拒絕反爬蟲!教你搞定爬蟲驗證碼
本文轉(zhuǎn)載自微信公眾號「數(shù)倉寶貝庫」,作者趙國生,王健。轉(zhuǎn)載本文請聯(lián)系數(shù)倉寶貝庫公眾號。
目前,許多網(wǎng)站采取各種各樣的措施來反爬蟲,其中一個措施便是使用驗證碼。隨著技術(shù)的發(fā)展,驗證碼的花樣越來越多。驗證碼最初是幾個數(shù)字組合的簡單的圖形驗證碼,后來加入了英文字母和混淆曲線。有的網(wǎng)站還可能看到中文字符的驗證碼,這使得識別越發(fā)困難。
使用驗證碼可以防止應(yīng)用或者網(wǎng)站被惡意注冊、攻擊,對于網(wǎng)站、APP而言,大量的無效注冊、重復(fù)注冊甚至是惡意攻擊很令人頭痛。使用驗證碼能夠很大程度上減少這些惡意操作。驗證碼變得越來越復(fù)雜,爬蟲的工作也變得越發(fā)艱難。有時候我們必須通過驗證碼的驗證才能夠訪問頁面(如圖1所示)。
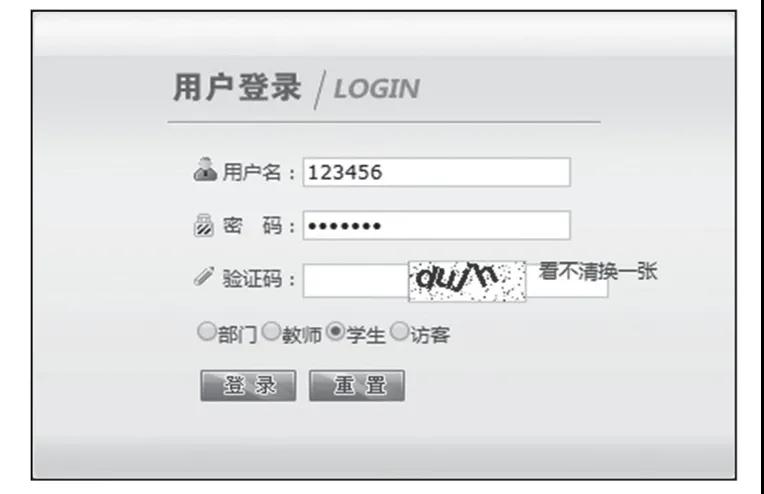
圖1 驗證碼界面
目前主流的 4 種驗證碼為輸入式驗證碼、滑動式驗證碼、宮格式驗證碼和點擊式的圖文驗證,下面我們來分別講解它們的解決思路。
4種驗證碼的解決思路
01 輸入式驗證碼
這種驗證碼主要是通過用戶輸入圖片中的字母、數(shù)字、漢字等進(jìn)行驗證,如圖2所示。

圖2 輸入式驗證碼
解決思路:這是最簡單的一種驗證碼,只要識別出里面的內(nèi)容,然后填入輸入框中即可。這種識別技術(shù)叫OCR,這里推薦使用 Python 的第三方庫 tesserocr。tesserocr 與 pytesseract 是 Python 的一個 OCR 識別庫,但其實是對 Tesseract 做的一層 Python API 封裝,pytesseract 是 Google 的 Tesseract-OCR 引擎包裝器;所以它們的核心是 Tesseract。對于沒有什么背景影響的驗證碼,直接通過這個庫來識別就可以。但是對于有嘈雜的背景的驗證碼,直接識別的識別率會很低,遇到這種驗證碼需要先對圖片進(jìn)行灰度化,然后再進(jìn)行二值化,再去識別,這樣識別率會大大提高。
02 滑動式驗證碼
這種是將備選碎片直線滑動到正確的位置,如圖3所示。

