













有了“大數(shù)據(jù)”,還需“多任務”,谷歌AI大牛Quoc V. Le發(fā)現(xiàn)大模型零樣本學習能力的關鍵
本文轉(zhuǎn)自雷鋒網(wǎng),如需轉(zhuǎn)載請至雷鋒網(wǎng)官網(wǎng)申請授權(quán)。
谷歌研究科學家Quoc V. Le近期提出了一個1370億參數(shù)語言模型FLAN,探討了一種提高語言模型zero-shot學習能力的新方法。
研究表明,指令微調(diào)(instruction tuning)——在通過指令描述的任務集合上對語言模型進行微調(diào),可以極大地提高未見過的任務的零樣本場景下的性能

論文鏈接:https://arxiv.org/pdf/2109.01652v1.pdf
我們采用一個1370億參數(shù)量的預訓練語言模型,通過自然語言指令模板對60多個NLP任務進行指令微調(diào)。我們把這個模型稱為Finetuned LAnguage Net(FLAN),研究人員在未見過的任務類型上對這個指令微調(diào)過的模型進行了評估。
結(jié)果表明,F(xiàn)LAN極大地提高了其未調(diào)整的對應模型的性能,并且在我們評估的25個任務中,有19個任務超過了零樣本設定下參數(shù)為1750億的GPT-3。
在ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA和StoryCloze上,F(xiàn)LAN甚至以很大的優(yōu)勢超過了小樣本GPT-3。消融研究顯示,任務數(shù)量和模型規(guī)模是指令微調(diào)成功的關鍵因素。
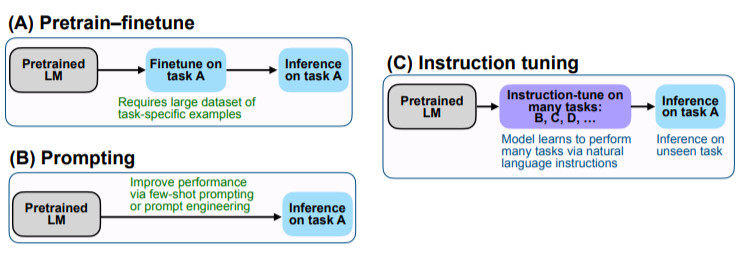
圖1:上面:指令微調(diào)和FLAN概述。指令微調(diào)是在以指令描述的任務集合上對預訓練的語言模型進行微調(diào)。在推理中,我們對一個未見過的任務類型進行評估;例如,如果在指令微調(diào)期間沒有學習過自然語言推理(NLI)任務,我們可以用NLI任務對模型進行評估。下面:與零樣本 GPT-3 和小樣本GPT-3相比,零樣本FLAN在未見過的任務類型上的表現(xiàn)。
1
引言
規(guī)模化的語言模型(LM),如GPT-3,已經(jīng)被證明可以很好地進行few-shot學習。然而,它們在zero-shot學習方面卻不是很成功。例如,在閱讀理解、回答問題和自然語言推理等任務上,GPT-3在零樣本場景下的學習性能比小樣本差很多。其中一個潛在原因是:如果沒有小樣本的示范,那么在與預訓練數(shù)據(jù)的格式不同的指示上,模型就很難取得良好的表現(xiàn)。
本文中,我們探索了一種簡單的方法來提高大型語言模型的零樣本性能。我們利用了NLP任務可以通過自然語言指令來描述的直覺,比如 "這個電影評論是正面情緒的還是負面的?"或者 "把'你好嗎'翻譯成中文"。
我們采用了一個參數(shù)為1370億的預訓練語言模型,并對該模型進行指令微調(diào)——對60多個通過自然語言指令表達的NLP任務的集合進行微調(diào)。我們把這個模型稱為Finetuned LAnguage Net(FLAN)。
為了評估FLAN在未見過的任務上的零樣本性能,我們將NLP任務根據(jù)其任務類型分為幾個群組,并對某個群組進行評估之前,在所有其他群組上對FLAN進行指令微調(diào)。
