世界超大芯片解鎖“人腦級(jí)”AI模型,集群頂配1.63億核心

今日凌晨,Cerebras Systems宣布推出 世界上第一個(gè)人類大腦規(guī)模的AI解決方案,一臺(tái)CS-2 AI計(jì)算機(jī)可支持超過(guò)120萬(wàn)億參數(shù)規(guī)模的訓(xùn)練。 相比之下,人類大腦大約有100萬(wàn)億個(gè)突觸。
此外,Cerebras還 實(shí)現(xiàn)了192臺(tái)CS-2 AI計(jì)算機(jī)近乎線性的擴(kuò)展,從而打造出包含高達(dá)1.63億個(gè)核心的計(jì)算集群。

Cerebras成立于2016年,迄今在14個(gè)國(guó)家擁有超過(guò)350位工程師,此前Cerebras推出的世界最大計(jì)算芯片WSE和WSE-2一度震驚業(yè)界。

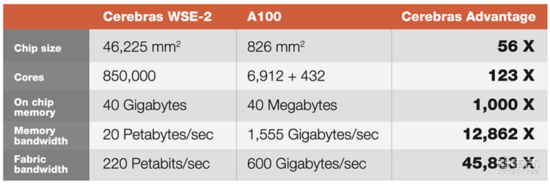
WSE-2采用7nm工藝,是一個(gè)面積達(dá)46225平方毫米的單晶圓級(jí)芯片,擁有2.6萬(wàn)億個(gè)晶體管和85萬(wàn)個(gè)AI優(yōu)化核,無(wú)論是核心數(shù)還是片上內(nèi)存容量均遠(yuǎn)高于迄今性能最強(qiáng)的GPU。
WSE-2被集成在Cerebras CS-2 AI計(jì)算機(jī)中。隨著近年業(yè)界超大規(guī)模AI模型突破1萬(wàn)億參數(shù),小型集群難以支撐單個(gè)模型的高速訓(xùn)練。
而Cerebras最新公布的成果, 將單臺(tái)CS-2機(jī)器可支持的神經(jīng)網(wǎng)絡(luò)參數(shù)規(guī)模,擴(kuò)大至現(xiàn)有最大模型的100倍——達(dá)到120萬(wàn)億參數(shù) 。

在國(guó)際芯片架構(gòu)頂會(huì)Hot Chips上,Cerebras聯(lián)合創(chuàng)始人兼首席硬件架構(gòu)師Sean Lie詳細(xì)展示了實(shí)現(xiàn)這一突破的 新技術(shù)組合, 包括4項(xiàng)創(chuàng)新:
(1)Cerebras Weight Streaming:一種新的軟件執(zhí)行架構(gòu), 首次實(shí)現(xiàn)在芯片外存儲(chǔ)模型參數(shù)的能力,同時(shí)提供像片上一樣的訓(xùn)練和推理性能 。這種新的執(zhí)行模型分解了計(jì)算和參數(shù)存儲(chǔ),使得擴(kuò)展集群大小和速度更加獨(dú)立靈活,并消除了大型集群往往面臨的延遲和內(nèi)存帶寬問(wèn)題,極大簡(jiǎn)化工作負(fù)載分布模型, 使得用戶無(wú)需更改軟件,即可從使用1臺(tái)CS-2擴(kuò)展到192臺(tái)CS-2。
(2)Cerebras MemoryX:一種內(nèi)存擴(kuò)展技術(shù),為WSE-2提供高達(dá)2.4PB的片外高性能存儲(chǔ),能保持媲美片上的性能。 借助MemoryX,CS-2可以支持高達(dá)120萬(wàn)億參數(shù)的模型。

