中國的“Databricks”們:打造AI基礎架構,我們是認真的
AI落地最大的驅動因素是基礎架構的升級。
近年來,大數據分析、AI等領域一直備受關注,常有引人關注的融資事件發生。美國數據科學公司Databricks剛剛在今年8月底完成了16億美元H輪融資,其最新估值高達380億美元,相比7個月前G輪融資時280億美元的估值,又輕松增加了100億美元。
Databricks“紅了”,連帶著“深巷里的美酒”——數據科學也得到了更多關注。雖然數據科學是一門復雜的學科,但如今已進入金融、工業乃至千行百業,這一過程其實也是AI從“可用”到“好用”的一個縮影。
“AI落地的關鍵,是其價值的彰顯,以及尋找到適合的商業落地途徑。”九章云極DataCanvas董事長方磊指出,“以前,人們認為算法可能是壁壘。但隨著技術的快速迭代、開源開放,事實證明算法并非高不可攀,AI落地最大的驅動因素是基礎架構的升級。”
AI基礎架構升級刻不容緩
當前,中國正處于企業數智化轉型的時代拐點。回顧信息化發展的歷程可以發現,1980年-2000年,這是基礎信息化時代,服務器、存儲、操作系統、數據庫等基礎設施軟硬件快速發展;2000年-2020年,進入到流程數字化時代,云計算開始大行其道,云成為基礎設施,各類SaaS應用百花齊放;2020年以后,市場邁入新的階段,其標志是“決策智能化”,相關領域包括數據科學平臺、云原生數據倉庫、開源技術等迎來爆發的機會。
決策智能化的實現,需要一個“智能化的底座”,也就是常說的AI基礎架構。通過AI基礎架構的不斷完善和升級,AI應用落地的效率會更高,也更容易。“AI基礎架構的價值就在于,它能夠讓企業在其上自主地開發AI應用。”方磊概括道。
AI落地的探索源于算法的創新,之后涌現出的一批AI企業,致力于為客戶提供定制化的端到端的AI應用開發。這在無形中造成了AI落地的高門檻。隨著各行各業對智能化的需求愈發迫切,AI已經成了眾多行業頭部客戶的剛需。但是這些頭部客戶不僅業務規模龐大,而且十分復雜,其需求也各不相同。如果仍然沿用過去那種“千人千面”的定制化端到端應用開發模式,很難快速滿足這些頭部客戶的業務需求,而且AI應用的門檻依然高高在上,客戶始終掌握不了主動權。
“從各行業頭部客戶的需求來看,他們更希望圍繞自身的業務開發自己的AI應用,這就需要一個自主可控的基礎設施。”方磊表示,“依托AI基礎架構,由企業自主開發AI應用,鍛煉并形成自主的AI能力,這才是市場主流,也是AI應用落地的內驅力。”
Databricks之所以受到市場追捧,正是因為它以最擅長的流數據處理為出發點,向上發展機器學習、建模,向下打造數據湖倉一體,不斷擴展和完善AI基礎架構,為最上層的AI應用提供一個優化的承載平臺,即AI Foundation。
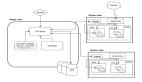
來源:Databricks
實際上,目前內業對于AI基礎架構還沒有一個統一而明確的定義。但從應用實踐,以及像Databricks這樣的標桿企業的做法來看,AI基礎架構至少包含兩大基石,即“數據”與“算法”。
以前,大多數的應用都是離線的,比如獲得一份營銷名單。但是現在,客戶對在線應用的需求越來越迫切,很多時候一個模型已經建好,卻發現數據“供不應求”。由此可見,AI應用離不開一個實時的數據底座,AI基礎架構的重要性在此時得以凸顯。4年前,九章云極DataCanvas就開始打造支持高并發的實時數倉,如今經過品牌升級,一個功能和性能都更加完善的HSAP(Hybrid Serving/Analytical Processing)實時數倉產品DingoDB呈現出來。這就是九章云極DataCanvas眼中,AI應用不可或缺的數據底座。
談到AI基礎架構的門檻,方磊表示:“算法是技術上的門檻,但我們已經實現了突破。我們的自動機器學習產品,在性能等指標上已經不遜于國外同類產品,甚至更強。其實,更高的門檻還是在客戶,或者說應用層面。當前,自建AI基礎架構的需求主要集中在各行業的頭部客戶身上。作為AI廠商,必須有意愿和能力服務好這些頭部客戶。我們公司從2014年就開始專注并深耕這一領域。”
九章云極DataCanvas、Databricks像?不像?
