看得“深”、看得“清” —— 深度學(xué)習(xí)在圖像超清化的應(yīng)用
日復(fù)一日的人像臨摹練習(xí)使得畫家能夠僅憑幾個關(guān)鍵特征畫出完整的人臉。同樣地,我們希望機器能夠通過低清圖像有限的圖像信息,推斷出圖像對應(yīng)的高清細節(jié),這就需要算法能夠像畫家一樣“理解”圖像內(nèi)容。至此,傳統(tǒng)的規(guī)則算法不堪重負,新興的深度學(xué)習(xí)照耀著圖像超清化的星空。
絡(luò)在圖像超清化上的應(yīng)用")
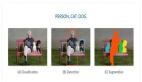
圖1 ***的Pixel遞歸網(wǎng)絡(luò)在圖像超清化上的應(yīng)用
(左圖為低清圖像,右圖為其對應(yīng)的高清圖像,中間為算法生成結(jié)果。
這是4倍超清問題,即將邊長擴大為原來的4倍。)
得益于硬件的迅猛發(fā)展,短短幾年間,手機已更新了數(shù)代,老手機拍下的照片在大分辨率的屏幕上變得模糊起來。同樣地,圖像分辨率的提升使得網(wǎng)絡(luò)帶寬的壓力驟增。如此,圖像超清化算法就有了用武之地。
對于存放多年的老照片,我們使用超清算法令其細節(jié)栩栩如生;面對網(wǎng)絡(luò)傳輸?shù)膸拤毫Γ覀兿葘D像壓縮傳輸,再用超清化算法復(fù)原,這樣可以大大減少傳輸數(shù)據(jù)量。
傳統(tǒng)的幾何手段如三次插值,傳統(tǒng)的匹配手段如碎片匹配,在應(yīng)對這樣的需求上皆有心無力。
深度學(xué)習(xí)的出現(xiàn)使得算法對圖像的語義級操作成為可能。本文即是介紹深度學(xué)習(xí)技術(shù)在圖像超清化問題上的***研究進展。
深度學(xué)習(xí)最早興起于圖像,其主要處理圖像的技術(shù)是卷積神經(jīng)網(wǎng)絡(luò),關(guān)于卷積神經(jīng)網(wǎng)絡(luò)的起源,業(yè)界公認是Alex在2012年的ImageNet比賽中的煌煌表現(xiàn)。雖方五年,卻已是老生常談。因此卷積神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)細節(jié)本文不再贅述。在下文中,使用CNN(Convolutional Neural Network)來指代卷積神經(jīng)網(wǎng)絡(luò)。
CNN出現(xiàn)以來,催生了很多研究熱點,其中最令人印象深刻的五個熱點是:
- 深廣探索:VGG網(wǎng)絡(luò)的出現(xiàn)標志著CNN在搜索的深度和廣度上有了初步的突破。
- 結(jié)構(gòu)探索:Inception及其變種的出現(xiàn)進一步增加了模型的深度。而ResNet的出現(xiàn)則使得深度學(xué)習(xí)的深度變得“名副其實”起來,可以達到上百層甚至上千層。
- 內(nèi)容損失:圖像風(fēng)格轉(zhuǎn)換是CNN在應(yīng)用層面的一個小高峰,涌現(xiàn)了一批以Prisma為首的小型創(chuàng)業(yè)公司。但圖像風(fēng)格轉(zhuǎn)換在技術(shù)上的真正貢獻卻是通過一個預(yù)訓(xùn)練好的模型上的特征圖,在語義層面生成圖像。
- 對抗神經(jīng)網(wǎng)絡(luò)(GAN):雖然GAN是針對機器學(xué)習(xí)領(lǐng)域的架構(gòu)創(chuàng)新,但其最初的應(yīng)用卻是在CNN上。通過對抗訓(xùn)練,使得生成模型能夠借用監(jiān)督學(xué)習(xí)的東風(fēng)進行提升,將生成模型的質(zhì)量提升了一個級別。
- Pixel CNN:將依賴關(guān)系引入到像素之間,是CNN模型結(jié)構(gòu)方法的一次比較大的創(chuàng)新,用于生成圖像,效果***,但有失效率。
這五個熱點,在圖像超清這個問題上都有所體現(xiàn)。下面會一一為大家道來。
CNN的***次出手
用于圖像超清問題的CNN網(wǎng)絡(luò)結(jié)構(gòu)")
圖2 ***應(yīng)用于圖像超清問題的CNN網(wǎng)絡(luò)結(jié)構(gòu)
(輸入為低清圖像,輸出為高清圖像.該結(jié)構(gòu)分為三個步驟:
低清圖像的特征抽取、低清特征到高清特征的映射、高清圖像的重建。)
圖像超清問題的特點在于,低清圖像和高清圖像中很大部分的信息是共享的,基于這個前提,在CNN出現(xiàn)之前,業(yè)界的解決方案是使用一些特定的方法,如PCA、Sparse Coding等將低分辨率和高分辨率圖像變?yōu)樘卣鞅硎荆缓髮⑻卣鞅硎咀鲇成洹?/p>
基于傳統(tǒng)的方法結(jié)構(gòu),CNN也將模型劃分為三個部分,即特征抽取、非線性映射和特征重建。由于CNN的特性,三個部分的操作均可使用卷積完成。因而,雖然針對模型結(jié)構(gòu)的解釋與傳統(tǒng)方法類似,但CNN卻是可以同時聯(lián)合訓(xùn)練的統(tǒng)一體,在數(shù)學(xué)上擁有更加簡單的表達。
不僅在模型解釋上可以看到傳統(tǒng)方法的影子,在具體的操作上也可以看到。在上述模型中,需要對數(shù)據(jù)進行預(yù)處理,抽取出很多patch,這些patch可能互有重疊,將這些Patch取合集便是整張圖像。上述的CNN結(jié)構(gòu)是被應(yīng)用在這些Patch而不是整張圖像上,得到所有圖像的patch后,將這些patch組合起來得到***的高清圖像,重疊部分取均值。
更深更快更準的CNN
構(gòu)")
圖3 基于殘差的深度CNN結(jié)構(gòu)
(該結(jié)構(gòu)使用殘差連接將低清圖像與CNN的輸出相加得到高清圖像,即僅用CNN結(jié)構(gòu)學(xué)習(xí)低清圖像中缺乏的高清細節(jié)部分。)
圖2中的方法雖然效果遠高于傳統(tǒng)方法,但是卻有若干問題:
- 訓(xùn)練層數(shù)少,沒有足夠的視野域;
- 訓(xùn)練太慢,導(dǎo)致沒有在深層網(wǎng)絡(luò)上得到好的效果;
- 不能支持多種倍數(shù)的高清化。
針對上述問題,圖3算法提出了采用更深的網(wǎng)絡(luò)模型。并用三種技術(shù)解決了圖2算法的問題。
***種技術(shù)是殘差學(xué)習(xí),CNN是端到端的學(xué)習(xí),如果像圖2方法那樣直接學(xué)習(xí),那么CNN需要保存圖像的所有信息,需要在恢復(fù)高清細節(jié)的同時記住所有的低分辨率圖像的信息。如此,網(wǎng)絡(luò)中的每一層都需要存儲所有的圖像信息,這就導(dǎo)致了信息過載,使得網(wǎng)絡(luò)對梯度十分敏感,容易造成梯度消失或梯度爆炸等現(xiàn)象。而圖像超清問題中,CNN的輸入圖像和輸出圖像中的信息很大一部分是共享的。殘差學(xué)習(xí)是只針對圖像高清細節(jié)信息進行學(xué)習(xí)的算法。如上圖所示,CNN的輸出加上原始的低分辨率圖像得到高分辨率圖像,即CNN學(xué)習(xí)到的是高分辨率圖像和低分辨率圖像的差。如此,CNN承載的信息量小,更容易收斂的同時還可以達到比非殘差網(wǎng)絡(luò)更好的效果。
高清圖像之所以能夠和低清圖像做加減法,是因為,在數(shù)據(jù)預(yù)處理時,將低清圖像使用插值法縮放到與高清圖像同等大小。于是雖然圖像被稱之為低清,但其實圖像大小與高清圖像是一致的。
第二種技術(shù)是高學(xué)習(xí)率,在CNN中設(shè)置高學(xué)習(xí)率通常會導(dǎo)致梯度爆炸,因而在使用高學(xué)習(xí)率的同時還使用了自適應(yīng)梯度截斷。截斷區(qū)間為[-θ/γ, θ/γ],其中γ為當前學(xué)習(xí)率,θ是常數(shù)。
第三種技術(shù)是數(shù)據(jù)混合,最理想化的算法是為每一種倍數(shù)分別訓(xùn)練一個模型,但這樣極為消耗資源。因而,同之前的算法不同,本技術(shù)將不同倍數(shù)的數(shù)據(jù)集混合在一起訓(xùn)練得到一個模型,從而支持多種倍數(shù)的高清化。
感知損失
在此之前,使用CNN來解決高清問題時,對圖像高清化的評價方式是將CNN生成模型產(chǎn)生的圖像和實際圖像以像素為單位計算損失函數(shù)(一般為歐式距離)。此損失函數(shù)得到的模型捕捉到的只是像素級別的規(guī)律,其泛化能力相對較弱。
而感知損失,則是指將CNN生成模型和實際圖像都輸入到某個訓(xùn)練好的網(wǎng)絡(luò)中,得到這兩張圖像在該訓(xùn)練好的網(wǎng)絡(luò)上某幾層的激活值,在激活值上計算損失函數(shù)。
由于CNN能夠提取高級特征,那么基于感知損失的模型能夠?qū)W習(xí)到更魯棒更令人信服的結(jié)果。
格轉(zhuǎn)換網(wǎng)絡(luò)")
圖4 基于感知損失的圖像風(fēng)格轉(zhuǎn)換網(wǎng)絡(luò)
(該網(wǎng)絡(luò)也可用于圖像超清問題。
左側(cè)是一個待訓(xùn)練的轉(zhuǎn)換網(wǎng)絡(luò),用于對圖像進行操作;
右側(cè)是一個已訓(xùn)練好的網(wǎng)絡(luò),將使用其中的幾層計算損失。)
圖4即為感知損失網(wǎng)絡(luò),該網(wǎng)絡(luò)本是用于快速圖像風(fēng)格轉(zhuǎn)換。在這個結(jié)構(gòu)中,需要訓(xùn)練左側(cè)的Transform網(wǎng)絡(luò)來生成圖像,將生成的圖像Y和內(nèi)容圖像與風(fēng)格圖像共同輸入進右側(cè)已經(jīng)訓(xùn)練好的VGG網(wǎng)絡(luò)中得到損失值。如果去掉風(fēng)格圖像,將內(nèi)容圖像變?yōu)楦咔鍒D像,將輸入改為低清圖像,那么這個網(wǎng)絡(luò)就可以用于解決圖像超清問題了。
對抗神經(jīng)網(wǎng)絡(luò)(GAN)
練的生成網(wǎng)絡(luò)G和判別網(wǎng)絡(luò)結(jié)構(gòu)D")
圖5 對抗訓(xùn)練的生成網(wǎng)絡(luò)G和判別網(wǎng)絡(luò)結(jié)構(gòu)D
(上半部分是生成網(wǎng)絡(luò)G,層次很深且使用了residual block和skip-connection結(jié)構(gòu);
下半部分是判別網(wǎng)絡(luò)D。)
對抗神經(jīng)網(wǎng)絡(luò)稱得上是近期機器學(xué)習(xí)領(lǐng)域***的變革成果。其主要思想是訓(xùn)練兩個模型G和D。G是生成網(wǎng)絡(luò)而D是分類網(wǎng)絡(luò),G和D都用D的分類準確率來進行訓(xùn)練。G用于某種生成任務(wù),比如圖像超清化或圖像修復(fù)等。G生成圖像后,將生成圖像和真實圖像放到D中進行分類。使用對抗神經(jīng)網(wǎng)絡(luò)訓(xùn)練模型是一個追求平衡的過程:保持G不變,訓(xùn)練D使分類準確率提升;保持D不變,訓(xùn)練G使分類準確率下降,直到平衡。GAN框架使得無監(jiān)督的生成任務(wù)能夠利用到監(jiān)督學(xué)習(xí)的優(yōu)勢來進行提升。
基于GAN框架,只要定義好生成網(wǎng)絡(luò)和分類網(wǎng)絡(luò),就可以完成某種生成任務(wù)。
而將GAN應(yīng)用到圖像高清問題的這篇論文,可以說是集大成之作。生成模型層次深且使用了residual block和skip-connection;在GAN的損失函數(shù)的基礎(chǔ)上同時添加了感知損失。
GAN的生成網(wǎng)絡(luò)和分類網(wǎng)絡(luò)如圖5,其中,生成網(wǎng)絡(luò)自己也可以是一個單獨的圖像超清算法。論文中分析了GAN和non-GAN的不同,發(fā)現(xiàn)GAN主要在細節(jié)方面起作用,但無法更加深入地解釋。“無法解釋性”也是GAN目前的缺點之一。
像素遞歸網(wǎng)絡(luò)(Pixel CNN)
圖5中的GAN雖然能夠達到比較好的效果,但是由于可解釋性差,難免有套用之嫌。
其實,對于圖像超清這個問題來說,存在一個關(guān)鍵性的問題,即一張低清圖像可能對應(yīng)著多張高清圖像,那么問題來了。
假如我們把低分辨率圖像中需要高清化的部分分成A,B,C,D等幾個部分,那么A可能對應(yīng)A1,A2,A3,A4,B對應(yīng)B1,B2,B3,B4,以此類推。假設(shè)A1,B1,C1,D1對應(yīng)一張***的高清圖片。那么現(xiàn)有的算法可能生成的是A1,B2,C3,D4這樣的混搭,從而導(dǎo)致生成的高清圖像模糊。
為了驗證上述問題的存在,設(shè)想一種極端情況。

圖6 圖像超清模糊性問題分析圖示
(上半部分為分析問題所用數(shù)據(jù)集的構(gòu)建;
下半部分為現(xiàn)有的損失函數(shù)在這個問題上的效果。
可以通過對比看出,PixelCNN能夠防止這種模糊的出現(xiàn)。)
為了分析圖像模糊問題的成因,在圖6的上半部分,基于MNist數(shù)據(jù)集生成一個新的數(shù)據(jù)集。生成方法如下:將MNIST數(shù)據(jù)集中的圖片A長寬各擴大兩倍,每張圖片可以生成兩張圖片A1和A2,A1中A處于右下角,A2中A處于左上角。
把原圖當做低清圖片,生成的圖當成高清圖片。使用圖6下半部分所列舉的三種方法進行訓(xùn)練,得到的模型,在生成圖像的時候,會產(chǎn)生圖6下半部分的結(jié)果。即每個像素點可能等概率地投射到左上部分和右下部分,從而導(dǎo)致生成的圖片是錯誤的。而引入PixelCNN后,由于像素之間產(chǎn)生了依賴關(guān)系,很好地避免了這種情況的發(fā)生。
為了解決上述問題,需要在生成圖像的同時引入先驗知識。畫家在擁有了人臉的知識之后,就可以畫出令人信服的高清細節(jié)。類比到圖像超清問題中,先驗知識即是告知算法該選擇哪一種高清結(jié)果。
在圖像超清問題中,這樣的知識體現(xiàn)為讓像素之間有相互依賴的關(guān)系。這樣,就可以保證A、B、C、D四個不同的部分對于高清版的選擇是一致的。
絡(luò)結(jié)構(gòu)")
圖7 基于PixelCNN的解決圖像超清問題的CNN網(wǎng)絡(luò)結(jié)構(gòu)
(其中先驗網(wǎng)絡(luò)(prior network)為PixelCNN;
條件網(wǎng)絡(luò)(conditioning network)為圖像生成網(wǎng)絡(luò),