(3)Cerebras SwarmX:是一種高性能、AI優(yōu)化的通信結(jié)構(gòu),將片上結(jié)構(gòu)擴(kuò)展至片外,使Cerebras能夠 連接多達(dá)192臺(tái)CS-2的1.63億個(gè)AI優(yōu)化核 ,協(xié)同工作來(lái)訓(xùn)練單個(gè)神經(jīng)網(wǎng)絡(luò)。
(4)Selectable Sparsity:一種動(dòng)態(tài)稀疏選擇技術(shù),使用戶能夠在模型中選擇權(quán)重稀疏程度,并直接減少FLOP和解決時(shí)間。權(quán)重稀疏在機(jī)器學(xué)習(xí)研究領(lǐng)域一直頗具挑戰(zhàn)性,因?yàn)樗贕PU上效率極低。該技術(shù)使CS-2能夠加速工作,并使用包括非結(jié)構(gòu)化和動(dòng)態(tài)權(quán)重稀疏性在內(nèi)的各種可用稀疏性類型在更短的時(shí)間內(nèi)生成答案。

Cerebras首席執(zhí)行官兼聯(lián)合創(chuàng)始人Andrew Feldman稱這推動(dòng)了行業(yè)的發(fā)展。阿貢國(guó)家實(shí)驗(yàn)室副主任Rick Stevens亦肯定這一發(fā)明,認(rèn)為這將是我們第一次能夠探索大腦規(guī)模的模型,為研究和見(jiàn)解開(kāi)辟?gòu)V闊的新途徑。
一、 Weight Streaming :存算分離,實(shí)現(xiàn)片外存儲(chǔ)模型參數(shù)
使用大型集群解決AI問(wèn)題的最大挑戰(zhàn)之一,是為特定的神經(jīng)網(wǎng)絡(luò)設(shè)置、配置和優(yōu)化它們所需的復(fù)雜性和時(shí)間。軟件執(zhí)行架構(gòu)Cerebras Weight Streaming恰恰能降低對(duì)集群系統(tǒng)編程的難度。

Weight Streaming建立在WSE超大尺寸的基礎(chǔ)上,其計(jì)算和參數(shù)存儲(chǔ)完全分離。通過(guò)與最高配置2.4PB的存儲(chǔ)設(shè)備MemoryX結(jié)合,單臺(tái)CS-2可支持運(yùn)行擁有120萬(wàn)億個(gè)參數(shù)的模型。
參與測(cè)試的120萬(wàn)億參數(shù)神經(jīng)網(wǎng)絡(luò)由Cerebras內(nèi)部開(kāi)發(fā),不是已公開(kāi)發(fā)布的神經(jīng)網(wǎng)絡(luò)。
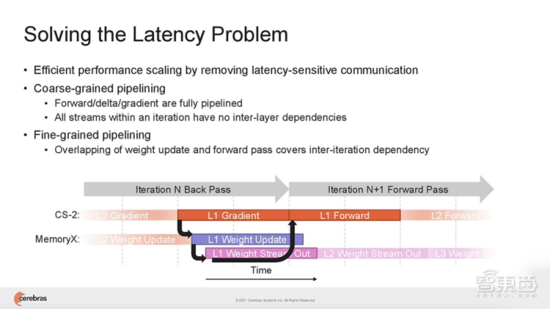
在Weight Streaming中,模型權(quán)重存在中央芯片外存儲(chǔ)位置,流到晶圓片上,用于計(jì)算神經(jīng)網(wǎng)絡(luò)的每一層。在神經(jīng)網(wǎng)絡(luò)訓(xùn)練的delta通道上,梯度從晶圓流到中央存儲(chǔ)區(qū)MemoryX中用于更新權(quán)重。