例如,如圖1所示,為了評估FLAN執(zhí)行自然語言推理的能力,我們先在一系列其他NLP任務上對模型進行指令微調(diào),如常識推理、翻譯和情感分析。由于這種設置確保了FLAN在指令微調(diào)中沒有學習過任何自然語言推理任務,因此我們可以再評估其進行零樣本自然語言推理的能力。
評估表明,F(xiàn)LAN極大地提高了基礎1370億參數(shù)模型在零樣本場景下的性能。在我們評估的25個任務中的19個任務里,零樣本場景下的FLAN也優(yōu)于參數(shù)為1750億參數(shù)的GPT-3,甚至在一些任務上,如ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA和StoryCloze,也明顯優(yōu)于小樣本GPT-3。在消融實驗中,我們發(fā)現(xiàn)在指令微調(diào)中增加任務群的數(shù)量可以提高未學習任務的性能,而且只有在有足夠的模型規(guī)模時,指令微調(diào)的優(yōu)點才會顯現(xiàn)。
我們的實證結(jié)果強調(diào)了語言模型執(zhí)行用自然語言指令描述的任務的能力。更為廣泛的結(jié)論是,如圖2所示,通過微調(diào)的方式進行監(jiān)督,來提高語言模型對推理-時間文本交互的反應能力,指令微調(diào)結(jié)合了預訓練調(diào)整和prompting范式中吸引人的特點。
用于加載FLAN的指令微調(diào)數(shù)據(jù)集的源代碼:https://github.com/google-research/flan
圖2:比較指令微調(diào)與預訓練-調(diào)整和prompting的關系。
2
指令微調(diào)提高了零樣本學習的效果
進行指令微調(diào)是為了提高語言模型對NLP指令的反應能力。我們想通過監(jiān)督來指引語言模型執(zhí)行指令描述的任務,使其學會遵循指令,對與未見過的任務也是如此。為了評估模型在未見過的任務上的表現(xiàn),我們按任務類型將任務進行分組,并將每個任務組單獨進行評估,同時對其余所有分組進行指令微調(diào)。
2.1 任務&模板
從零創(chuàng)建一個具有大量任務的可行的指令調(diào)整數(shù)據(jù)集需要集中大量資源。因此,我們選擇將現(xiàn)有研究創(chuàng)建的數(shù)據(jù)集轉(zhuǎn)化為指令格式。我們將Tensorflow數(shù)據(jù)集上公開的62個文本數(shù)據(jù)集,包括語言理解和語言生成任務,匯總成一個集合。圖3展示了我們使用的所有數(shù)據(jù)集;每個數(shù)據(jù)集都被歸入十二個任務群組中的一個,每個群組中的數(shù)據(jù)集都屬于同一任務類型。
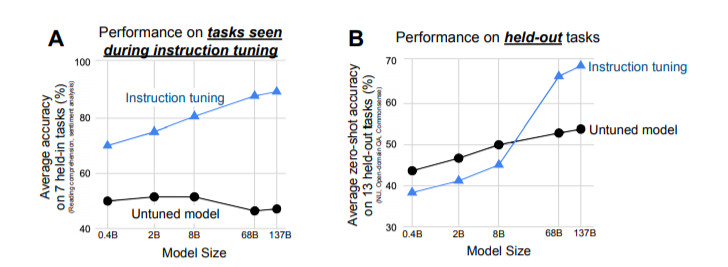
圖3:本文中使用的任務集群(藍色為NLU任務;茶色為NLG任務)。
我們將任務設定為由基于數(shù)據(jù)集轉(zhuǎn)換的一組特定的輸入-輸出對(例如,我們認為RTE和ANLI是獨立的任務,盡管它們的涵義有交叉)。
對于每一項任務,我們都會把它們組成十個不同的用自然語言指令來描述任務的模板。這十個模板中的大部分都描述了原始任務,但為了增加多樣性,每個任務中最多包含三個 "反轉(zhuǎn)任務 "的模板(例如,對于情感分類,我們包括要求生成負面電影評論的模板)。