圖3 滑動式驗證碼
解決思路:對于這種驗證碼就比較復(fù)雜一點,但也是有相應(yīng)的辦法。我們直接想到的就是模擬人去拖動驗證碼的行為,點擊按鈕,然后看到了缺口的位置,最后把拼圖拖到缺口位置處完成驗證。
第一步:點擊按鈕。當(dāng)沒有點擊按鈕的時候圖片中的缺口和拼圖是沒有出現(xiàn)的,點擊后才出現(xiàn),這為我們找到缺口的位置提供了靈感。
第二步:拖到缺口位置。我們知道拼圖應(yīng)該拖到缺口處,但是這個距離如何用數(shù)值來表 示?通過第一步觀察到的現(xiàn)象,我們可以找到缺口的位置。這里我們可以比較兩張圖的像素, 設(shè)置一個基準(zhǔn)值,如果某個位置的差值超過了基準(zhǔn)值,那我們就找到了這兩張圖片不一樣的位置,當(dāng)然我們是從那塊拼圖的右側(cè)開始并且從左到右,找到第一個不一樣的位置時就結(jié)束,這時的位置應(yīng)該是缺口的 left,所以我們使用 selenium 拖到這個位置即可。這里還有個疑問,就 是如何能自動保存這兩張圖?我們可以先找到這個標(biāo)簽,然后獲取它的 location 和 size,接著 是 top = int(location['y'])、bottom = int(location['y'] + size['height'])、left = int(location['x']) 以及right = int(location['x'] + size['width']),然后截圖,最后摳圖填入這四個位置就行。具體的使用 可以查看 selenium 文檔,點擊按鈕前摳一張圖,點擊后再摳一張圖。最后拖動時需要模擬人的 行為,先加速然后減速。因為這種驗證碼有行為特征檢測,人是不可能做到一直勻速的,否則 它就判定為是機(jī)器在拖動,這樣就無法通過驗證了。
03 宮格驗證碼
如圖4所示的驗證碼,爬蟲難度比較大,每一次出現(xiàn)的都不一樣,就算出現(xiàn)一樣的,其拖動順序也不相同。但是,我們發(fā)現(xiàn)不一樣的驗證碼個數(shù)是有限的,這里采用模版匹配的方 法,把所有出現(xiàn)的驗證碼保存下來,然后挑出不一樣的驗證碼,按照拖動順序命名。我們從 左到右從上到下,將其分別設(shè)為 1、2、3、4。上圖的滑動順序為 4→3→2→1,所以我們命名 4_3_2_1.png。當(dāng)驗證碼出現(xiàn)的時候,用我們保存的圖片一一枚舉,與出現(xiàn)的這種來比較像素, 方法見“滑動式驗證碼”部分。如果匹配上了,拖動順序就為 4→3→2→1。然后使用 selenium 模擬即可。
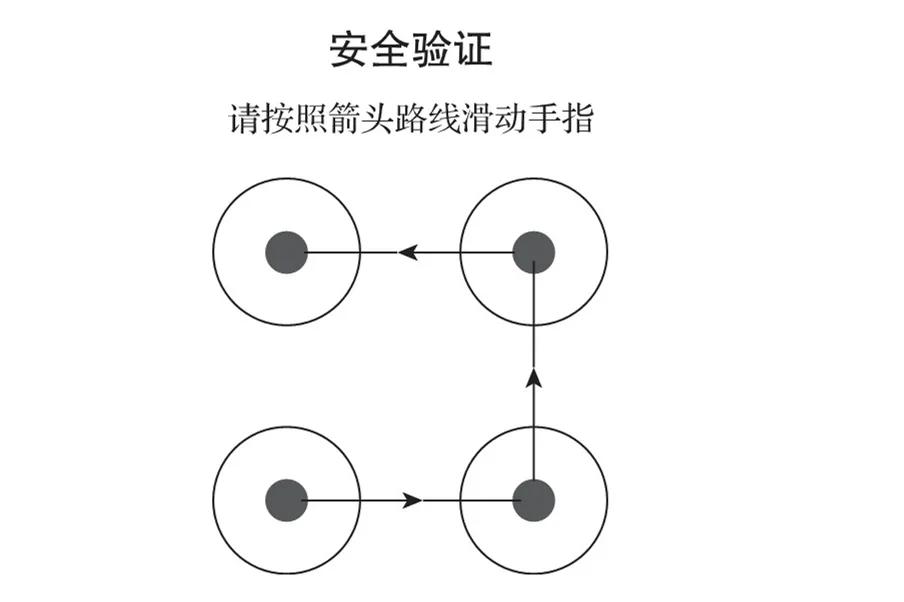
圖4 宮格驗證碼
04 點擊式的圖文驗證和圖標(biāo)選擇
1)圖文驗證:通過文字提醒用戶點擊圖中相同字的位置從而進(jìn)行驗證。
2)圖標(biāo)選擇:給出一組圖片,按要求點擊其中一張或多張。借用萬物識別的難度阻擋 機(jī)器。這兩種原理相似,只不過一個是給出文字,點擊圖片中的文字,而一個是給出圖片,點 出內(nèi)容相同的圖片。這兩種都沒有特別好的方法,只能借助第三方識別接口來識別出相同的內(nèi) 容。推薦一個方法,把驗證碼發(fā)過去,會返回相應(yīng)的點擊坐標(biāo),然后再使用 selenium 模擬點擊即可。
OCR驗證碼
圖片
OCR(Optical Character Recognition,光學(xué)字符識別)是指電子設(shè)備(例如掃描儀或數(shù)碼相機(jī))檢查紙上打印的字符,通過檢測暗、亮的模式來確定其形狀,然后用字符識別方法將形狀翻譯成計算機(jī)文字的過程,下面介紹使用這種圖像識別技術(shù)輸入驗證碼的方法。
驗證碼識別基本步驟:
1)預(yù)處理
2)灰度化
3)二值化
4)去噪
5)分割
6)識別
在使用pytesseract之前,必須安裝 Tesseract-OCR,因為pytesserat 依賴于 Tesseract-OCR, 若未安裝則無法使用。首先使用 pytesseract 將彩色的圖像轉(zhuǎn)化為灰色的圖像。
- # 使用路徑導(dǎo)入圖片
- im = Image.open(imgimgName)
- # 使用byte流導(dǎo)入圖片
- # im = Image.open(io.BytesIO(b))
- # 轉(zhuǎn)化到灰度圖
- imgry = im.convert('L')
- # 保存圖像
- imgry.save('gray-'+imgName)
灰度化的圖像如圖5所示。