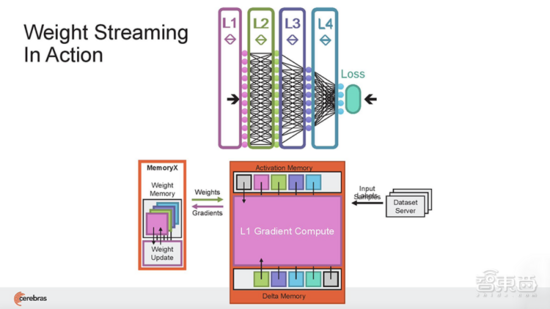
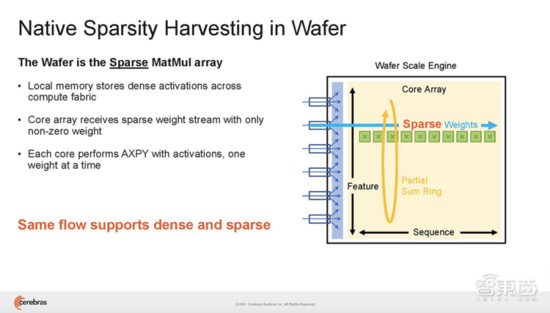
與GPU不同,GPU的片上內(nèi)存量很小,需要跨多個(gè)芯片分區(qū)大型模型,而WSE-2足夠大,可以適應(yīng)和執(zhí)行超大規(guī)模的層,而無(wú)需傳統(tǒng)的塊或分區(qū)來(lái)分解。
這種無(wú)需分區(qū)就能適應(yīng)片上內(nèi)存中每個(gè)模型層的能力,可以被賦予相同的神經(jīng)網(wǎng)絡(luò)工作負(fù)載映射,并獨(dú)立于集群中所有其他CS-2對(duì)每個(gè)層進(jìn)行相同的計(jì)算。
這帶來(lái)的好處是, 用戶無(wú)需進(jìn)行任何軟件更改,就能很方便地將模型從運(yùn)行在單臺(tái)CS-2上,擴(kuò)展到在任意大小的集群上。也就是說(shuō),在大量CS-2系統(tǒng)集群上運(yùn)行AI模型,編程就像在單臺(tái)CS-2上運(yùn)行模型一樣。
Cambrian AI創(chuàng)始人兼首席分析師Karl Freund評(píng)價(jià)道:“Weight Streaming的執(zhí)行模型非常簡(jiǎn)潔、優(yōu)雅,允許在CS-2集群難以置信的計(jì)算資源上進(jìn)行更簡(jiǎn)單的工作分配。通過(guò)Weight Streaming,Cerebras消除了我們今天在構(gòu)建和高效使用巨大集群方面所面臨的所有復(fù)雜性,推動(dòng)行業(yè)向前發(fā)展,我認(rèn)為這將是一場(chǎng)變革之旅。”
二、 MemoryX :實(shí)現(xiàn)百萬(wàn)億參數(shù)模型
擁有100萬(wàn)億個(gè)參數(shù)的人腦規(guī)模級(jí)AI模型,大約需要2PB字節(jié)的內(nèi)存才能存儲(chǔ)。
前文提及模型參數(shù)能夠在片外存儲(chǔ)并高效地流至CS-2,實(shí)現(xiàn)接近片上的性能,而存儲(chǔ)神經(jīng)網(wǎng)絡(luò)參數(shù)權(quán)重的關(guān)鍵設(shè)施,即是Cerebras MemoryX。

MemoryX是DRAM和Flash的組合,專為支持大型神經(jīng)網(wǎng)絡(luò)運(yùn)行而設(shè)計(jì),同時(shí)也包含精確調(diào)度和執(zhí)行權(quán)重更新的智能。
其架構(gòu)具有可擴(kuò)展性, 支持從4TB至2.4PB的配置,支持2000億至120萬(wàn)億的參數(shù)規(guī)模 。
三、 SwarmX :幾乎線性擴(kuò)展性能,支持 192臺(tái) CS-2 互連
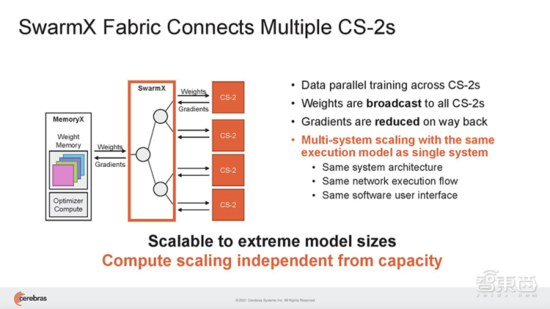