然后,我們在所有任務的集合上對預訓練的語言模型進行指令微調(diào),每個任務中的例子都通過隨機選擇的指令模板進行格式化。圖4展示了一個自然語言推理任務的多個指令模板。
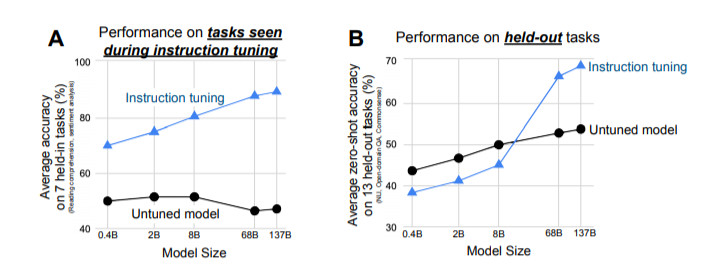
圖4:描述一個自然語言推理任務的多個指令模板。
2.2 評估分割法
我們對FLAN在指令微調(diào)中沒有訓練過的任務上的表現(xiàn)很感興趣,因此,對未見過的任務的定義至關重要。
之前的一些工作通過不允許同一數(shù)據(jù)集出現(xiàn)在訓練中來對未見過的任務進行分類,而我們利用圖3中的任務集群,使用一個更為保守的定義。
在這項工作中,如果在指令微調(diào)期間沒有訓練過T所屬的任何集群的任務,我們才認為任務T在評估時是合適的。例如,如果任務T是一個文本蘊涵任務,那么在指令微調(diào)數(shù)據(jù)集中不會出現(xiàn)文本蘊涵任務,我們只對所有其他集群的任務進行指令調(diào)整。
使用這個定義,為了評估FLAN在跨越c個集群的任務上的性能,我們執(zhí)行了c個集群間分割的指令微調(diào),在指令微調(diào)過程中,每種分割都會有不同的集群。
2.3 有選擇的分類
一個給定任務所期望的輸出空間是幾個給定類別中的一個(如分類)或自由文本(如生成)。由于FLAN是純解碼器語言模型的指令微調(diào)版本,它自然可以生成自由文本,因此對于期望輸出為自由文本的任務不需要再做進一步修改。
對于分類任務,先前Brown等人的工作使用了等級分類方法,例如,只考慮兩個輸出("是 "和 "不是"),將概率較高的一個作為模型的預測。
雖然這個程序在邏輯上是合理的,但它并不完美,因為答案的概率質(zhì)量可能有一個不理想的分布(例如,大量替代性的 "是 "的表達方式,比如“對”、“正確”,可能降低分配給 "是 "的概率質(zhì)量)。
因此,我們加入了一個選項后綴,即在分類任務的末尾加上OPTIONS標記,以及該任務的輸出類別列表。這使得模型知道在響應分類任務時需要哪些選擇。圖1中的NLI和常識性的例子顯示了選項的使用。
2.4 訓練細節(jié)
模型架構(gòu)和預訓練。在我們的實驗中,我們使用了一個密集的從左到右的、只有解碼器的1370億參數(shù)的Transformer語言模型。這個模型在網(wǎng)絡文檔(包括那些帶有計算機代碼的文檔)、對話數(shù)據(jù)和維基百科上進行了預訓練,使用SentencePiece庫(Kudo & Richardson, 2018)將其標記為2.81T BPE tokens,詞匯量為32K tokens。大約10%的預訓練數(shù)據(jù)是非英語的。這個數(shù)據(jù)集不像GPT-3的訓練集那樣單一,也有對話和代碼的混合物,因此我們預計一開始這個預訓練的語言模型在NLP任務上的零樣本和小樣本性能會略低。因此,我們把這個預訓練的模型稱為基礎語言模型(Base LM)。這個模型以前也曾被用于程序合成。
指令微調(diào)程序。FLAN是Base LM的指令微調(diào)版本。我們的指令微調(diào)管道混合了所有的數(shù)據(jù)集,并從每個數(shù)據(jù)集中隨機抽取例子。一些數(shù)據(jù)集有超過1000萬個訓練實例(例如翻譯),因此我們將每個數(shù)據(jù)集的訓練實例數(shù)量限制在3萬個。其他數(shù)據(jù)集的訓練例子很少,為了防止這些數(shù)據(jù)集被邊緣化,我們遵循實例-比例混合方案(examples-proportional mixing scheme),混合率最大為3000。我們的微調(diào)程序中使用的輸入和目標序列長度分別為1024和256。我們使用打包的方法將多個訓練實例合并成一個序列,并用一個特殊的序列末端標記將輸入和目標分開。
