用KANO和PSM兩大模型,幫你學會分析需求和產品定價
KANO 模型和 PSM 模型都是用戶研究和設計師在日常工作中經常使用的分析模型,可以幫助界定用戶需求的優先級和付費區間。
KANO 是什么?
KANO 模型是對用戶需求分類和優先排序的模型,以分析用戶需求對用戶滿意的影響為基礎,體現了產品性能和用戶滿意之間的非線性關系。由東京理工大學教授野紀紹(Noriaki Kano)在 70 年代發明。

PSM 是什么?
PSM 模型也即價格敏感度測試模型(Price Sensitivity Measurement),顧名思義,是進行產品、服務價格測試的模型。PSM 價格敏感度分析方法是在 70 年代由 Van Westendrop 所創建。

如何使用 KANO 和 PSM 模型?
1. 使用場景
KANO:需求的分析,如在產品開發前,我們需要知道這些功能哪些是基本功能,哪些是增值功能,功能的優先級又該如何排列等,可以通過 KANO 模型來界定。
PSM:當我們確定好產品的功能時,在后續定價的時候,又可以使用 PSM 模型來進行價格測試,來尋求最優價格、最優價格區間等信息。
有預設價格范圍,優化產品或有競品產品,會有大致的價格范圍和參考
無預設價格范圍,如完全的新產品,需要把產品概念解釋清楚并了解消費者現在的解決方案成本
2. 使用流程
兩者的使用流程均為:從明確目的–問卷設計–數據處理–結果呈現。
其中價格敏感度測試模型中關于問卷設計中的價格區間設定,有兩種可以實現的方式:
