AI根據代碼內容自動起函數名,再也不怕命名不規范的同事了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
有的人能把代碼寫成推理小說。
需要一個臨時變量的時候就叫temp,需要多個就叫var1,var2。
甚至用拼音縮寫當函數名,比如查詢訂單就叫cxdd。
要想看懂這樣的代碼,得聯系上下文反復推敲,還原每個部分的真實作用。
這個過程叫做反混淆(Deobfuscation)。
麻煩,著實麻煩。就沒有省事兒點的辦法嗎?
讓AI來啊!
最近,Facebook就出了這樣一個語言模型DOBF,專治代碼混淆。
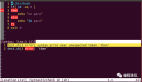
像下圖這種,所有不影響運行的變量名、函數名、類名,都被替換成無意義的符號,AI都能作出猜測并嘗試還原。

來看看和正確答案的對比,雖然不是完全一樣,但AI的改法也大大提高了代碼的可讀性。

像FUNC_0,源代碼中是“重置參數”,AI改成“初始化權重”,也完全說得通。
DOBF模型目前除了Python還支持C++和Java。
編碼不規范的人畢竟是少數,這個模型更廣泛的用途是恢復故意做混淆以保護知識產權的代碼,比如這種:
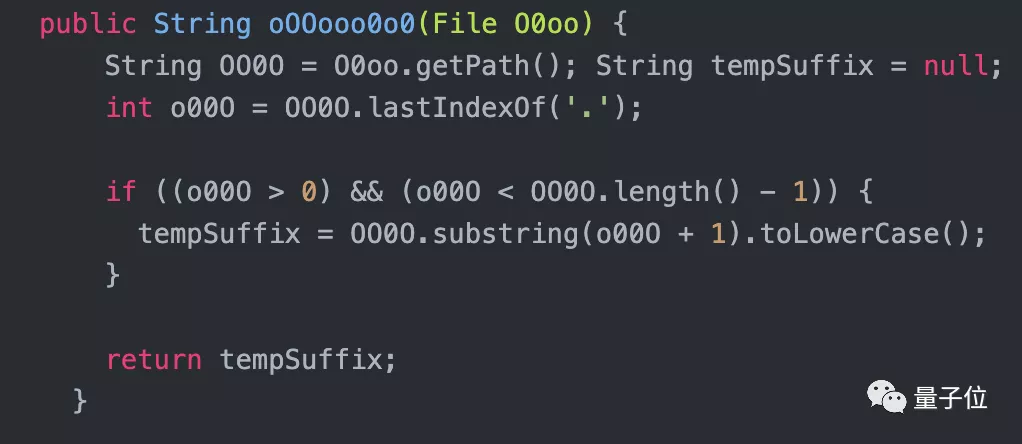
代碼寫好后,把不影響編譯運行的部分,批量替換成人類難以分辨的符號,給破譯增加難度。
在這之前也有掩碼語言模型(Masked Language Model)用于恢復被遮蔽的文本。
用于恢復代碼的有哈工大&微軟開發的CodeBERT和Facebook之前開發的TransCoder,但效果都不如最新的DOBF。
DOBF超過它們靠的不是模型架構上的創新或數據集的完善,而是提出了新的預訓練任務。
合理的任務指導AI學習
之前的掩碼語言模型多是隨機選擇要掩蔽的部分,經常會選到括號逗號這種對AI來說沒什么難度的。
DOBF的做法是指定遮蔽變量名、函數名和類名并讓AI去恢復,這個任務難度更大,能迫使AI學到更深層的規律。
