語言模型不務(wù)正業(yè)做起目標(biāo)檢測,性能比DETR更好
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
長期以來,CNN都是解決目標(biāo)檢測任務(wù)的經(jīng)典方法。
就算是引入了Transformer的DETR,也是結(jié)合CNN來預(yù)測最終的檢測結(jié)果的。
但現(xiàn)在,Geoffrey Hinton帶領(lǐng)谷歌大腦團隊提出的新框架Pix2Seq,可以完全用語言建模的方法來完成目標(biāo)檢測。

團隊由圖像像素得到一種對目標(biāo)對象的“描述”,并將其作為語言建模任務(wù)的輸入。然后讓模型去學(xué)習(xí)并掌握這種“語言”,從而得到有用的目標(biāo)表示。
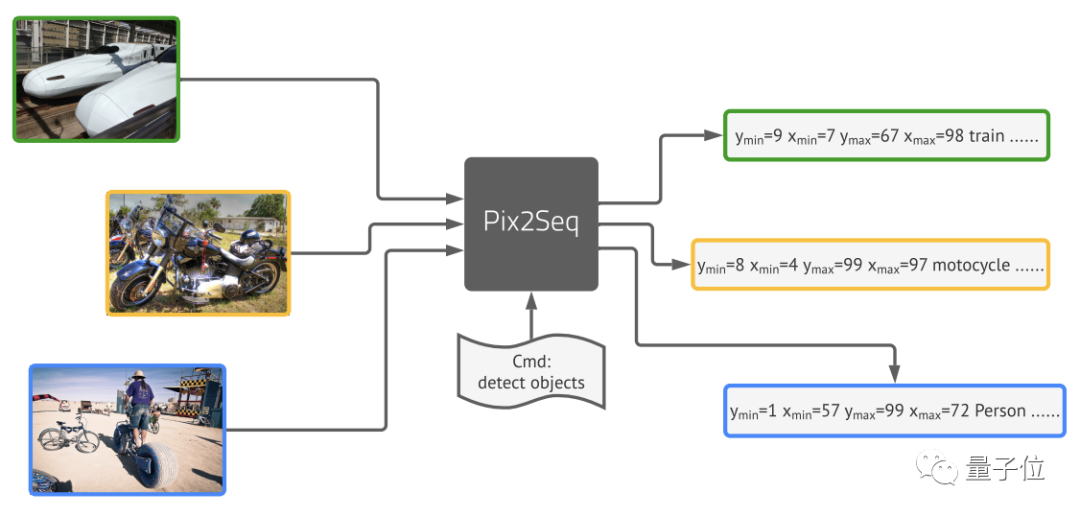
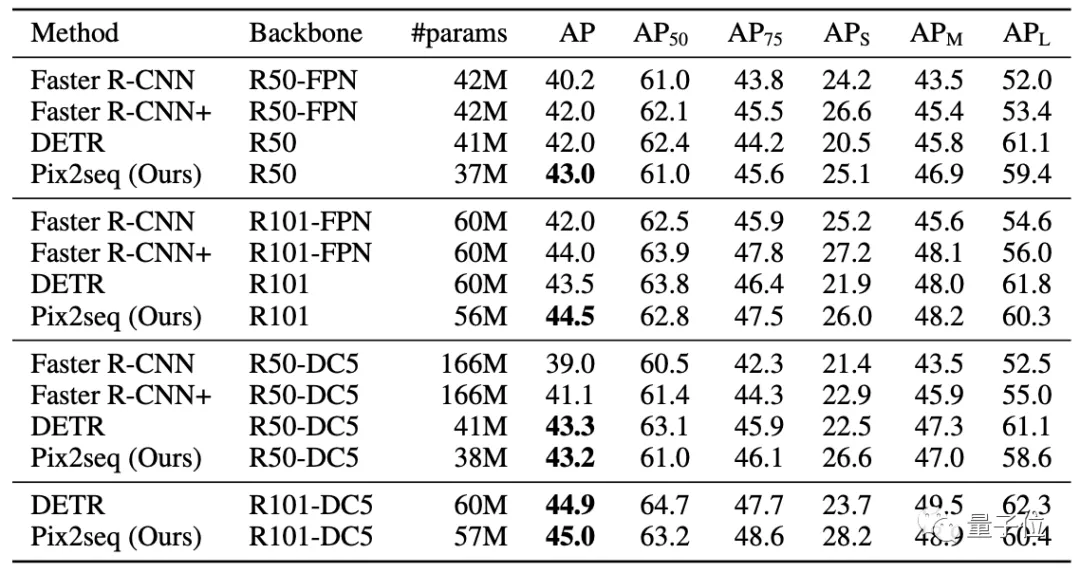
最后取得的結(jié)果基本與Faster R-CNN、DETR相當(dāng),對于小型物體的檢測優(yōu)于DETR,在大型物體檢測上的表現(xiàn)也比Faster R-CNN更好,。
接下來就來具體看看這一模型的架構(gòu)。
從物體描述中構(gòu)建序列
Pix2Seq的處理流程主要分為四個部分:
- 圖像增強
- 序列的構(gòu)建和增強
- 編碼器-解碼器架構(gòu)
- 目標(biāo)/損失函數(shù)
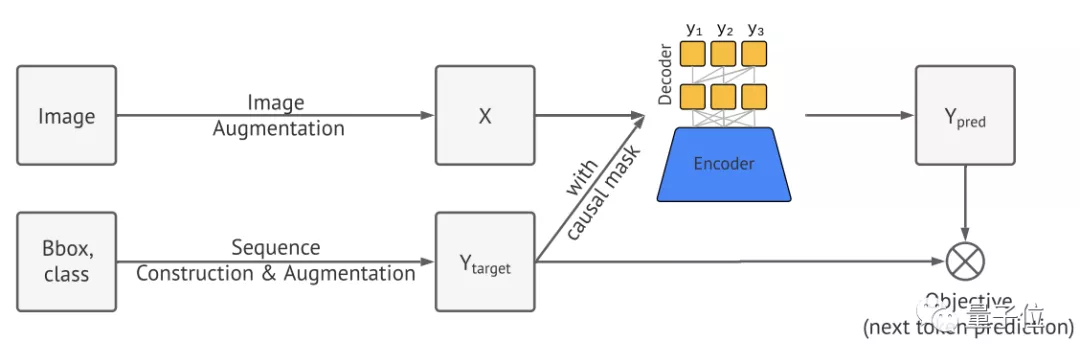
