













微軟英偉達發(fā)布5300億NLP模型“威震天-圖靈”,花了4480塊A100
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
5300億參數(shù)!全球最大規(guī)模NLP模型誕生。
由微軟聯(lián)手英偉達推出,名叫威震天-圖靈自然語言生成模型(Megatron Turing-NLG)。
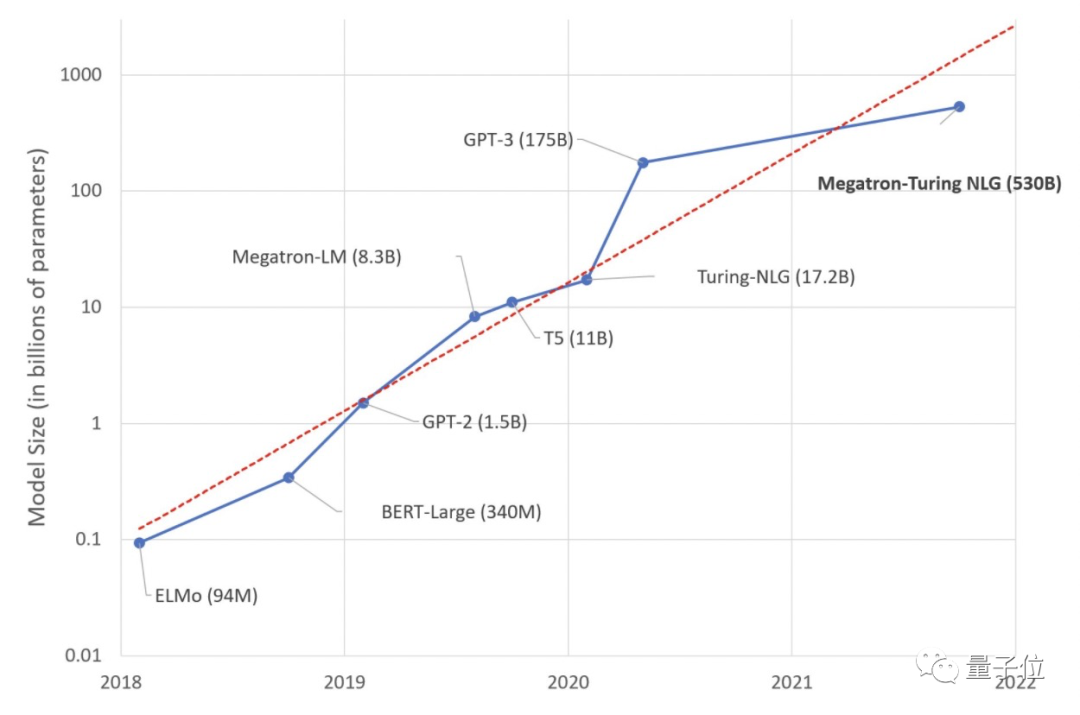
據(jù)他們介紹,這樣的量級不僅讓它成為全球規(guī)模最大,同時也是性能最強的NLP模型。
訓練過程一共使用了4480塊英偉達A100 GPU,最終使該模型在一系列自然語言任務(wù)中——包括文本預測、閱讀理解、常識推理、自然語言推理、詞義消歧——都獲得了前所未有的準確率。
三倍規(guī)模于GPT-3
此模型簡稱MT-NLG,是微軟Turing NLG和英偉達Megatron-LM兩者的“繼任者”。
Turing NLG由微軟于2020年2月推出,參數(shù)為170億;Megatron-LM來自英偉達,2019年8月推出,參數(shù)83億。
它倆在當時分別是第一、二大規(guī)模的Transfomer架構(gòu)模型。
我們都知道大參數(shù)規(guī)模的語言模型效果會更好,但訓練起來也很有挑戰(zhàn)性,比如:
- 即使是最大容量的GPU,也存不下如此規(guī)模的參數(shù);
- 如果不特別注意優(yōu)化算法、軟件和硬件堆棧,那么所需的大量計算操作可能會導致訓練時間過長。
那這個參數(shù)已是GPT-3三倍的MT-NLG又是如何解決的呢?