圖5 灰度化圖像
緊接著將所得的圖像二值化,將圖片處理為只有黑白兩色的圖片,利于后面的圖像處理和識別。
- # 二值化,采用閾值分割法,threshold為分割點
- Threshold = 140
- Table = [ ]
- For j in range(256):
- If j < threshold:
- Table.append(0)
- Else:
- Table.append(1)
- Out = imgry.point(table,'1')
- Out.save('b'+imgName)
二值化的圖像如圖 6 所示。

圖6 二值化圖像
最后進(jìn)行識別,得到的結(jié)果如圖7所示。
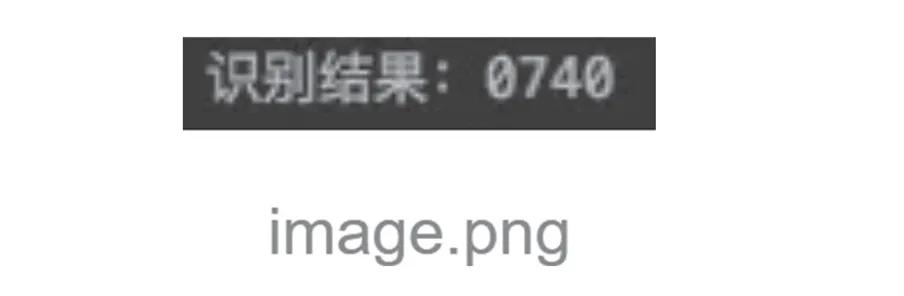
圖7 識別結(jié)果
- # 識別
- Text = pytesseract.image_to_string(out)
- Print(“識別結(jié)果:" +text)
實戰(zhàn)案例
目前,很多網(wǎng)站為了防止爬蟲肆意模擬瀏覽器登錄,采用增加驗證碼的方式來攔截爬蟲。驗證碼的形式有多種,最常見的就是圖片驗證碼。
1 基本識別原理概述
1)每一幅圖像在結(jié)構(gòu)上,都是由一個個像素組成的矩陣,每一個像素都為單元格。
2)彩色圖像的像素由三原色(紅、綠、藍(lán))構(gòu)成 元組,灰度圖像的像素是一個單值,每個像素的值范圍為(0, 255)。
某系統(tǒng)門戶登錄界面中的驗證碼如圖8所示, 現(xiàn)在我們要實現(xiàn)自動的驗證碼識別。