從市場大勢來看,正是決策智能化時代的到來,才使得像Snowflake、Databricks這樣以數據為驅動,以創新的AI基礎架構支撐AI、大數據應用落地的企業成了資本市場的寵兒。
就在Databricks成立的2013年,同樣崇尚數據科學的九章云極DataCanvas也在中國順勢而起。盡管地處不同,但兩者卻有不少相似之處,尤其在能力建設和商業模式愿景上,九章云極DataCanvas和Databricks更頗有幾分默契,這是巧合?還是殊途同歸?
首先,兩家公司的定位相似,都是數據科學的研發者、應用者和推動者,并且都在主攻AI基礎架構升級的方向。但是由于出發點不同、所擅長的細分技術領域不同,Databricks最早以流數據處理成名,而九章云極DataCanvas則以開源自動機器學習見長,因此在具體構建AI基礎架構時,兩者選擇的路徑有所差異。
其次,從產品線來看,雖然在細節上略有差異,但從整體能力建設上看,兩家公司的產品可以說是如出一轍,都涵蓋了分析和數據兩大部分。在分析部分,九章云極DataCanvas享有業內頗受好評的開源架構機器學習平臺DataCanvas APS,該平臺囊括了算子倉庫、模型訓練、數據處理、自動機器學習等,再配合數據層面的DingoDB實時數倉,構建出數據實時計算分析閉環。而Databricks除了眾所周知的Spark以外,還有同樣知名的數據湖倉一體Delta Lake,以及機器學習、數據測試與管理、數據解釋和建模產品等。兩家公司通過持續不斷的創新,致力于讓AI基礎架構變得更加“厚實而飽滿”,可謂異曲同工。
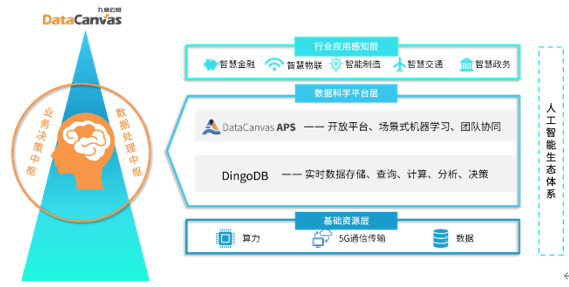
來源:九章云極DataCanvas
“在數據科學這一領域,我們與Databricks擁有相似的愿景、目標和戰略,想做同樣的事,即打造AI基礎架構,將算力和網絡充分利用起來。”方磊表示,“對于有人將我們稱作‘中國的Databricks’,我們感到非常榮幸。這是對我們的一種認可。但我們也清醒地認識到,AI基礎架構市場空間巨大,還有很多‘細致的活兒’要做。這也是我們繼續快速前進的動力。”
把AI嵌入到云里去
任何一個想有一番作為的企業,肯定都不會滿足于“成為別人”,九章云極DataCanvas也是如此,成為“中國的Databricks”不是終點,“做自己”成為一個獨特的存在才是最終目標。
實際上,因為中美兩國大到市場和競爭環境,小到企業的AI應用需求,都存在差異。在兩塊不同的土地上長出的苗,可能屬于同一種類,但在個體上會有顯著的差別。試舉一例,在美國市場,一直是AWS、Azure、Google Cloud“三朵云”打天下。無論是Snowflake還是Databricks,都生長在這“三朵云”之上。但在中國,云計算市場大相徑庭,云的碎片化現象顯而易見,不同的區域、不同的行業可能造就了上千朵云。雖然從AI應用落地的角度,中美客戶的需求沒有差別,但是在具體的路徑選擇和落地方式上,還是有各自的傾向和習慣。
