面向商業應用的深度學習圖像字幕技術
譯文【51CTO.com快譯】采用人工智能技術將圖像上的像素序列轉換成文字的技術如今已經不像5年前或更早以前那么原始了。更好的性能、準確性、可靠性使從社交媒體到電子商務的不同領域的圖像字幕變得平滑、高效成為可能。而標簽的自動創建與下載的圖像相對應。
本文介紹了圖像字幕技術的用例、基本結構、優缺點,此外還部署了能夠為輸入圖像上顯示的內容創建有意義的描述的模型。
作為一種視覺語言目標,圖像字幕可以借助計算機視覺和自然語言處理來解決。人工智能部分采用卷積神經網絡(CNN)和遞歸神經網絡(RNN)或任何適用的模型來達到目標。
在討論技術細節之前,先了解一下圖像字幕的位置。
人工智能驅動的圖像標記和描述用例
微軟公司技術研究員、Azure人工智能認知服務公司首席技術官Xuedong Huang指出:“圖像字幕是計算機視覺的核心功能之一,可以實現廣泛的服務。”
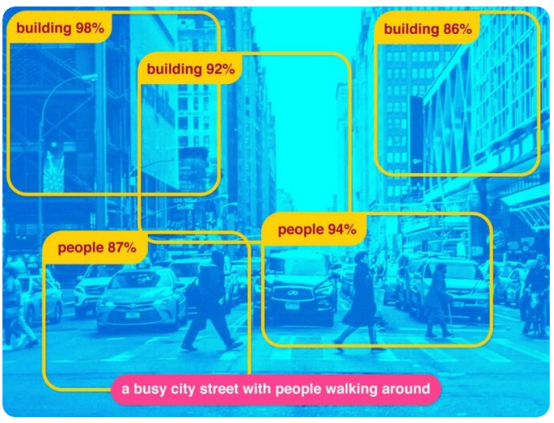
他的這一觀點是有道理的,因為圖像字幕技術已經有了廣泛的應用,即電子商務中的圖像標簽、照片共享服務和在線目錄。
在這種情況下,可以根據圖像自動創建標簽。例如,當用戶上傳圖像到在線目錄時,可以生成圖像字幕并簡化用戶的操作。在這種情況下,人工智能識別圖像并生成屬性——這些屬性可以是簽名、類別或描述。這項技術還可以確定物品的類型、材料、顏色、圖案,以及適合網上商店銷售的商品。
與此同時,圖像字幕可以通過圖像共享服務或任何在線目錄來實現,為搜索引擎優化或分類目的自動創建有意義的圖像描述。此外,圖像字幕技術還允許檢查圖像是否符合平臺的發布規則。在這里,它可以作為卷積神經網絡(CNN)分類的替代,有助于增加流量和收入。
注:為視頻創建描述是一個更加復雜的任務。不過,目前的技術狀況已經使它成為可能。
(1)盲人自動圖像標注
為了開發這樣的解決方案,需要將圖像轉換為文本,然后再轉換為語音。這是深度學習技術的兩個著名應用。
微軟公司開發的一款名為“Seeing AI”的應用程序可以讓視力有問題的用戶采用智能手機看到周圍的世界。當手機攝像頭對準前方事物時,其應用程序可以將圖像轉換成文本并給出聲音提示,還可以識別打印和手寫文本,也可以識別物體和人員。
谷歌公司也推出了一種可以為圖像創建文本描述的工具,允許盲人或視力有問題的人理解圖像或所在的場景。該機器學習工具由多個層組成。第一個模型識別圖片中的文本和手寫數字。然后,另一個模型識別周圍世界的對象,如汽車、樹木、動物等。第三層是一個高級模型,能夠在完整的文本描述中找到概要描述。
(2)社交媒體的人工智能圖片字幕
借助基于人工智能工具生成的圖像字幕已經可用于Facebook和instagram。此外,其模型將變得更智能,學習識別新對象、動作和模式。
Facebook在近五年前創建了一個能夠創建Alt文本描述的系統。現在它變得更準確了。以前使用一般的文字來描述圖像,但現在這個系統可以生成詳細的描述。
人工智能標識
