













譯者 | 崔皓
審校 | 重樓
摘要
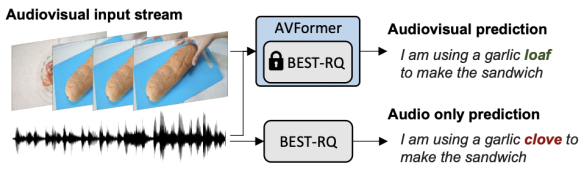
Google Research的研究科學家Arsha Nagrani和Paul Hongsuck Seo介紹了一種名為AVFormer的新技術,該技術將視覺理解能力注入現有的僅音頻ASR模型中,以提高其在各種領域的泛化性能。AVFormer通過使用輕量級的可訓練適配器,將視覺嵌入注入凍結的ASR模型中,這些適配器可以在少量弱標簽視頻數據上進行訓練,額外的訓練時間和參數最少。這種方法實現了零樣本性能,即在未經手動注釋的AV-ASR數據集上進行訓練的情況下,實現了最先進的性能。

【編者:在機器學習和深度學習中,"凍結"一般指的是在訓練過程中保持模型的某些部分或參數不變。這通常是通過禁止反向傳播過程中對這些參數的更新來實現的。"凍結的語音模型"意味著這個語音識別模型在被用于新的視覺任務時,其參數保持不變,不會被進一步訓練或調整。】
開篇
自動語音識別(ASR)是一項成熟的技術,廣泛應用于各種應用,如電話會議、視頻轉錄和語音命令。雖然這項技術的挑戰主要集中在嘈雜的音頻輸入上,但多模態視頻(例如,電視,在線編輯的視頻)中的視覺流可以為提高ASR系統的魯棒性提供強有力的線索,這就是所謂的音頻視覺ASR(AV-ASR)。
【編者:"Zero-shot"是機器學習中的一個術語,通常用于描述一種特殊的訓練和測試情況。在這種情況下,模型在沒有看過任何特定類別的訓練樣本的情況下,被要求識別該類別的實例。這通常通過訓練模型來理解和利用類別之間的某種結構或關系來實現。
例如,如果你有一個模型,它已經學會了識別貓和狗,然后你要求它識別一只兔子,盡管它從未在訓練數據中見過兔子。如果模型能夠正確地識別出兔子,那么我們就說它具有"零樣本/零射擊"的能力。
在這篇文章中,"Zero-Shot"是指模型在未經手動注釋的AV-ASR數據集上進行訓練的情況下,實現了最先進的性能。換句話說,模型能夠處理和理解它在訓練階段從未見過的數據類型或情況。】
盡管唇動可以為語音識別提供強烈的信號,并且是AV-ASR最常關注的區域,但在野外的視頻中,口部往往不直接可見(例如,由于以自我為中心的視點,面部覆蓋物和低分辨率),因此,一個新興的研究領域是無約束的AV-ASR(例如,AVATAR),它研究整個視覺幀的貢獻,而不僅僅是口部區域。
然而,構建用于訓練AV-ASR模型的音頻視覺數據集是具有挑戰性的。如How2和VisSpeech這樣的數據集已經從在線教學視頻中創建,但它們的規模較小。相比之下,模型本身通常很大,包含視覺和音頻編碼器,因此它們傾向于在這些小數據集上過度擬合。盡管如此,最近發布了一些大規模的僅音頻模型,這些模型通過大規模訓練在大量僅音頻數據上進行了大量優化,這些數據來自音頻書籍,如LibriLight和LibriSpeech。這些模型包含數十億個參數,隨時可用,并在各個領域顯示出強大的泛化能力。
考慮到上述挑戰,在“AVFormer:將視覺注入凍結的語音模型,實現零樣本AV-ASR”中,我們提出了一種簡單的方法,用視覺信息增強現有的大規模僅音頻模型,同時進行輕量級的領域適應。AVFormer將視覺嵌入注入凍結的ASR模型(類似于Flamingo如何將視覺信息注入大型語言模型進行視覺-文本任務),使用輕量級可訓練的適配器,這些適配器可以在少量弱標簽視頻數據上進行訓練,額外的訓練時間和參數最少。我們還引入了一個簡單的課程方案,在訓練過程中,我們發現使模型能夠有效地處理音頻和視覺信息至關重要。最終的AVFormer模型在三個不同的AV-ASR基準測試(How2,VisSpeech和Ego4D)上實現了最先進的零樣本性能,同時也保持了在傳統的僅音頻語音識別基準測試(即LibriSpeech)上的良好性能。
使用輕量級模塊注入視覺"
我們的目標是將視覺理解能力添加到現有的僅音頻ASR模型中,同時保持其對各種領域(包括AV和僅音頻領域)的泛化性能。
為了實現這一目標,我們將現有的最先進的ASR模型(Best-RQ)增強了以下兩個組件:(i)線性視覺投影器和(ii)輕量級適配器。前者將視覺特征投影到音頻令牌嵌入空間。這個過程使模型能夠正確地連接單獨預訓練的視覺特征和音頻輸入令牌表示。然后,后者最小化地修改模型,以增加對來自視頻的多模態輸入的理解。然后,我們在HowTo100M數據集的未標記網絡視頻上,以及ASR模型的輸出作為偽真實值,訓練這些額外的模塊,同時保持Best-RQ模型的其余部分凍結。這樣的輕量級模塊使得數據效率和性能的強大泛化成為可能。