- 制作價格梯度表,以選項的方式展示,但是會受到每個選項之間價格梯度的設置限制,如果在高額的產品價格中,使用這種選項就不太合適,如:汽車價格。
- 有些產品由于較為成熟,或者有競品的情況下,可以直接使用開放題的形式進行設置,被訪者的自由度更大,當然可以在程序中設置最低或最高的價格限制,以防極端數據出現。
KANO 案例使用
1. 問卷設置
問卷設置劃分維度主要分為正反兩方面:提供時的滿意程度、不提供時的滿意程度。
每個功能/方面都需要提供正反兩方面的題目,可以進行適當標紅/加粗手段防止用戶看錯。

2. 樣本設置
為了達到統計意義上的樣本量,建議定量的樣本量達到 30 以上。
在后續進行問卷數據清洗時可能會清洗掉部分不符合樣本,可以適當增加樣本量。
在實際操作中,也可能在定性的研究中使用這一模型,即不再要求 30 以上的樣本量。
3. 整理分類
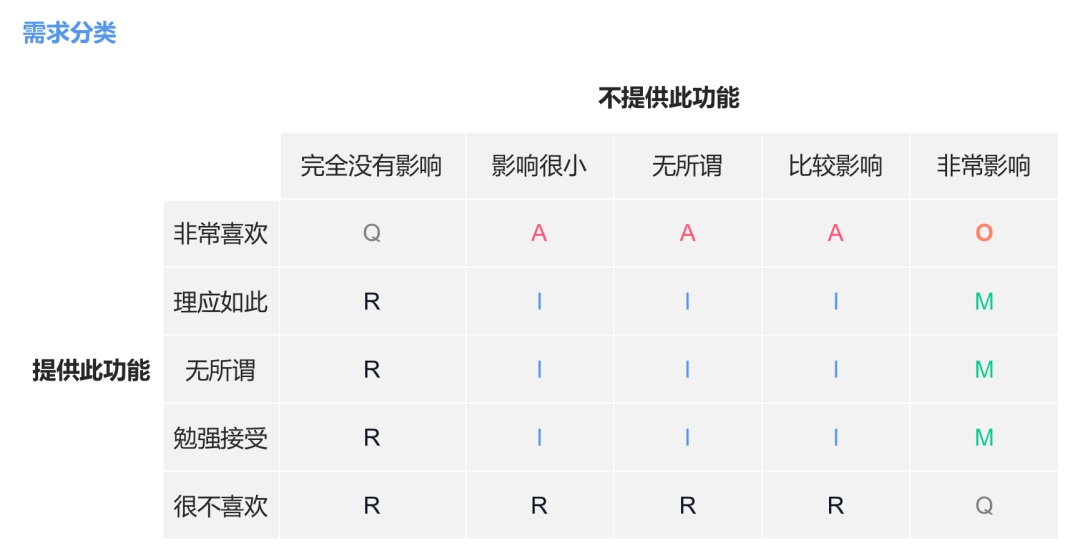
把提供此功能和不提供此功能進行交叉,會得出 6 種不同的需求類型:
- A:興奮/魅力型
- O:期望/意愿型
- M:基本/必備型
- I:無差異型
- R:反向/逆向型
- Q:可疑結果
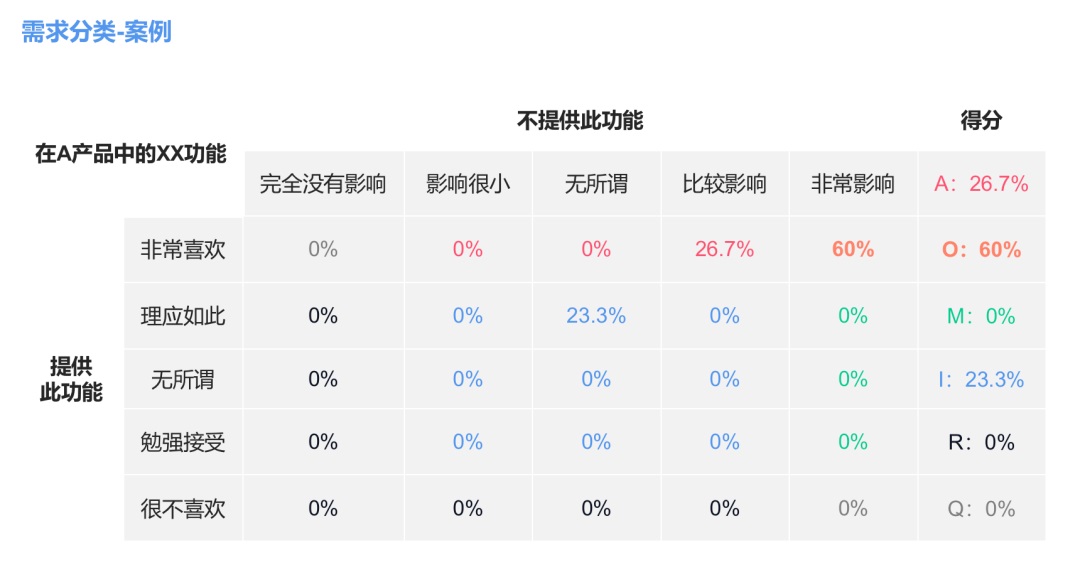
根據用戶對某一功能的評價,得出這一功能在以上 6 個分類屬性中的比例,例如我們對 A 產品中的 XX 功能得出它的屬性為 O:期望/意愿型,即當提供此需求,用戶滿意度會提升;當不提供此需求,用戶滿意度會降低。
4. 數據分析
在得出各個功能的屬性對應后,可以計算 better-worse 系數,以便進行四象限圖的展示。