方磊坦言,九章云極DataCanvas現階段將主要圍繞各行業的頭部客戶群體,為其打造AI基礎架構。因為這部分客戶的需求最迫切,并且有資金也有技術能力實現AI的自主開發。基于對中國未來AI行業生態發展的預判,九章云極DataCanvas建設性地提出了“云中云”戰略(An AI Cloud in the Clouds),即將AI基礎架構及相關AI能力,嵌入到形形色色的行業云、區域云、企業云、聯盟云等千朵云中。為了滿足不同云生態的需求,九章云極DataCanvas必須讓自己的解決方案實現更加靈活、高效的交付。而“云中云”顯然是事半功倍的做法,可以很好地借力打力,將九章云極DataCanvas的AI能力隨云輸出。
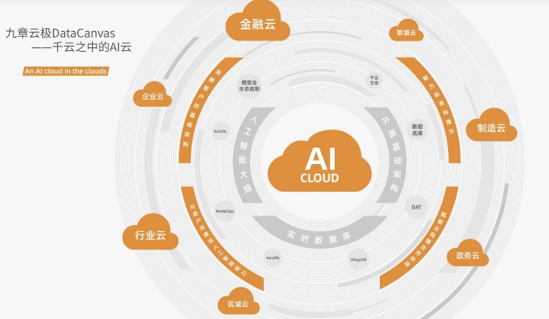
來源:九章云極DataCanvas
對于AI基礎架構,很多行業用戶一開始的認知是模糊的,仍需要持續的教育。但是某些先行先試的行業頭部企業,已經從AI基礎架構的升級中嘗到了甜頭。比如在銀行業,原來需要幾天才能完成審批的貸款,現在可以實時審批;在制造業,工業質量檢測能力的提升、設備預測性維護的實現等都得益于AI的應用……諸如此類的案例應用不勝枚舉。
“在構建AI基礎架構的基礎之上,有數據、有場景、有預算、有團隊,用戶就可以開發自己的AI應用了。”方磊表示,“原來,用戶習慣‘伸手’向廠商要‘交鑰匙’的AI解決方案。但這種單獨定制的解決方案并非長久之計。”例如某大型鋼鐵企業在全球擁有300多條產線,每條產線用到的設備、供應商各不相同。如果沒有一個統一的平臺支撐其建模、分析、應用開發和管理,那么系統將不堪重負。說到底,用戶還是要依靠自身AI能力的提高,運用通用的技術,自主掌握AI應用開發。在這種情況下,AI基礎架構就是必須的。這也是九章云極DataCanvas的商業機會。
珠玉在前 事半功倍
打造千朵云生態的AI基礎架構,是九章云極DataCanvas的商業定位;而打造中國開源數據科學第一平臺,則是九章云極DataCanvas的初心。兩者并不矛盾。正相反,數據科學與AI基礎架構從學科和商業應用兩個不同的維度,在九章云極DataCanvas身上實現了平衡與統一。
在很長時間里,數據科學曲高和寡。在中國,像九章云極DataCanvas這樣長期堅持深耕數據科學領域的廠商鳳毛麟角。Databricks可以說是全球范圍內數據科學領域最先跑出的企業。它居高不下的熱度至少證明了,數據科學這個市場大有可為。
新基建、云原生、數智化升級、開源,在這些利好因素下,再加上有Databricks這樣的珠玉在前,以及九章云極DataCanvas等公司多年來的精耕細作,數據科學的未來值得期待。