答案就是汲取“兩家”所長,融合英偉達最先進的GPU加速訓練設(shè)備,以及微軟最先進的分布式學習系統(tǒng),來提高訓練速度。

并用上千億個token構(gòu)建語料庫,共同開發(fā)訓練方法來優(yōu)化效率和穩(wěn)定性。
具體來說,通過借鑒英偉達Megatron-LM模型的GPU并行處理,以及微軟開源的分布式訓練框架DeepSpeed,創(chuàng)建3D并行系統(tǒng)。
對于本文中這個5300億個參數(shù)的模型,每個模型副本跨越280個NVIDIA A100 GPU,節(jié)點內(nèi)采用Megatron-LM的8路張量切片(tensor-slicing),節(jié)點間采用35路管道并行(pipeline parallelism)。
然后再使用DeepSpeed的數(shù)據(jù)并行性進一步擴展到數(shù)千個GPU。
最終在基于NVIDIA DGX SuperPOD的Selene超級計算機上完成混合精度訓練。
(該超級計算機由560個DGX A100服務(wù)器提供支持,每個DGX A100有8個 NVIDIA A100 80GB Tensor Core GPU,通過NVLink 和 NVSwitch相互完全連接)。
該模型使用了Transformer解碼器的架構(gòu),層數(shù)、hidden dimension和attention head分別為 105、20480和128。
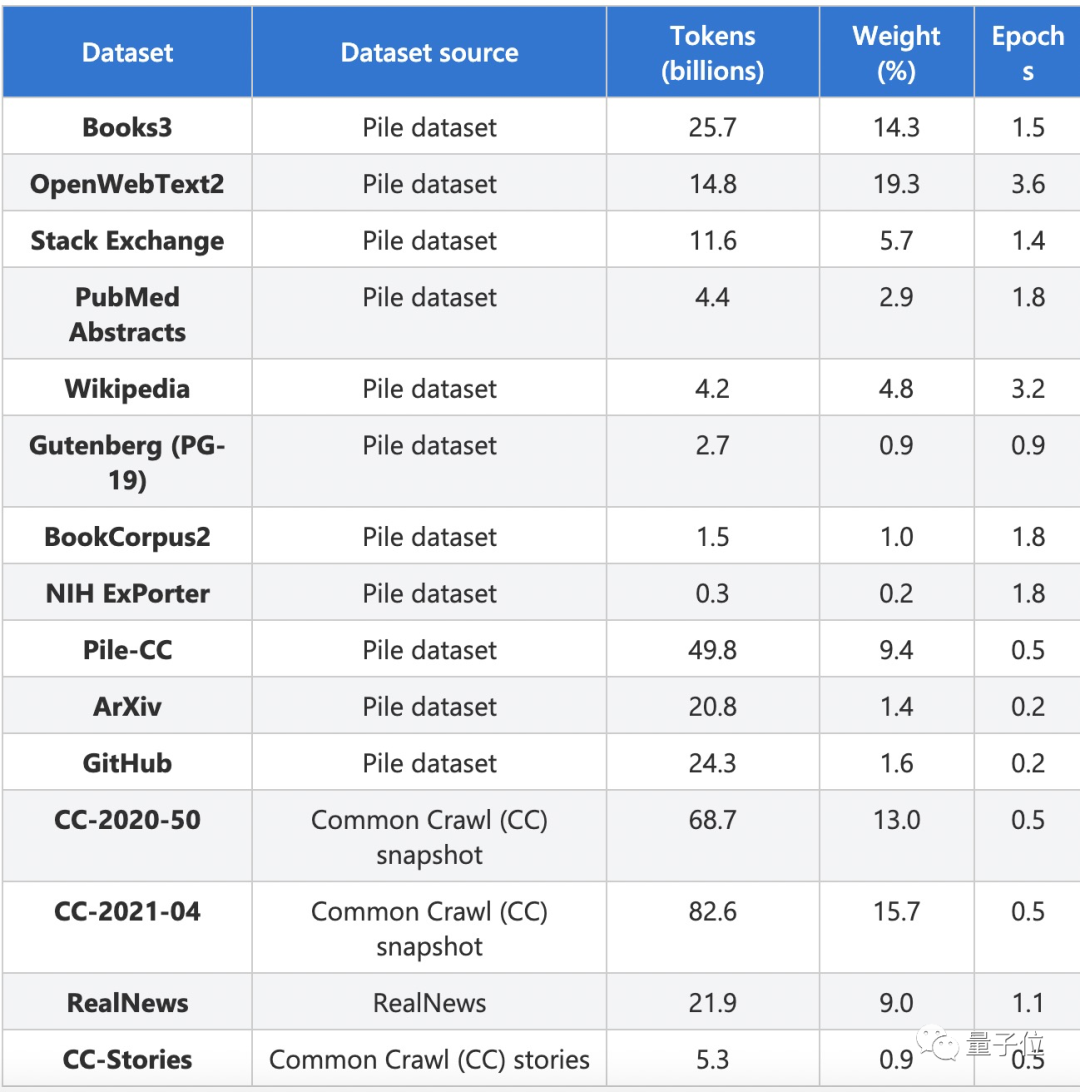
訓練所用數(shù)據(jù)集包括近20萬本書的純文本數(shù)據(jù)集Books3、問答網(wǎng)站Stack Exchange、維基百科、學術(shù)資源網(wǎng)站PubMed Abstracts、ArXiv、維基百科、GitHub等等,這些都是從他們先前搭建的Pile數(shù)據(jù)集中挑出的質(zhì)量較高的子集。
最終一共提取了2700億個token。
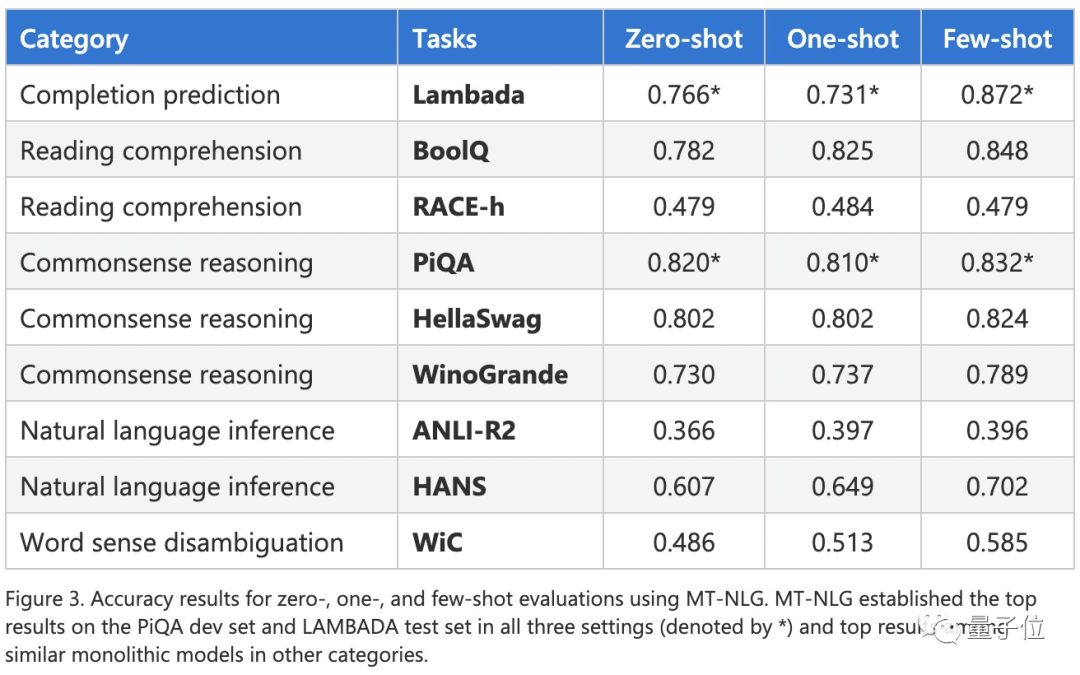
五大任務(wù)上的準確度測試
開發(fā)者在以下5大任務(wù)上對MT-NLG進行了準確度測試。
- 在文本預測任務(wù)LAMBADA中,該模型需預測給定段落的最后一個詞。
- 在閱讀理解任務(wù)RACE-h和BoolQ中,模型需根據(jù)給定的段落生成問題的答案。
- 在常識推理任務(wù)PiQA、HellaSwag和Winogrande中,每個任務(wù)都需要該模型具有一定程度的常識了解。
- 對于自然語言推理,兩個硬基準,ANLI-R2和HANS考驗先前模型的典型失敗案例。
- 詞義消歧任務(wù)WiC需該模型從上下文對多義詞進行理解。
結(jié)果該模型在PiQA開發(fā)集和LAMBADA測試集上的零樣本、單樣本和少樣本三種設(shè)置中都獲得了最高的成績。
在其他各項任務(wù)上也獲得了最佳。
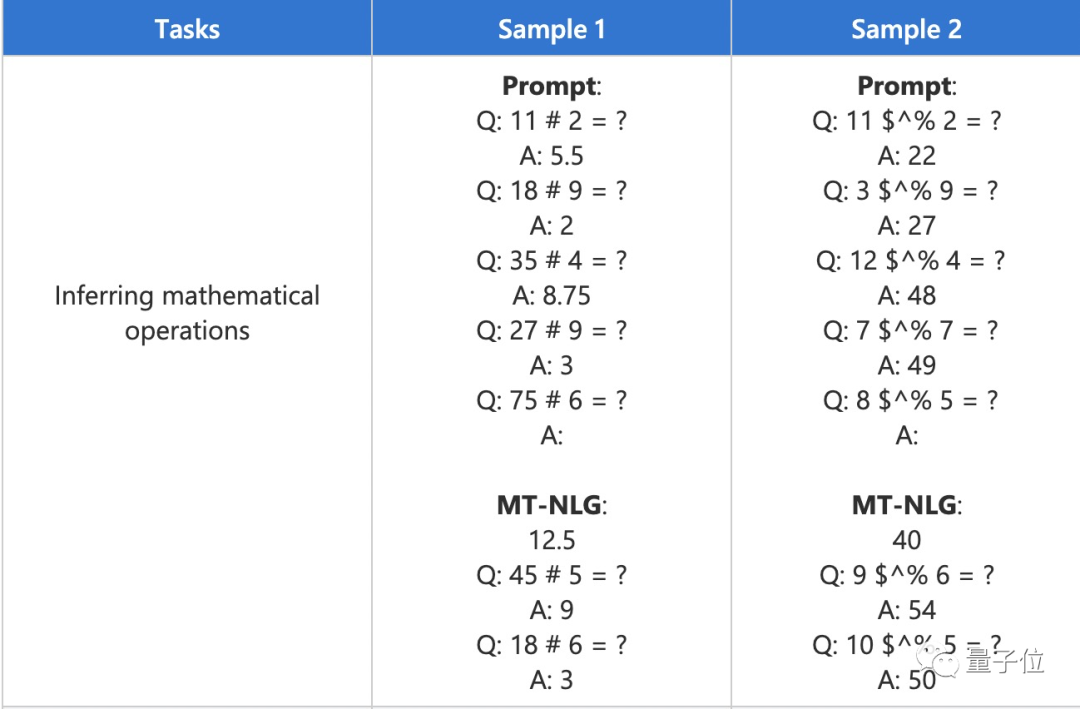
除了報告基準任務(wù)的匯總指標外,他們還對模型輸出進行了定性分析,并觀察到,即使符號被嚴重混淆,該模型也可以從上下文中推斷出基本的數(shù)學運算。
當然,該模型也從數(shù)據(jù)中也提取出了刻板印象和偏見。微軟和英偉達表示也在解決這個問題。
另外,他們表示在生產(chǎn)場景中使用MT-NLG都必須遵守微軟的“負責任的AI原則”來減少輸出內(nèi)容的負面影響,但目前該模型還未公開。






