雖然一臺(tái)CS-2機(jī)器就可以存儲(chǔ)給定層的所有參數(shù),但Cerebras還提議用一種高性能互連結(jié)構(gòu)技術(shù)SwarmX,來(lái)實(shí)現(xiàn)數(shù)據(jù)并行性。
該技術(shù)通過(guò)將Cerebras的片上結(jié)構(gòu)擴(kuò)展至片外,擴(kuò)展了AI集群的邊界。
從歷史上看,更大的AI集群會(huì)帶來(lái)顯著的性能和功率損失。在計(jì)算方面,性能呈亞線性增長(zhǎng),而功率和成本呈超線性增長(zhǎng)。隨著越來(lái)越多的圖形處理器被添加到集群中,每個(gè)處理器對(duì)解決問(wèn)題的貢獻(xiàn)越來(lái)越小。
SwarmX結(jié)構(gòu)既做通信,也做計(jì)算,能使集群實(shí)現(xiàn) 接近線性的性能擴(kuò)展。這 意味著如果擴(kuò)展至16個(gè)系統(tǒng),訓(xùn)練神經(jīng)網(wǎng)絡(luò)的速度接近提高16倍。 其結(jié)構(gòu)獨(dú)立于MemoryX進(jìn)行擴(kuò)展,每個(gè)MemoryX單元可用于任意數(shù)量的CS-2。
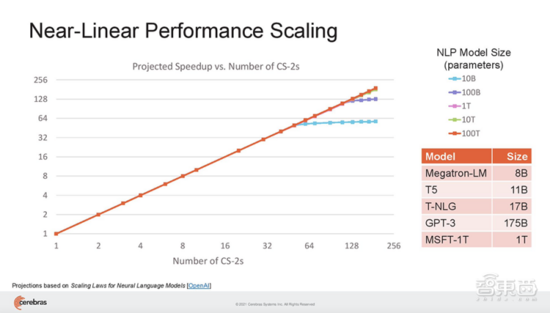
在這種完全分離的模式下, SwarmX結(jié)構(gòu)支持從2臺(tái)CS-2擴(kuò)展到最多192臺(tái),由于每臺(tái)CS-2提供85萬(wàn)個(gè)AI優(yōu)化核,因此將支持多達(dá)1.63億個(gè)AI優(yōu)化核的集群。
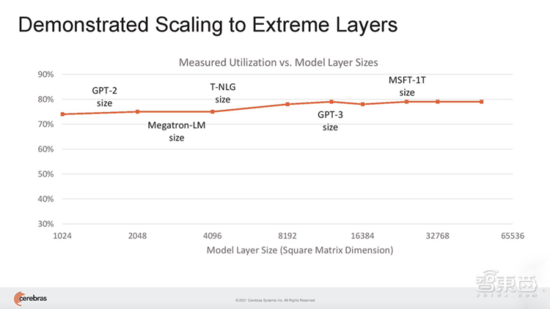
Feldman說(shuō),CS-2的利用率要高得多。其他方法的利用率在10%~20%之間,而Cerebras在最大網(wǎng)絡(luò)上的利用率在70%~80%之間。“今天每個(gè)CS2都取代了數(shù)百個(gè)GPU,我們現(xiàn)在可以用集群方法取代數(shù)千個(gè)GPU。”
四、 Selectable Sparsity :動(dòng)態(tài)稀疏提升計(jì)算效率
稀疏性對(duì)提高計(jì)算效率至為關(guān)鍵。隨著AI社區(qū)努力應(yīng)對(duì)訓(xùn)練大型模型的成本呈指數(shù)級(jí)增長(zhǎng),用稀疏性及其他算法技術(shù)來(lái)減少將模型訓(xùn)練為最先進(jìn)精度所需的計(jì)算FLOP愈發(fā)重要。
現(xiàn)有稀疏性研究已經(jīng)能帶來(lái)10倍的速度提升。
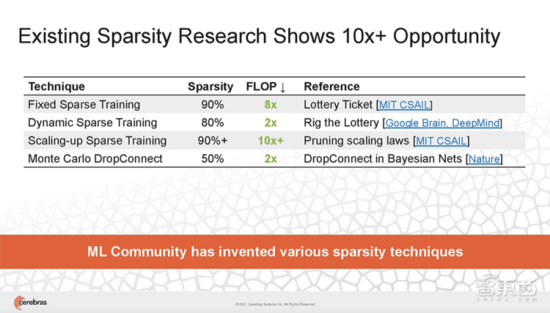
為了加速訓(xùn)練,Cerebras提出一種新的稀疏方法Selectable Sparsity,來(lái)減少找到解決方案所需的計(jì)算工作量,從而縮短了應(yīng)答時(shí)間。
