應(yīng)用多副本部署,并且為了盡可能提高容災(zāi)級別,需要盡可能將這些應(yīng)用實例打散在不同的節(jié)點、機架、機房、園區(qū)甚至地域進行部署。要實現(xiàn) Pod 的打散部署,也需要調(diào)度 Pod。
這些調(diào)度場景總結(jié)如下:

上面的場景是在將應(yīng)用部署到 Kubernetes 集群中,面臨的最常見、最核心的訴求,這些訴求的解決,依賴于 Pod 調(diào)度。
所以,在 Kubernetes 中,Pod 調(diào)度是非常核心、非常重要的一個能力,也是企業(yè)在使用 Kubernetes 中,最剛需、最頻繁需要二開的一個能力。
3. Kubernetes 調(diào)度 Pod 的方式有哪些?
Kubernetes 提供了大量的調(diào)度機制,用來調(diào)度一個 Pod。在 Kubernetes 開發(fā)、運維的工作中,我們有必要了解下所有這些 Pod 調(diào)度方法。
總的來說,Pod 調(diào)度方法如下圖所示:

上圖羅列了 Kubernets 中的各個調(diào)度方法。其中絕大部分調(diào)度方法是在 kube-scheduler 中,以調(diào)度插件的形式實現(xiàn)的,例如綠色部分的調(diào)度方法。
另外,Kubernetes 還支持調(diào)度器擴展,支持 以下 3 種調(diào)度器擴展方式:自定義調(diào)度器、Scheduler Extender、Scheduling Framework 這 3 種調(diào)度器擴展方式,后文會詳細介紹,這里不再介紹。
此外,Kubernetes 中的一些內(nèi)置資源也會創(chuàng)建 Pod。創(chuàng)建出來的 Pod 最終是由 Kubernetes 調(diào)度器完成調(diào)度的。但由這些內(nèi)資資源根據(jù)某種策略創(chuàng)建出來的 Pod,也可以理解我是 Pod 調(diào)度的一種。當前有以下內(nèi)置資源支持創(chuàng)建 Pod,不同資源創(chuàng)建 Pod 的方式不同:
- DaemonSet:會在 Kubernetes 集群中的所有節(jié)點上創(chuàng)建 Pod;
- Deployment/StatefulSet/ReplicaSet:會創(chuàng)建指定副本數(shù)的 Pod,并始終確保 Pod 副本數(shù)為期望的個數(shù);
- CronJob:會根據(jù) spec.schedule指定的 Cron 格式的字符串(例如:*/5 * * * * 說明每 5 分鐘執(zhí)行一次),來周期性的創(chuàng)建 Pod;
- Job:用于一次性常見指定數(shù)量的 Pod。Pod 完成后,Job 會記錄成功或失敗的狀態(tài)。
上面列舉了很多 Pod 調(diào)度方法,這些方法在本套課程中會一一詳細介紹。這里,列出來,供你總結(jié)性學(xué)習(xí)。
二、Kubernetes 調(diào)度器簡介
上面我們列舉了很多 Pod 的調(diào)度方法,其中一大半的方法是由 Kubernetes 調(diào)度器來完成的。Kubernetes 調(diào)度器指的是 kube-scheduler 組件。
kube-scheduler 是 Kubernetes 的默認調(diào)度器,負責根據(jù)一系列可配置的策略和算法將 Pods 分配到最合適運行的節(jié)點上。
三、Kubernetes 調(diào)度器的演進歷史
為了讓你更為完整的了解 Kubernetes 調(diào)度器。本小節(jié),我來給你介紹下 Kubernetes 調(diào)度器的演進歷史。Kubernetes 調(diào)度器的演進時間線如下圖所示:

通過上述 Kubernetes 調(diào)度器演進時間線,可以知道從 2020 年 Scheduling Framework 特性發(fā)布以來,調(diào)度器的架構(gòu)基本已經(jīng)趨于穩(wěn)定。調(diào)度器近年來也加強了 AI 場景和異構(gòu)資源的調(diào)度支持,并且越來越關(guān)注于調(diào)度器性能優(yōu)化、指標監(jiān)控、調(diào)度器測試等能力的構(gòu)建。
在整個調(diào)度器的演進歷史中,每個版本都會對調(diào)度器進行一些或小或大的變更,這些變更主要聚焦于以下幾點:
- Bug 修復(fù)、新功能添加;
- 調(diào)度性能優(yōu)化、調(diào)度器可觀測性提升;
- 新的調(diào)度插件/算法支持;
- 調(diào)度器相關(guān)特性版本升級;
- 目錄結(jié)構(gòu)調(diào)整、代碼結(jié)構(gòu)調(diào)整、代碼優(yōu)化;
- 命令行 Flag 棄用、新增、變更等;
- ...
四、Pod 調(diào)度器流程概覽
下圖展示了調(diào)度器調(diào)度 Pod 的總體流程:

kube-scheduler 在啟動后會通過 List-Watch 的方式,監(jiān)聽來自 kube-apiseraver 的 Pod、Node、PV、PVC 等資源的變更事件。
會將 Pod 變更事件放在 Scheduling Queue(調(diào)度隊列)中。 Scheduling Cycle(調(diào)度循環(huán))會不斷地從Scheduling Queue 中 POP 帶調(diào)度的 Pod,執(zhí)行調(diào)度流程。
會將 Node、Pod、PV、PVC 等資源,緩存在 Cache 中,緩存在 Cache 中的信息是經(jīng)過加工的信息。在Scheduling Cycle 中會被直接使用,以提高調(diào)度性能。
主循環(huán)從隊列 POP 出一個 Pod 進入 Scheduling Cycle,在這里依次執(zhí)行預(yù)過濾、打分等插件邏輯,結(jié)合 Cache 中的資源快照挑選可行節(jié)點。如果沒有節(jié)點滿足需求,則走 Preemption 分支嘗試搶占低優(yōu)先級 Pod。若仍失敗,則把當前 Pod 標記為不可調(diào)度并回到隊列等待下次機會。
一旦確認“Schedulable”,調(diào)度器進入 Binding Cycle,將所選節(jié)點寫回 Pod.spec.nodeName 并調(diào)用 Bind 擴展或直接向 apiserver 發(fā)起 Bind 請求。綁定成功后,調(diào)度器的任務(wù)告一段落,Pod 對象被標記為已綁定,接下來由目標節(jié)點上的 kubelet 接管,完成鏡像拉取、容器創(chuàng)建等運行階段。
整個流程依靠事件驅(qū)動、緩存快照和多階段插件體系實現(xiàn)高吞吐與實時性,并通過重回隊列、搶占等機制保證在資源緊張時仍能盡量滿足調(diào)度需求。
五、Kubernetes 調(diào)度器的擴展方式
在企業(yè)的生產(chǎn)集群中,通常都會對調(diào)度器進行輕度或深度的定制或擴展,那么調(diào)度器有哪些擴展方式呢?通常我們可以通過以下 3 種方式來擴展 Kubernetes 調(diào)度器:
擴展方式 | 擴展方式介紹 |
自定義調(diào)度器 | 自定義調(diào)度器就是自己開發(fā)一個類似 kube-scheduler 的調(diào)度器,根據(jù)部署方式,又分為以下 2 種: |
Scheduler Extender | Scheduler 社區(qū)最初提供的方案是通過 Extender 的形式來擴展 scheduler。Extender 是外部服務(wù),支持 Filter、Preempt、Prioritize 和 Bind 的擴展,scheduler 運行到相應(yīng)階段時,通過調(diào)用 Extender 注冊的 webhook 來運行擴展的邏輯,影響調(diào)度流程中各階段的決策結(jié)果。當前社區(qū)已不建議使用這種擴展方式; |
Scheduling Framework | Scheduling Framework 通過 Plugin API 定義了多個擴展點,調(diào)度插件能夠通過實現(xiàn)對應(yīng)擴展點的 API 接口,注冊到調(diào)度框架中,在合適的時機被調(diào)用。調(diào)度插件在某些擴展點能改變調(diào)度決策,而某些擴展點則可以用于調(diào)度相關(guān)消息的通知。Scheduling Framework 也是社區(qū)當前推薦的一種方式。 |
上面 3 種調(diào)度器擴展方法中,Scheduler Extender 和 Scheduling Framework 2 種擴展方式,是 Kubernetes 調(diào)度器自身提供的擴展機制,也是企業(yè)常使用的方式。在調(diào)度器沒有支持 Scheduling Framework 擴展方式之前,各大公有云廠商,很多都采用了 Scheduler Extender 調(diào)度器擴展方式。但在社區(qū)推出了 Scheduling Framework 擴展范式之后,越來越多的廠商選擇使用 Scheduling Framework 方式來擴展調(diào)度器。
1. 自定義調(diào)度器
自定義調(diào)度器指的是開發(fā)一個新的調(diào)度器組件來調(diào)度 Pod。自定義調(diào)度器的開發(fā)方式多種多樣,例如:可以直接基于 kue-scheduler 魔改一套,也可以使用 Scheduling Framework 開發(fā)一個新的調(diào)度器。
不建議直接基于 kube-scheduler 魔改一個新的調(diào)度器作為自定義調(diào)度器,因為魔改的 kube-scheduler 后期很難跟 Kubernetes 項目的 kube-scheduler 組件在代碼、特性、架構(gòu)等方面保持一致。
(1) 自定義調(diào)度器部署方式