圖像字幕技術也正在與其他人工智能技術一起部署。例如,DeepLogo是一個基于TensorFlow對象檢測API的神經網絡。它可以識別標識。標識字的名稱作為圖像字幕顯示。基于生成對抗神經網絡(GAN)的字形合成模型的研究可以揭示生成對抗神經網絡(GAN)的工作原理。
圖像字幕深度學習模型研究
在此應用了一個為圖像創建有意義的文本描述的模型,同時牢記可能的用例。例如,圖像字幕可以描述一個動作和對象,它們是每個圖像上的主要對象。對于訓練模型,可以使用Microsoft COCO2014數據集。COCO數據集是大規模目標檢測、分割和字幕數據集。它包含了大約150萬件不同的物品,分為80個類別。每個圖像都帶有五個人工生成的字幕。
采用Andrej Karpathy的訓練、驗證和測試分割,可以將數據集劃分為訓練、驗證和測試部分。此外,還需要像BLEU、ROUGE、METEOR、CIDEr、SPICE等參數來評估結果。
圖像字幕的機器學習模型比較
在通常情況下,圖像字幕的基線架構將輸入編碼成固定形式,并逐字解碼成序列。
編碼器編碼的輸入圖像與三個顏色通道成為一個更小的打印與學習通道。這個較小的編碼圖像是原始圖像中有用信息的摘要。對于編碼,可以應用任何一個卷積神經網絡(CNN)架構。此外,可以對編碼器部分使用遷移學習。
解碼器查看已經編碼的圖像并逐字生成字幕。然后,每個預測的單詞被用來創建下一個單詞。在繼續實施之前,先看看通過模型創建和使用Meshed-Memory轉換器模型進行測試得到了什么結果。



基于人工智能的圖像字幕
此外還研究了導致錯誤的例子。出現錯誤通常有幾個原因,最常見的錯誤是圖像質量差和初始數據集中缺少某些元素。該模型是在一個包含一般圖片的數據集上訓練的,所以當它不知道內容或不能正確識別它時就會出錯。這和人類大腦的工作方式是一樣的。


這里有另一個例子來說明神經網絡是如何運作的。例如數據集模型中沒有老虎,與其相反,人工智能系統會選擇它所知道的最近的物體,這和人類的大腦處理未知事物是一樣的。

圖像字幕的自上而下的注意力模型
自上而下的注意力模型是第一個可供比較的模型。自上而下的注意力機制結合了自下而上和自上而下的注意力機制。
Faster R-CNN用于建立目標檢測和圖像字幕任務之間的聯系。由于利用了各行業領域知識,區域建議模型在目標檢測數據集上進行了預先訓練。此外,與其他一些注意力機制不同的是,這兩個模型都使用了帶有自上而下的注意力機制。
使用Faster R-CNN(圖5A)進行圖像特征提取。FasterR-CNN是一種對象檢測模型,用于識別屬于特定類別的對象,并使用包圍框對其進行定位。Faster R-CNN檢測物體分為兩個階段。
第一階段被稱為區域建議網絡(RPN),用于預測對象建議。采用具有交并比(IoU)和非極大值抑制(NMS),選擇頂框方案作為第二階段的輸入。
在第二階段,使用感興趣區域(RoI)池為每個框提議提取一個很小的特征圖(例如14×14)。然后,這些特征圖被批處理在一起,作為卷積神經網絡(CNN)最后一層的輸入。因此,最終的模型輸出包括一個softmax分布在類標簽上,以及每個框提議的特定于類的邊界框細化。
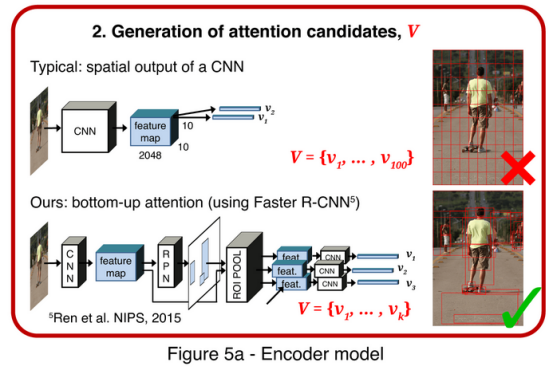