另外還用相同的符號替代多次出現的同一名稱,這樣可以防止AI發現有的名字可以復制粘貼之后學會偷懶走捷徑。
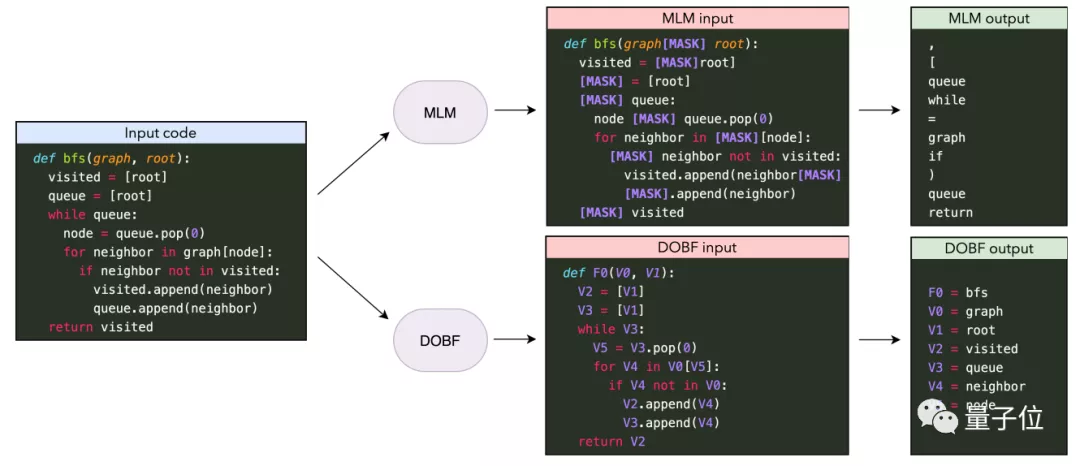
像上圖中的變量V3,AI從第3行的定義可以看出這個變量是List類型,再一看第5行調用的是pop(0)。
這不是先進先出嘛,AI就會命名成queue(隊列)而不是stack(堆棧)了。
更厲害的還在后面,DOBF通過代碼內容甚至能判斷出相應函數是生成斐波那契數列和做向量點積的。
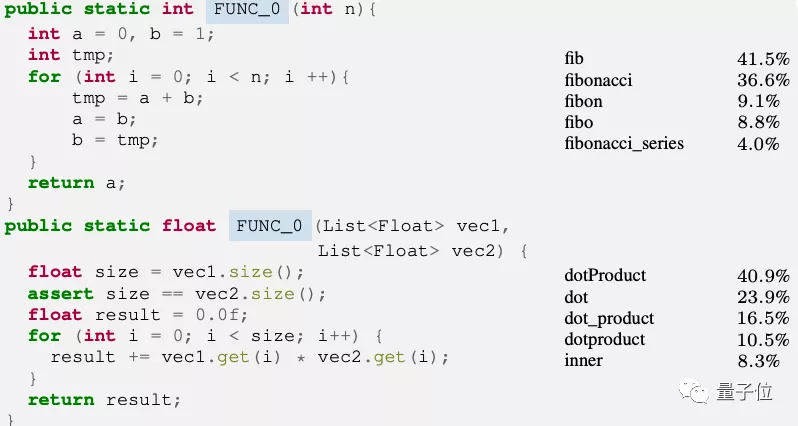
DOBF在架構上其實沒有特別的設計,只是為了公平對比分別訓練了兩個和CodeBERT、TransCoder層數一樣的模型。
成功的關鍵之處就在于合理的訓練任務。
微調一下能完成更多任務
驗證了這個方法有效后,Facebook把這個訓練任務提取出來稱為DOBF任務,還可以用于訓練其他語言模型。
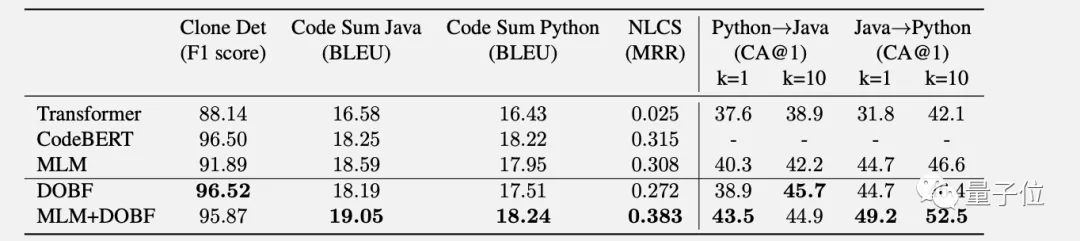
比如在TransCoder模型上把DOBF作為預訓練任務,再用CodeXGLUE基準測試中的下游任務進行微調。
結果在代碼抄襲檢測、總結代碼生成文檔、和自然語言搜索代碼片段這3個任務上,使用DOBF或MLM+DOBF預訓練都取得了更好的成績。
Facebook下一步還要以DOBF作為指導,看看能不能為自然語言設計更好的預訓練目標。
不過代碼上的事還不算完,人類在混淆代碼上可是無所不用其極的。
期待著有一天,AI連國際C語言混亂代碼大賽上的變態代碼也能看懂。

Github地址:
https://github.com/facebookresearch/CodeGen/blob/master/docs/dobf.md
論文地址:
https://arxiv.org/abs/2102.07492
國際C語言混亂代碼大賽:
http://www.ioccc.org/