根據(jù)自定義調(diào)度器的部署方式又分為以下 2 種:
- 默認調(diào)度器:也即新的調(diào)度器組件替換掉 kube-scheduler,集群中只有一個調(diào)度器組件在運行;
- 多調(diào)度器:多調(diào)度器指的是 Kubernetes 集群中,同時部署 2 個及以上的調(diào)度器組件來調(diào)度 Pod,不同調(diào)度器調(diào)度分配給它的 Pod。例如:同時部署 kube-sheduler 和新的調(diào)度器組件。這些自定義調(diào)度器只會調(diào)度 Pod .spec.schedulerName 字段值為自己名字的 Pod。這里需要注意,多調(diào)度器場景下,也要設(shè)置默認的調(diào)度器。否則,一個 Pod 如何沒有指定 .spec.schedulerName,那么這個 Pod 會一直處在 Pending 狀態(tài),無法得到調(diào)度,這不是我們期望看到的狀態(tài)。所以,我們需要給 Pod 設(shè)置一個默認的調(diào)度器。
(2) 自定義調(diào)度器架構(gòu)
在開發(fā)自定義調(diào)度器時,有以下 4 種常見的架構(gòu)設(shè)計方式:

- 單體式調(diào)度器: 使用復(fù)雜的調(diào)度算法結(jié)合集群的全局信息,計算出高質(zhì)量的放置點,不過延遲較高。如 Google 的 Borg, 開源的 Kubernetes 調(diào)度器;
- 兩級調(diào)度器: 通過將資源調(diào)度和作業(yè)調(diào)度分離,解決單體式調(diào)度器的局限性。兩級調(diào)度器采用悲觀并發(fā)的模型實現(xiàn)多調(diào)度器并發(fā)調(diào)度,允許根據(jù)特定的應(yīng)用做不同的作業(yè)調(diào)度邏輯,且同時保持了不同作業(yè)之間共享集群資源的特性,可是無法實現(xiàn)高優(yōu)先級應(yīng)用的搶占。具有代表性的系統(tǒng)是 Apache Mesos 和 Hadoop YARN。
- 共享狀態(tài)調(diào)度器: 通過半分布式的方式來解決單體調(diào)度器和兩級調(diào)度器的局限性,多個實例間采用樂觀并發(fā)的方式解決沖突:每個調(diào)度器都擁有一份集群全量狀態(tài)的副本,且調(diào)度器獨立對集群狀態(tài)副本進行更新,一旦本地的狀態(tài)副本發(fā)生變化,整個集群的狀態(tài)信息就會被更新。并引入一個協(xié)調(diào)器來解決沖突。具有代表性的系統(tǒng)是 Google 的 Omega, 微軟的 Apollo, 字節(jié)跳動的 Godel。
- 全分布式調(diào)度器: 多個調(diào)度器實例,各自使用較為簡單的調(diào)度算法以實現(xiàn)針對大規(guī)模的高吞吐、低延遲并行任務(wù)的放置。與兩級調(diào)度調(diào)度框架不同的是,每個調(diào)度器并沒有負責的分區(qū)。作業(yè)可以提交給任意的調(diào)度器,并且每個調(diào)度器可以將作業(yè)發(fā)送到集群中任何的節(jié)點上執(zhí)行。該架構(gòu)因為去掉了中心化的沖突解決,吞吐量相對較高;但因為是基于最少知識做出快速決策而設(shè)計,無法支持或承擔復(fù)雜或特定應(yīng)用的調(diào)度策略。代表性系統(tǒng)如加州大學(xué)的 Sparrow。
- 混合調(diào)度器: 將工作負載分散到集中式和分布式組件上,對長時間運行的任務(wù)使用復(fù)雜算法,對短時間運行的任務(wù)則依賴于分布式布局。微軟 Mercury 就采取了這種這種方案。
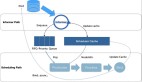
(3) 基于共享狀態(tài)的雙調(diào)度器
集群中同時存在兩個調(diào)度器,一個負責調(diào)度在線業(yè)務(wù),一個負責調(diào)度離線作業(yè)。阿里 Sigma + Fuxi, 騰訊 Caelus 調(diào)度器均類似該方案。在具體實現(xiàn)上,以騰訊 Caelus 為例:

- kube-scheduler: K8s 原生調(diào)度器,負責在線業(yè)務(wù)調(diào)度
- mg-scheduler: 自研 Batch 調(diào)度器,負責離線作業(yè)調(diào)度
- coordinator: 協(xié)調(diào)器,負責在離線調(diào)度器沖突時的仲裁
(4) 基于共享狀態(tài)的統(tǒng)一調(diào)度器
以字節(jié)跳動的 Godel 調(diào)度器為例:

(5) 自定義調(diào)度器優(yōu)缺點
自定義調(diào)度器有優(yōu)點,也有缺點。整體來說缺點大于優(yōu)點,其優(yōu)缺點如下:
優(yōu)點 | + 可以突破原生 Scheduler 的單體架構(gòu)限制,通過架構(gòu)擴展進一步提升性能; + 可以完全定制,可擴展性強。 |
缺點 | + 研發(fā)和維護成本高,社區(qū)的新功能或插件可能難以復(fù)用; |
2. Scheduler Extender 調(diào)度器擴展

Scheduler Extender 是早期的 Scheduler 擴展方式,本質(zhì)上是一種 Webhook:Scheduler 在一些特定的擴展點,對 Extender 組件發(fā)起 RPC 調(diào)用,獲取調(diào)度策略的結(jié)果。
可以通過 Scheduler Extender 的方式,在原生 Scheduler 的基礎(chǔ)上,實現(xiàn) Gang/Binpack/拓撲感知調(diào)度/GPU 共享調(diào)度等功能。
使用 Scheduler Extender 的方式擴展調(diào)度器,優(yōu)點是可以以對 kube-scheduler 代碼無侵入的方式來擴展自定義的調(diào)度策略,這種方式維護成本相較于自定義調(diào)度器,維護成本較低。但這種方法也有缺點,主要缺點如下:
① 性能差:通過 RPC 方式調(diào)用,且引入 JSON 編解碼開銷,性能遠低于本地函數(shù)調(diào)用,對調(diào)度器性能影響較大;
可擴展性差:
- 可擴展點有限,只有 Filter/Priority/Bind/Permit 幾個階段;
- 可擴展的位置固定,只能在默認調(diào)度策略全部執(zhí)行完后調(diào)用。
③ 無法共享 Cache:Extender 無法共享 Scheduler 的 Cache, 如果 RPC 調(diào)用的參數(shù)無法滿足 Extender 的需求,需要自行與 kube-apiserver 通信,并額外建立 Cache。
3. Scheduling Framework 方式擴展

因為 Scheduler Extender 調(diào)度器擴展方式有一些缺點,所以 Kubernetes 社區(qū)開發(fā)出了一種新的調(diào)度器擴展方式:Scheduling Framework。Scheduling Framework 在 v1.15 版本 Alpha 發(fā)布,在 v1.19 版本 GA。,是當前 Kubernetes 社區(qū)推薦的一種擴展方式,已經(jīng)被大量一線企業(yè)采用。
Scheduling Framework 機制在原有的調(diào)度流程中定義了豐富擴展點接口,可以通過實現(xiàn)擴展點所定義的接口來實現(xiàn)插件,將插件注冊到擴展點。Scheduling Framework 在執(zhí)行調(diào)度流程時,運行到相應(yīng)的擴展點時,會調(diào)用注冊的插件,影響調(diào)度決策的結(jié)果。因此,開發(fā)者可以通過實現(xiàn)一系列 Plugin, 支持我們對調(diào)度的擴展需求。
(1) Multi Scheduling Profiles 特性支持
隨著 Kubernetes 調(diào)度器擴展能力的演進,在 v1.18 版本,Kubernetes 發(fā)布了處于 Alpha 階段( v1.19 Beta,v1.22 GA)的 Multi Scheduling Profiles 擴展能力。該特性使得 kube-scheduler 可以實現(xiàn)對于不同 Workload 的差異化調(diào)度策略支持,比如:
- 在線業(yè)務(wù) Pod 可能需要經(jīng)過 Spread 策略打散;
- 離線作業(yè) Pod 可能需要經(jīng)過 Gang/Binpack 等策略。
使用 Multi Scheduling Profiles 特性也很簡單,只需要在 KubeSchedulerConfiguration 配置文件中定義一系列 Profile, 每個 Profile 擁有特定的名稱,并支持配置一系列 Plugin 組合。之后,在 Pod 定義的 .spec.schedulerName 字段,引用上述某個 Profile 的名稱即可。kube-scheduler 在調(diào)度該 Pod 的過程中,只會執(zhí)行 Profile 中指定的插件。
(2) Scheduling Framework 優(yōu)缺點
使用 Scheduling Framework 來擴展調(diào)度器也有一些優(yōu)缺點,整體來說是優(yōu)點大于缺點。優(yōu)缺點如下:
優(yōu)點 | + 標準化:相比純自研調(diào)度器,用戶和開發(fā)者對原生調(diào)度器的熟悉程度和接受程度更高; + 可擴展性好:良好的插件機制,且可擴展點多,能夠滿足各種定制化的需求; + 性能:相比 Extender 模式,擁有較好的性能。 |
缺點 | 仍然為單實例運行模式,性能可能比自研共享狀態(tài)架構(gòu)的調(diào)度器差。 |
六、總結(jié)
Kubernetes 集群擁有多種調(diào)度手段以決定 Pod 落到哪臺節(jié)點上運行,其中最核心的是由 kube-scheduler 承擔的統(tǒng)一調(diào)度流程。
Pod 為什么需要調(diào)度?原因來自節(jié)點硬件、資源利用率、可用性及拓撲差異等多維度差異,以及企業(yè)對“高資源利用率”與“業(yè)務(wù)穩(wěn)定”之間平衡的追求。
隨著集群規(guī)模與業(yè)務(wù)類型日益多樣,社區(qū)為調(diào)度器提供了三條主要擴展路徑:完全自研的“自定義調(diào)度器”、通過 Webhook 調(diào)用的 Scheduler Extender,以及當下最被推薦的 Scheduling Framework 插件體系。
在框架模式下,開發(fā)者可在多個擴展點插入自研插件,并借助 Multi Scheduling Profiles 針對不同工作負載組合不同插件,實現(xiàn)諸如打散、Binpack、Gang 等策略。
對比來看,自定義調(diào)度器靈活卻維護成本高,Extender 侵入小但性能與擴展點受限,而 Scheduling Framework 在標準、性能與可擴展性之間取得了較好平衡,因此逐漸成為企業(yè)定制調(diào)度的主流選擇。