圖8 驗證碼
2 圖像特征
首先,我們仔細(xì)觀察一下這個驗證碼圖像,可以發(fā)現(xiàn)一些如圖9所示的固定特征。
1)驗證碼中的字符數(shù)始終為 6,并且是灰度圖像。
2)字符間的間隔看起來每次都一樣。
3)每個字符都是完全定義的。
4)圖像有許多雜散的黑暗像素,以及穿過圖像的線條作為干擾因素。
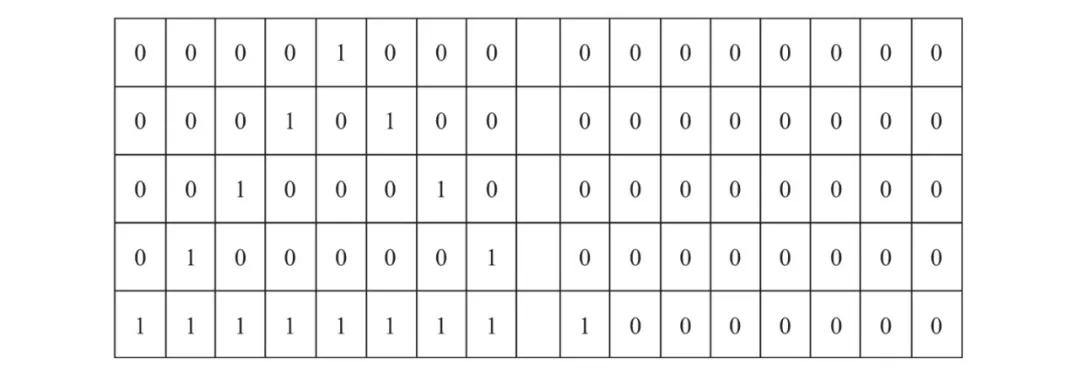
圖9 固定特征
3 圖像分析
使用一個工具(binary-image)以二進(jìn)制形式可視化圖像(0 表示黑色像素,1 表示白色像 素)。圖像尺寸為 45×180,每個字符分配 30 個像素的空間來進(jìn)行適配,從而使它們的間隔比 較均勻。因此,取得了驗證碼識別路上的第一步。如圖10所示的結(jié)果:把圖像裁剪成 6 個不同的部分,每個部分的寬度均為 30 像素。

圖10 二進(jìn)制可視化圖像
4 字符部分裁剪
圖像裁剪的語法如下:
- from PIL import Image
- image = Image.open("filename.png")
- cropped_image = image.crop((left, upper, right, lower)
比如要裁剪第一個字符:
- from PIL import Image
- image = Image.open("captcha.png").convert("L")
- cropped_image = image.crop((0, 0, 30, 45))
- cropped_image.save("cropped_image.png")
得到的圖像如圖11所示。

圖11 結(jié)果圖像
將其打包到一個循環(huán)中,編寫了一個簡單的腳本,從該站點獲取 500 個驗證碼圖像,并將所有裁剪后的字符保存到一個文件夾中。
5 圖像去雜
為了“清理”圖像中的干擾因素(刪除不必要的線和點),我們可以使用一個很簡單的算法:字符中的所有像素都是純黑色(0)。如果它不是完全黑色的,則將它當(dāng)成白色的。因此,對于值大于0的每個像素,將給其重新賦值為255。使用 load() 函數(shù)將圖像轉(zhuǎn)換為 45×180 數(shù)字矩陣,然后對其進(jìn)行處理。
- pixel_matrix = cropped_image.load()
- for col in range(0, cropped_image.height):
- for row in range(0, cropped_image.width):
- if pixel_matrix[row, col] != 0:
- pixel_matrix[row, col] = 255
- image.save("thresholded_image.png"
為了清晰起見,將代碼應(yīng)用于原始圖像。原始圖像如圖12所示。