其結(jié)構(gòu)與作用同GAN中的生成網(wǎng)絡(luò)、感知損失中的轉(zhuǎn)換網(wǎng)絡(luò)均類似。)
模型架構(gòu)如圖7。其中條件網(wǎng)絡(luò)是一個在低清圖像的基礎(chǔ)上生成高清圖像的網(wǎng)絡(luò)。它能以像素為單位獨立地生成高清圖像,如同GAN中的G網(wǎng)絡(luò),感知損失中的轉(zhuǎn)換網(wǎng)絡(luò)。而先驗網(wǎng)絡(luò)則是一個Pixel CNN組件,它用來增加高清圖像像素間的依賴,使像素選擇一致的高清細節(jié),從而看起來更加自然。
那么Pixel CNN是如何增加依賴的呢?在生成網(wǎng)絡(luò)的時候,Pixel CNN以像素為單位進行生成,從左上角到右下角,在生成當前像素的時候,會考慮之前生成的像素。
若加上先驗網(wǎng)絡(luò)和條件網(wǎng)絡(luò)的混合, PixelCNN在生成圖像的時候,除了考慮前面生成的像素,還需要考慮條件網(wǎng)絡(luò)的結(jié)果。
總結(jié)
上述算法是圖像超清問題中使用的較為典型的CNN結(jié)構(gòu),此外,還有很多其他的結(jié)構(gòu)也達到了比較好的效果。隨著CNN網(wǎng)絡(luò)結(jié)構(gòu)層次的日益加深,距離實用場景反而越來越遠。譬如,基于GAN的網(wǎng)絡(luò)結(jié)構(gòu)的訓(xùn)練很難穩(wěn)定,且結(jié)果具有不可解釋性;基于PixelCNN的網(wǎng)絡(luò)在使用中由于要在pixel級別生成,無法并行,導(dǎo)致生成效率極為低下。
更進一步地,從實用出發(fā),可以在數(shù)據(jù)方向上進行進一步的優(yōu)化。譬如,現(xiàn)在的算法輸入圖像都是由低清圖像三次插值而來,那么,是否可以先用一個小網(wǎng)絡(luò)得到的結(jié)果來作為初始化的值呢?再如,多個小網(wǎng)絡(luò)串聯(lián)是否能得到比一個大網(wǎng)絡(luò)更好的結(jié)果等等。
圖像超清問題是一個相對來說比較簡單的圖像語義問題,相信這只是圖像語義操作的一個開始,今后越來越多的圖像處理問題將會因為CNN的出現(xiàn)迎刃而解。
參考文獻
[1] Dong C, Loy C C, He K, et al. Image super-resolution using deep convolutional networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 38(2): 295-307.
[2] Kim J, Kwon Lee J, Mu Lee K. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1646-1654.
[3] Johnson J, Alahi A, Fei-Fei L. Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision. Springer International Publishing, 2016: 694-711.
[4] Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network[J]. arXiv preprint arXiv:1609.04802, 2016.
[5] Dahl R, Norouzi M, Shlens J. Pixel Recursive Super Resolution[J]. arXiv preprint arXiv:1702.00783, 2017.