Cerebras WSE基于一種細(xì)粒度的數(shù)據(jù)流架構(gòu),專為稀疏計(jì)算而設(shè)計(jì),其85萬(wàn)個(gè)AI優(yōu)化核能夠單獨(dú)忽略0,僅對(duì)非0數(shù)據(jù)進(jìn)行計(jì)算。這是其他架構(gòu)無(wú)法做到的。
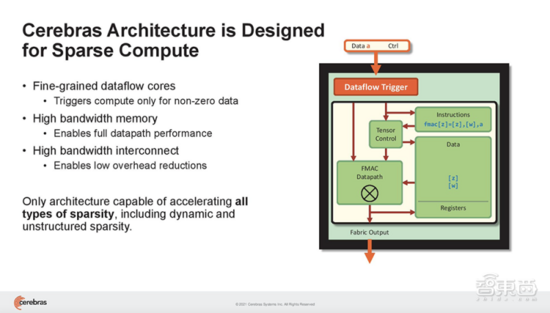
在神經(jīng)網(wǎng)絡(luò)中,稀疏有多種類型。稀疏性可以存在于激活和參數(shù)中,可以是結(jié)構(gòu)化或非結(jié)構(gòu)化。
Cerebras架構(gòu)特有的數(shù)據(jù)流調(diào)度和巨大的內(nèi)存帶寬,使此類細(xì)粒度處理能加速動(dòng)態(tài)稀疏、非結(jié)構(gòu)化稀疏等一切形式的稀疏。結(jié)果是,CS-2可以選擇和撥出稀疏,以產(chǎn)生特定程度的FLOP減少,從而減少應(yīng)答時(shí)間。
結(jié)語(yǔ):新技術(shù)組合讓集群擴(kuò)展不再?gòu)?fù)雜
大型集群歷來(lái)受設(shè)置和配置挑戰(zhàn)的困擾,準(zhǔn)備和優(yōu)化在大型GPU集群上運(yùn)行的神經(jīng)網(wǎng)絡(luò)需要更多時(shí)間。為了在GPU集群上實(shí)現(xiàn)合理的利用率,研究人員往往需要人工對(duì)模型進(jìn)行分區(qū)、管理內(nèi)存大小和帶寬限制、進(jìn)行額外的超參數(shù)和優(yōu)化器調(diào)優(yōu)等復(fù)雜而重復(fù)的操作。
而通過(guò)將Weight Streaming、MemoryX和SwarmX等技術(shù)相結(jié)合,Cerebras簡(jiǎn)化了大型集群的構(gòu)建過(guò)程。它開(kāi)發(fā)了一個(gè)全然不同的架構(gòu),完全消除了擴(kuò)展的復(fù)雜性。由于WSE-2足夠大,無(wú)需在多臺(tái)CS-2上劃分神經(jīng)網(wǎng)絡(luò)的層,即便是當(dāng)今最大的網(wǎng)絡(luò)層也可以映射到單臺(tái)CS-2。
Cerebras集群中的每臺(tái)CS-2計(jì)算機(jī)將有相同的軟件配置,添加另一臺(tái)CS-2幾乎不會(huì)改變?nèi)魏喂ぷ鞯膱?zhí)行。因此,在數(shù)十臺(tái)CS-2上運(yùn)行神經(jīng)網(wǎng)絡(luò)與在單個(gè)系統(tǒng)上運(yùn)行在研究人員看來(lái)是一樣的,設(shè)置集群就像為單臺(tái)機(jī)器編譯工作負(fù)載并將相同的映射應(yīng)用到所需集群大小的所有機(jī)器一樣簡(jiǎn)單。
總體來(lái)說(shuō),Cerebras的新技術(shù)組合旨在加速運(yùn)行超大規(guī)模AI模型,不過(guò)就目前AI發(fā)展進(jìn)程來(lái)看,全球能用上這種集群系統(tǒng)的機(jī)構(gòu)預(yù)計(jì)還很有限。