圖12 原始圖像
矯正后的圖像如圖13所示。

圖13 矯正后的圖像
可以看到,并非完全黑暗的所有像素都被刪除了,比如通過圖像的線。上述方法在圖像處理 中的專業(yè)術(shù)語叫作閾值處理,當(dāng)然還有很多其他的處理方法,閾值處理只是最簡單實用的方法。
6 去除圖像中的黑點
圖像中有許多雜散的黑暗像素作為干擾因子。循環(huán)遍歷圖像矩陣,如果相鄰像素是白色的,并且與相鄰像素相對的像素也是白色的,而中心像素是黑色的,則設(shè)定中心像素為白色。
- for column in range(1, image.height - 1):
- for row in range(1, image.width - 1):
- if pi xel_matrix[row, column] == 0 and pixel_matrix[row, column - 1] == 255 and
- pixel_matrix[row, column + 1] == 255:
- pixel_matrix[row, column] = 255
- if pi xel_matrix[row, column] == 0 and pixel_matrix[row - 1, column] == 255 and
- pixel_matrix[row + 1, column] == 255:
- pixel_matrix[row, column] = 25
處理后的結(jié)果如圖14所示。

圖14 處理后的結(jié)果
經(jīng)過以上步驟的處理,圖像已經(jīng)只剩下字符框架了。雖然有些字符已經(jīng)丟失了一些基礎(chǔ)像 素,但是每個字符的圖像骨架基本上都完備。當(dāng)然這個是必需的,我們進(jìn)行這么多處理的主要 目的就是為每個可能的字符都截取生成合適的字符圖。
7 構(gòu)建字符圖庫
將上述算法裁剪得到的所有字符圖像都存儲于文件夾下。下一個任務(wù)是為屬于“ A-Z0-9” 的每個字符找到至少一個樣本圖像(如圖15所示)。這一步就像“訓(xùn)練”步驟,手動為每個 字符選擇了一個字符圖像并對其更名。

圖15 樣本圖像
8 選擇最優(yōu)的字符圖
運行其他幾個腳本,以確保每個字符的圖像中都有最佳的圖像,例如,如果有 20 個“ A” 的字符圖像,那么暗色數(shù)量最少的圖像顯然是噪聲最少的圖像,因此最適合作為骨架圖像。選擇的原則如下:
1)一個按照字符排序的相似圖像(約束條件:黑色像素數(shù)量大小,并且相似度 > = 90%~95%)。
2)一個從每個分組字符獲得的最佳圖像。因此,到目前為止,我們生成了一個像素圖像庫。我們將其轉(zhuǎn)換為像素矩陣,并將位圖字符圖轉(zhuǎn)為數(shù)字點陣 JSON 文件。
9 識別算法
最后是獲取任何新的驗證碼圖像的算法:使用相同的算法盡量減少新圖像中不必要的干擾因子。對于新驗證碼圖片中的每個字符,強(qiáng)制通過與生成的 JSON 文件的像素矩陣來匹配,基 于相應(yīng)的黑色像素匹配來計算相似度。如果一個像素是黑色的,其在圖像中的位置恰好是待破 解的驗證碼,并且此像素位于字符庫中的骨架圖像 / 位圖內(nèi)的相同位置處,則計數(shù)會遞增 1。與骨架圖像中黑色像素的數(shù)量進(jìn)行對比,計算匹配百分比,選擇具有最高匹配百分比的字符就是識別結(jié)果的字符。
最終結(jié)果如圖16所示,若得到的字符為 Z5M3MQ,則驗證碼被成功識別出來了。

圖16 識別結(jié)果