例如上圖中建議的字幕模型使用一個自上而下的注意力機制,在字幕生成過程中衡量每個特征。這是帶有上下注意機制的長短期記憶網絡(LSTM)。較高的層次上,字幕模型由兩個LSTM層組成。
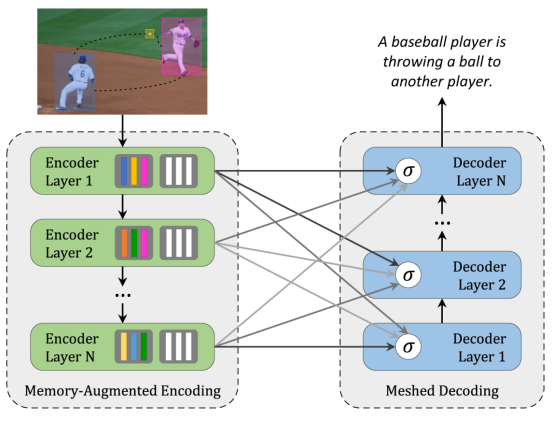
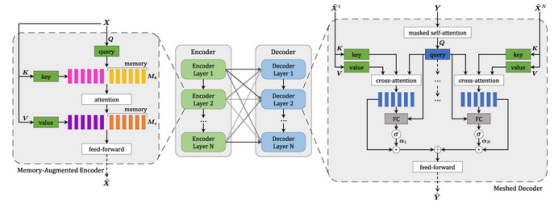
用于圖像字幕的Meshed-Memory 轉換器模型
另一個用來解決圖像字幕任務的模型是Meshed-Memory 轉換器。它由編碼器和解碼器部分組成,并由多個層次堆疊而成。編碼器還包括前饋層,解碼器具有加權的可學習機制。
圖像的區域是用多級方式編碼的。該模型同時考慮了低級和高級關系。所學的知識被編碼為記憶向量。編碼器和解碼器部分的層連接在一個網狀結構。解碼器從每個編碼層的輸出中讀取,并對單詞進行自我注意,對整個編碼層進行交叉注意,然后對結果進行調制和求和。
因此,該模型不僅可以利用圖像的視覺內容,還可以利用編碼器的先驗知識。
兩種圖像字幕模型的比較
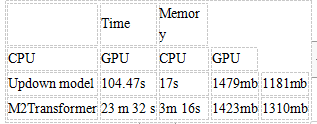
根據研究,可以比較Updown模型和M2 Transformer模型,因為它們是在相同的數據上訓練的。以下兩個圖表提供了這兩種模型的比較。
表1 評估指標

表2 推斷時間和記憶
圖像字幕:結果分析和未來展望
兩種模型都顯示出相當好的結果。在他們的幫助下,可以為數據集中的大多數圖像生成有意義的字幕。此外,由于使用Faster-RCNN進行特征預提取,并在龐大的Visual Genome數據集上進行預訓練,該模型可以識別人們日常生活中的許多對象和行為,從而正確描述它們。
有什么區別?
Updown模型比M2 Transformer更快、更輕量。原因是M2 Transformer使用了更多的技術,比如編碼器和解碼器之間的額外(“網格”)連接,以及用于記憶過去經驗的記憶向量。此外,這些模型使用不同的注意力機制。
自上而下的注意可以一次完成,而M2 Transformer中使用的多頭注意力應該并行運行幾次。然而,根據獲得的指標,M2 Transformer取得了更好的結果。在它的幫助下,可以生成更正確、更多樣的字幕。M2 Transformer預測在描述數據集的圖像和其他一些相關圖像時包含較少的不準確性。因此,它能更好地完成主要任務。
本文比較了這兩種模型,但也有其他方法來完成圖像字幕的任務。它可以改變解碼器和編碼器,使用各種單詞向量,合并數據集,并采用遷移學習。
可以對該模型進行改進,以實現更適合特定業務的結果,無論是作為一個應用程序,可以為有視力問題的人員或作為額外的工具嵌入電子商務平臺。為了達到這個目標,模型應該在相關的數據集上進行訓練。例如,對于一個能夠正確描述衣服的系統來說,最好是在帶有衣服的數據集上進行訓練。
原文標題:Deep Learning Image Captioning Technology for Business Applications,作者:MobiDev
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】