我們在零樣本設置中,在AV-ASR基準測試上評估了我們的擴展模型,其中模型從未在手動注釋的AV-ASR數據集上進行過訓練。
為視覺注入設置課程學習
在初步評估之后,我們經驗性地發現,通過一輪簡單的聯合訓練,模型很難一次性學習適配器和視覺投影器。為了解決這個問題,我們引入了一個兩階段的課程學習策略,該策略解耦了這兩個因素——領域適應和視覺特征集成——并以順序的方式訓練網絡。在第一階段,優化適配器參數,完全不需要輸入視覺令牌。一旦適配器被訓練,我們在第二階段添加視覺令牌,并單獨訓練視覺投影層,同時保持訓練過的適配器凍結。
第一階段專注于音頻領域的適應。到了第二階段,適配器完全凍結,視覺投影器只需學習生成視覺提示,將視覺令牌投影到音頻空間。通過這種方式,我們的課程學習策略允許模型同時接納視覺輸入和適應AV-ASR基準測試中的新音頻領域。我們只應用每個階段一次,因為交替階段的迭代應用會導致性能下降。
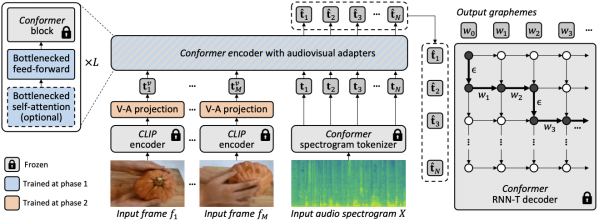
【編者:在第一階段,他們優化了模型的"適配器"參數。適配器是模型的一部分,它的任務是幫助模型適應新的領域或任務。在這個階段,他們并沒有使用任何視覺信息,只是讓模型更好地處理音頻信息。
一旦適配器被訓練好,他們進入了第二階段。在這個階段,他們開始添加視覺信息,并訓練模型的"視覺投影器"部分。視覺投影器的任務是將視覺信息轉換成模型可以理解的形式。在這個階段,他們保持適配器的參數不變,只訓練視覺投影器。
這種分階段的訓練策略允許模型逐步學習如何處理視覺和音頻信息,而不是一次性地學習所有的東西。這樣做的好處是,它可以防止模型在訓練過程中出現性能下降的問題。】
以下的圖表顯示,如果沒有課程學習,我們的AV-ASR模型在所有數據集上都比僅音頻的基線模型差,隨著添加更多的視覺令牌,差距增大。相比之下,當應用了我們提出的兩階段課程時,我們的AV-ASR模型的性能明顯優于基線的僅音頻模型。
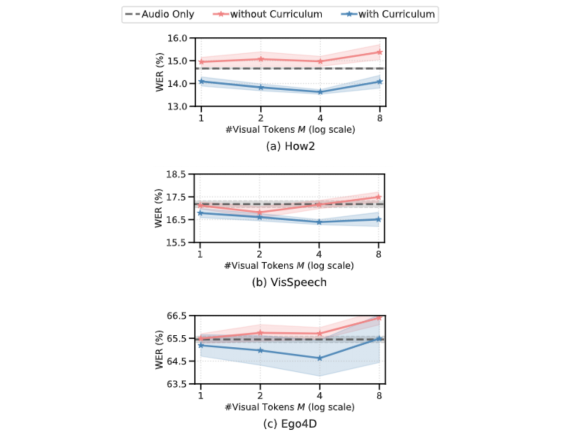
零樣本AV-ASR的結果
我們將AVFormer與BEST-RQ(我們模型的音頻版本)和AVATAR(AV-ASR的最新技術)進行比較,對三個AV-ASR基準測試:How2,VisSpeech和Ego4D的零樣本性能進行比較。AVFormer在所有方面都超過了AVATAR和BEST-RQ,甚至在LibriSpeech和完整的HowTo100M集合上進行訓練時,也超過了AVATAR和BEST-RQ。值得注意的是,對于BEST-RQ而言訓練參數為600M,而AVFormer的訓練參數是4M,因此只需要訓練數據集的一小部分(HowTo100M的5%)就可以達到效果。此外,我們還在LibriSpeech上評估了性能,僅音頻這一項,AVFormer就超過了兩個基線。
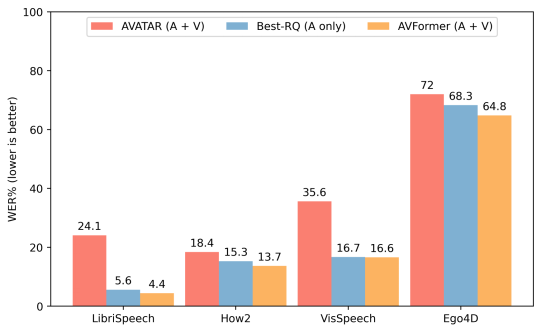
與不同AV-ASR數據集的零樣本性能的最新方法進行比較。展示了在僅音頻的LibriSpeech上的性能。結果顯示WER%(越低越好)的報告。AVATAR和BEST-RQ在HowTo100M上進行了端到端的微調(所有參數),而AVFormer即使只使用了數據集的5%,也能有效工作,這得益于微調參數的小集合
結論
我們介紹了AVFormer,這是一種輕量級的方法,用于將現有的,凍結的最先進的ASR模型適應AV-ASR。我們的方法實用且高效,實現了令人印象深刻的零樣本性能。隨著ASR模型越來越大,調整預訓練模型的整個參數集變得不切實際(對于不同的領域更是如此)。我們的方法無縫地實現了,在同一個參數有效的模型中進行領域轉移和視覺輸入混合。
譯者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。
原文標題:AVFormer: Injecting vision into frozen speech models for zero-shot AV-ASR,作者:Arsha Nagrani,Paul Hongsuck Seo



