- 增加后的滿意系數 Better=(A+O)/(A+O+M+I)
- 消除后的不滿意系數 Worse= -1 *(O+M)/(A+O+M+I)
例如我們對 A 產品中的 XX 功能得出它的系數如下:
- Better=(26.7%+60%)/(26.7%+60%+0%+23.3%)=86.7%
- Worse=-1*(60%+0%)/(26.7%+60%+0%+23.3%)=-60%
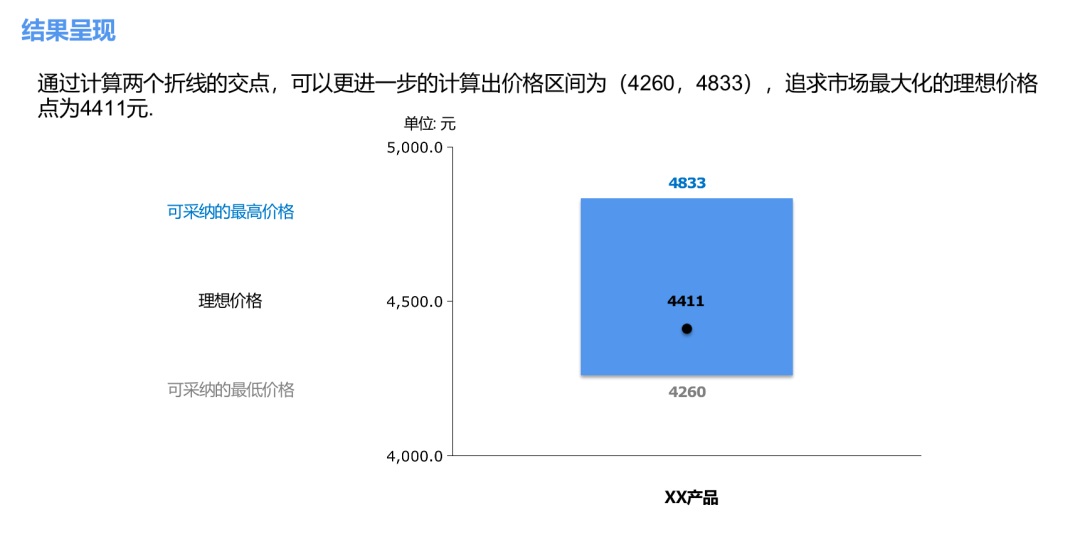
5. 結果呈現
計算各個屬性的 better-worse 系數,然后通過四象限圖的形式展示出來。
以 better 系數和 worse 系數分別為橫縱坐標,中點為界,分為:
- 第一象限為興奮/魅力型:若不提供此需求,用戶滿意度不會降低;若提供此需求,用戶滿意度會有很大的提升;
- 第二象限為期望/意愿型:當提供此需求,用戶滿意度會提升;當不提供此需求,用戶滿意度會降低;
- 第三象限為無差異型:不論提供與否,對用戶體驗無影響;
- 第四象限為基本/必備型:當不提供此需求,用戶滿意度會大幅降低,但優化此需求,用戶滿意度不會得到顯著提升。

在實際日常工作中:
- 我們首先要滿足用戶最基本的需求,即第四象限表示的基本/必備型因素。
- 在滿足最基本的需求之后,再盡力去滿足用戶的期望/意愿型需求,即第二象限的功能需求,這是競爭性因素。提供用戶喜愛的額外服務或產品功能,使其產品和服務優于競爭對手并有所不同,引導用戶加強對本產品的良好印象。