首先,Pix2Seq使用圖像增強來豐富一組固定的訓(xùn)練實例。
然后是從物體描述中構(gòu)建序列。
一張圖像中常常包含多個對象目標(biāo),每個目標(biāo)可以視作邊界框和類別標(biāo)簽的集合。
將這些對象目標(biāo)的邊界框和類別標(biāo)簽表達(dá)為離散序列,并采用隨機排序策略將多個物體排序,最后就能形成一張?zhí)囟▓D像的單一序列。
也就是開頭所提到的對“描述”目標(biāo)對象的特殊語言。
其中,類標(biāo)簽可以自然表達(dá)為離散標(biāo)記。
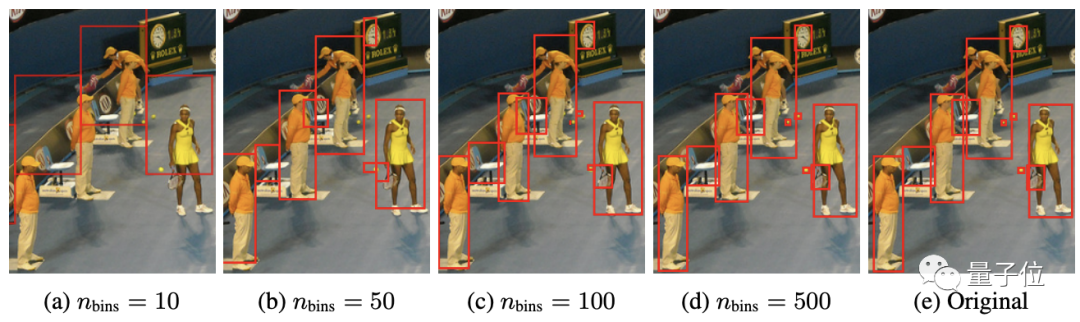
邊界框則是將左上角和右下角的兩個角點的X,Y坐標(biāo),以及類別索引c進(jìn)行連續(xù)數(shù)字離散化,最終得到五個離散Token序列:
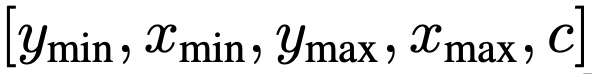
研究團隊對所有目標(biāo)采用共享詞表,這時表大小=bins數(shù)+類別數(shù)。
這種量化機制使得一個600×600的圖像僅需600bins即可達(dá)到零量化誤差,遠(yuǎn)小于32K詞表的語言模型。
接下來,將生成的序列視為一種語言,然后引入語言建模中的通用框架和目標(biāo)函數(shù)。
這里使用編碼器-解碼器架構(gòu),其中編碼器用于感知像素并將其編碼為隱藏表征的一般圖像,生成則使用Transformer解碼器。
和語言建模類似,Pix2Seq將用于預(yù)測并給定圖像與之前的Token,以及最大化似然損失。
在推理階段,再從模型中進(jìn)行Token采樣。
為了防止模型在沒有預(yù)測到所有物體時就已經(jīng)結(jié)束,同時平衡精確性(AP)與召回率(AR),團隊引入了一種序列增強技術(shù):
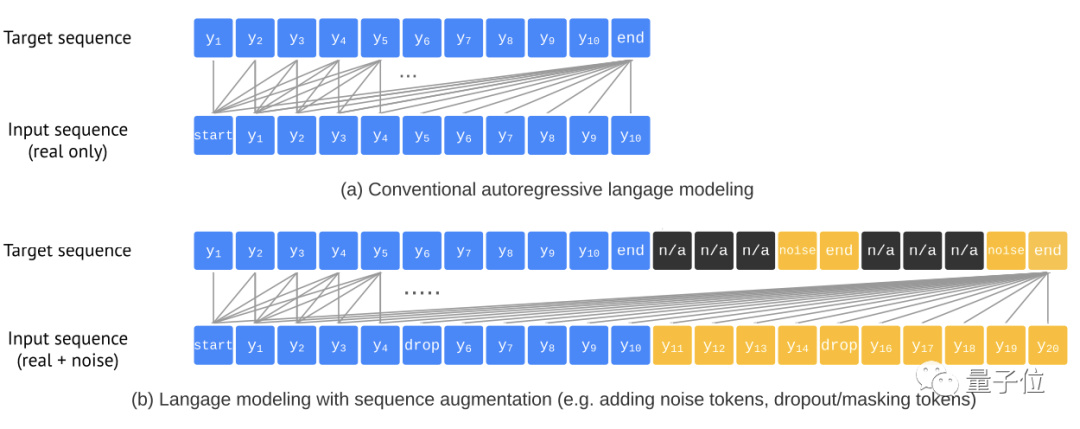
這種方法能夠?qū)斎胄蛄羞M(jìn)行增廣,同時還對目標(biāo)序列進(jìn)行修改使其能辨別噪聲Token,有效提升了模型的魯棒性。
在小目標(biāo)檢測上優(yōu)于DETR
團隊選用MS-COCO 2017檢測數(shù)據(jù)集進(jìn)行評估,這一數(shù)據(jù)集中含有包含11.8萬訓(xùn)練圖像和5千驗證圖像。
與DETR、Faster R-CNN等知名目標(biāo)檢測框架對比可以看到:
Pix2Seq在小/中目標(biāo)檢測方面與Faster R-CNN性能相當(dāng),但在大目標(biāo)檢測方面更優(yōu)。
而對比DETR,Pix2Seq在大/中目標(biāo)檢測方面相當(dāng)或稍差,但在小目標(biāo)檢測方面更優(yōu)。
一作華人
這篇論文來自圖靈獎得主Geoffrey Hinton帶領(lǐng)的谷歌大腦團隊。
一作Ting Chen為華人,本科畢業(yè)于北京郵電大學(xué),2019年獲加州大學(xué)洛杉磯分校(UCLA)的計算機科學(xué)博士學(xué)位。
他已在谷歌大腦團隊工作兩年,目前的主要研究方向是自監(jiān)督表征學(xué)習(xí)、有效的離散結(jié)構(gòu)深層神經(jīng)網(wǎng)絡(luò)和生成建模。
論文:
https://arxiv.org/abs/2109.10852