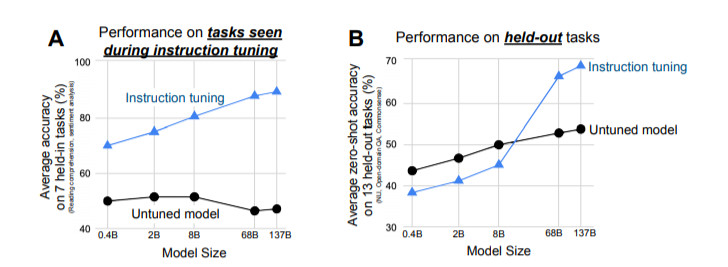
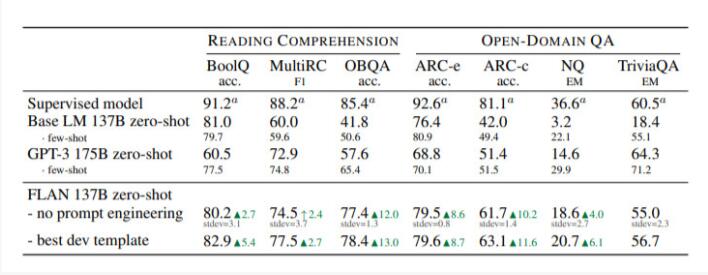
表2: 閱讀理解和開放領域問題回答的結(jié)果。
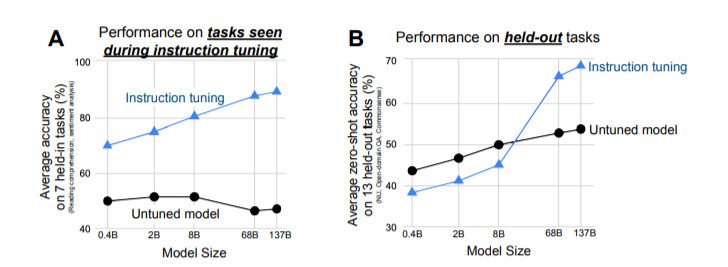
表3: 常識推理和核心推理的結(jié)果(準確率單位為%)。
表4:WMT'14 En/Fr、WMT'16 En/De和En/Ro的翻譯結(jié)果(BLEU)。
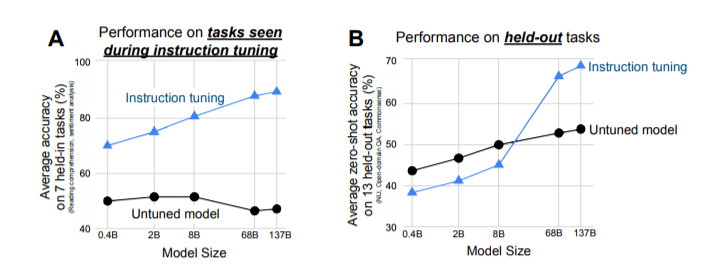
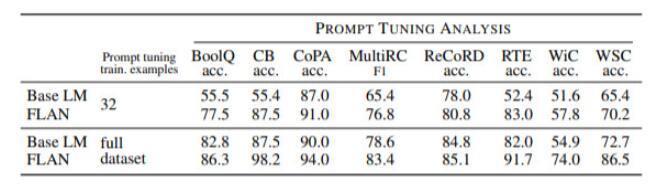
表5:FLAN對通過指令微調(diào)獲得的連續(xù)輸入的反應比Base LM更好。
3
討論
本文探討了零樣本場景下一個簡單的問題:指令微調(diào)語言模型是否能提高其執(zhí)行未見任務的能力?我們在FLAN上的實驗表明,指令微調(diào)提高了對未微調(diào)模型的性能,并在我們評估的大多數(shù)任務上超過了零樣本場景下的GPT-3。通過消融研究,我們了解到,未見任務的性能隨著指令調(diào)諧中使用的任務集群的數(shù)量的增加而提高,而且有趣的是,指令微調(diào)的優(yōu)點只有在模型規(guī)模足夠大時才會出現(xiàn)。此外,F(xiàn)LAN似乎比未修改的基礎模型對指令微調(diào)的反應更好,顯示了指令微調(diào)的另一優(yōu)點。
我們研究中的一個局限是:對任務分組時存在一定程度的主觀性(例如,情感分析可以被看作是閱讀理解的一個小子集),因為沒有公認的方法來處理兩個任務之間的相似性。因此,我們根據(jù)文獻中公認的分類方法將任務分配到群組中,當任務可能屬于多個群組時,我們采取了保守的方法(例如,在評估閱讀理解和常識推理時,將閱讀理解與常識推理排除在指令微調(diào)之外)。作為另一個限制,我們使用簡短的指令(通常是一句話)來描述熟知的NLP任務。其他任務可能需要更長或更具體的指令來充分描述,同時還要有涉及實例的解釋;我們把這些情況留給未來的研究工作。
本文顯示的結(jié)果為未來的研究提出了幾個方向。盡管FLAN在60多個數(shù)據(jù)集上進行了指令微調(diào),但這些數(shù)據(jù)集只覆蓋了10個任務群(加上一些雜項任務),考慮到這樣一個模型可以用于所有潛在的任務,因此這個數(shù)字相對較小。有可能通過更多的指令微調(diào)任務來進一步提高性能,例如,這些任務可以以自監(jiān)督的方式生成。除了收集更多的任務,探索多語言環(huán)境也很有價值,例如,我們可以提出這樣的疑問:在高資源語言的監(jiān)督數(shù)據(jù)上的指令調(diào)整是否會提高低資源語言的新任務的性能?最后,有監(jiān)督數(shù)據(jù)的指令微調(diào)模型也有可能被用來改善模型在偏見和公平方面的行為。


