- 最后爭取實現用戶的興奮/魅力型需求,即第一象限表示因素,提升用戶的忠誠度。
PSM 案例使用
1. 問卷設置
主要是 4 道題目,詢問被訪者:太便宜以至于懷疑品質不購買的價格、比較便宜的價格、比較貴的價格、太貴以至于不購買的價格。
問卷可以選擇選項型和開放題型,根據價格的范圍和想要的范圍精度選擇。


2. 樣本數量
為了達到統計意義上的樣本量,建議樣本量達到 30 以上。
為了解決被訪者抬高或壓低價格的問題,可以增加樣本量,抵消隨機誤差。
如果以價格選項的形式進行問卷,還可以設計價格分組,通過不同的價格方案設計 2 組或幾組價格區間,進行投放問卷,互相驗證。
3. 數據處理
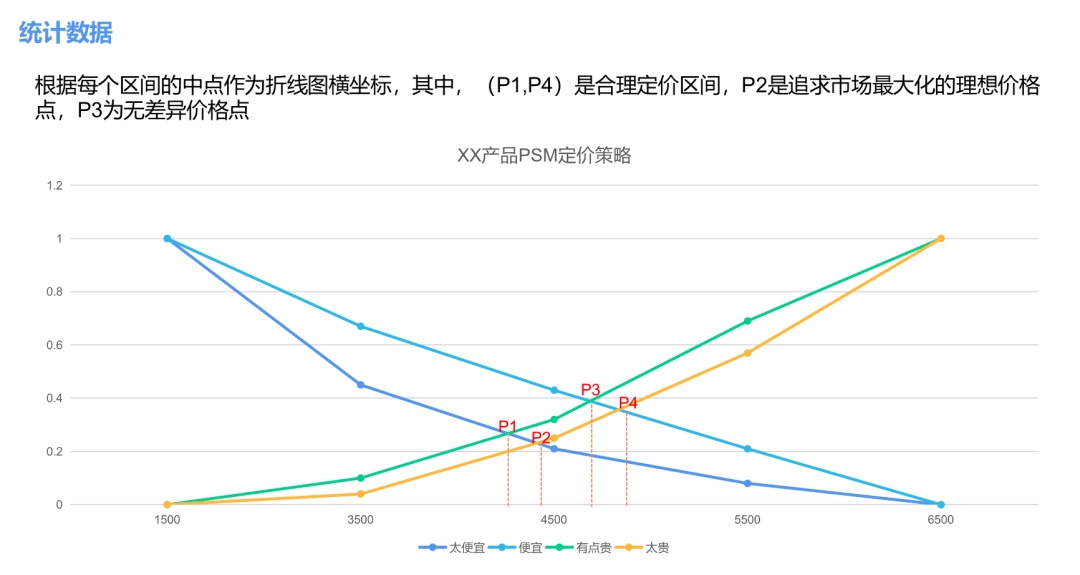
對“太便宜”和“便宜”的價格百分比進行向下累計統計,對“貴”和“太貴”的百分比進行向上累計統計,得出如下圖所示的四條價格線。其中,“太便宜”和“太貴”的交點確定出最優價格,因為在這種情況下,既不覺得“太貴”也不覺得“太便宜”的人數是最多的,對于企業而言,在該價格上,有最多的消費者可能去購買他的產品。同時,由“太便宜”和“貴”,“便宜 和“太貴”確定出可接受的價格區間。
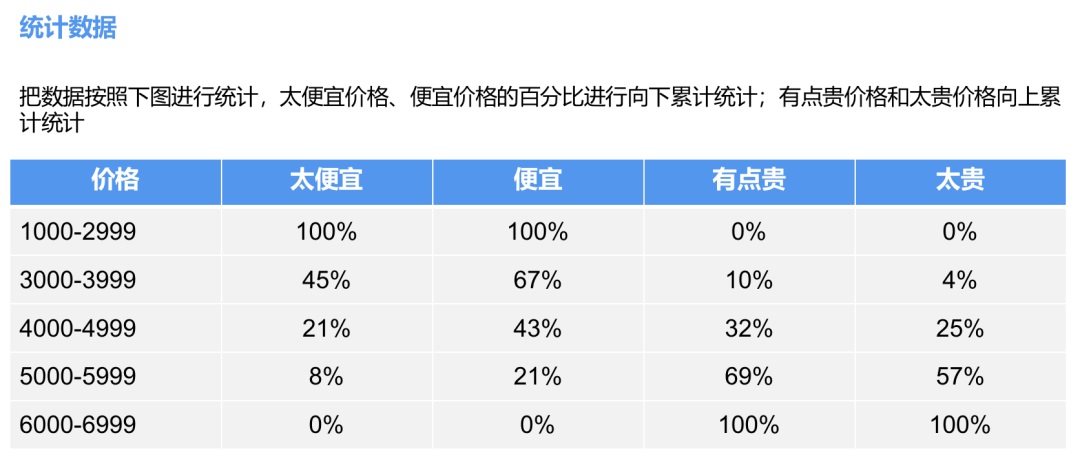
根據統計表畫折線圖:
4. 結果呈現
結果的呈現既可以使用上述的折線圖,表達合理價格區間在(3500,5500),甚至更小的范圍(4000,5000),追求市場最大化的理想價格點在 4500 左右。
也可以進行更準確的計算,根據計算折線的交點,得出以下結果: