尋找阿登高地——爬蟲工程師如何繞過驗證碼
馬奇諾防線是二戰前法國耗時十余年修建的防御工事,十分堅固,但是由于造價昂貴,僅修建了法德邊境部分,綿延數百公里,而法比邊界的阿登高地地形崎嶇,不易運動作戰,且比利時反對在該邊界修建防線,固法軍再次并沒過多防備,滿心期望能夠依靠堅固的馬奇諾防線來阻擋德軍的攻勢。沒想到后來德軍避開德法邊境正面,通過阿登高地從防線左翼迂回,繞過了馬奇諾防線,然后就是英法聯軍的敦克爾克大撤退了。
網站驗證碼就如同馬奇諾防線一樣,阻擋了爬蟲工程師的正面進攻。
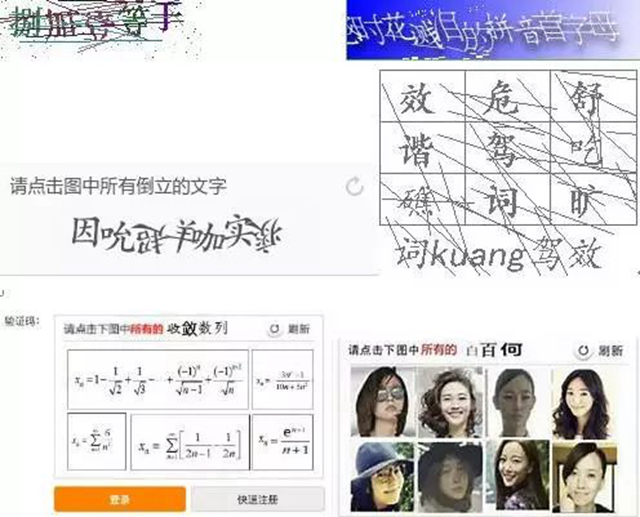
隨著爬蟲和反爬蟲雙方圍繞驗證碼的不斷較量,最終導致了驗證碼識別難度的不斷上升。現在復雜的驗證碼長這樣:
面硬剛驗證碼,想要識別它,是件挺復雜的事,涉及到圖像處理技術:二值化,降噪,切割,字符識別算法:KNN(K鄰近算法)和SVM (支持向量機算法),再復雜點還要借助CNN(卷積神經網絡),還有什么機器學習啥的。
雖然現在有打碼平臺可以解決絕大多數的驗證碼問題,但如果爬取的數量特別龐大,單純依賴打碼平臺也是不大行得通的,除了成本因素,還有打碼平臺也解決不了的驗證碼因素,比如滑動驗證碼:
既然正面進攻費事費力,那能不能找到爬蟲工程師眼中的阿登高地繞過驗證碼呢?
本文以各地工商網站為例,對常見的驗證碼繞過技巧做一個小總結,順便解密下如何不借助模擬js拖動來繞過滑動驗證碼。
各地工商網站(全稱國家企業信用信息公示系統)因為包含大量企業真實信息,金融貸款征信等都用得到,天然吸引了很大部分來自爬蟲的火力,因此反爬蟲措施格外嚴格。一般的網站僅在登錄注冊等環節,或者訪問頻繁后才彈出驗證碼,而工商網站查詢無需登錄,每查一次關鍵字就需要一次驗證碼。同時各地工商網站由于各自獨立開發,自主采用了各種不同的驗證碼機制,更是給全量爬取的爬蟲增加了更多的障礙。因此,工商網站的驗證碼特別具有代表性。
首先,從最簡單的分頁角度入手。
分頁的處理可以放在前端也可以放在后端,如果只放在后端,每次點擊頁碼就需要發送一次查詢請求,而一次驗證碼通常只能服務于一次請求,再次請求需要獲取新的驗證碼,直接觀察翻頁操作是否彈出驗證碼輸入框即可判斷是否可以繞過。
如何判斷分頁處理放在前端還是后端的呢?很簡單,F12打開瀏覽器開發者工具,頁面點下一頁,有新的請求就說明放在后端,反之就是前端。
實踐發現,四川和上海的工商網站翻頁都放在后端,且翻頁沒有驗證碼輸入框。說明這里的驗證碼可以繞過,但是繞過的原理卻有些不同:
對比四川工商網站翻頁前后請求的參數,除了頁碼參數外,多了一項:yzmYesOrNo=no。從變量名也猜得到,后端根據該參數的值判斷是否需要檢查驗證碼。
而上海工商網站的對比結果發現,除了頁碼參數外,少了驗證碼字段,因此我們可以大膽猜測:驗證碼的校驗僅放在了前端,后端沒有做二次校驗,從頁面上操作是繞不過的,但是不帶驗證碼字段直接向后端發送請求,數據就拿到了。
嚴格來說,上海工商網站這種算是漏洞,對待這種這種漏洞,爬蟲工程師應有的態度是:悄悄的進村,打槍的不要。不過也不要利用的太狠了,筆者實驗時沒加限制,爬了十萬數據后,ip被封了。很長時間后才解封,同時頁面改版并修復了漏洞。
其次,觀察目標網站是否有多套驗證碼。
有些網站不知道出于什么樣的考慮,會在不同的頁面使用不同的驗證碼。一旦遇到這種情況,我們可就要撿軟柿子捏了–從簡單的驗證碼入手,移花接木,將識別的結果作為參數來向后端發送請求,從而達到繞過復雜驗證碼的目的。
舉例來說,湖北工商的查詢頁面驗證碼是類似下圖的九宮格驗證碼:
而電子營業執照登陸界面的驗證碼是這樣的:
即便要識別,也明顯是后者的驗證碼要容易些,實例代碼如下:
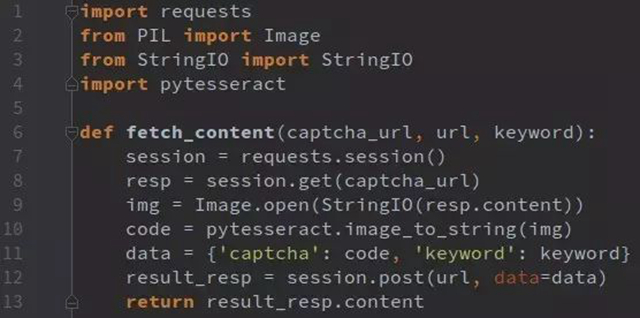
再者,可以考慮從數據的存儲id入手
專門針對移動端開發的wap頁面限制一般要少得多。以北京工商網站來說,wap界面不帶驗證碼參數直接發送請求就可以得到數據的,原理類似于上海工商網站,但是其對單個ip日訪問次數做了嚴格限制,因此該方式可以用但不好用。
繼續觀察,以搜索“山水集團”為例,從搜索頁到列表頁時,需要輸入驗證碼,而從列表頁進入詳情頁的時候,是不需要驗證碼的。最終詳情頁如圖:

通常沒人記得住各地工商網站的網址,我們會去搜索引擎里搜。當搜北京企業信用信息時,發現兩個有價值的結果,除了國家企業信用信息公示系統外,還有個北京市企業信用信息信息網。進后者再操作一番可以得到下面的詳情頁:
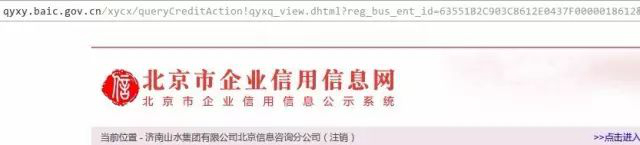
觀察發現,企業id都是相同的,嘿嘿,這不是“兩塊牌子,一套班子”嘛!后者的訪問量要小一些,雖有驗證碼,但是可以采用上海工商一樣的方式繞過,只是返回的結果字段不太符合我們的要求。不過,我們可以去企業信息網獲得企業id,再次采用移花接木的方式,去信息公示系統構造鏈接獲得最終的詳情頁嘛!
用過數據庫同學都曉得,數據庫里的數據id,默認是自增的。如果有個網站引用的數據是xxx.com?id=1234567, 那我們很容易猜得到構造類似1234568這樣的id去嘗試!通常,使用這種id規律能夠輕易猜出來的網站并不多,但不代表沒有。比如甘肅省工商網站,結果頁是拿企業注冊號來查詢的。
***,談談滑動驗證碼。
目前,工商網站已經全面改版,全部采用了滑動驗證碼,上面絕大多數思路都失效了。對于滑動驗證碼,網上能搜到的解決方案基本都是下載圖片,還原圖片,算出滑動距離,然后模擬js來進行拖動解決,我們來看下能否不模擬拖動來解決這個問題。
以云南工商網站為例,首先抓包看過程。
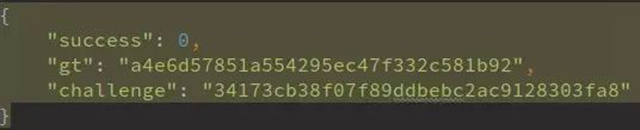
1. http://yn.gsxt.gov.cn/notice/pc-geetest/register?t=147991678609,response:
2. 下載驗證碼圖片

3. http://yn.gsxt.gov.cn/notice/pc-geetest/validate, post如下數據:

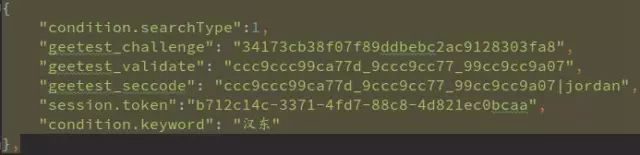
4. http://yn.gsxt.gov.cn/notice/search/ent_info_list,post如下數據:
仔細分析,我們發現兩處疑點:
1. ***步并沒有返回需要下載的圖片地址,那么前端怎么知道要下載哪些圖片?
2. 第三步驗證時,并沒有告知后端下載了那些圖片,后端是怎么驗證post過去的數據是有效性的?
仔細閱讀前端混淆的js代碼,我們發現前端數據處理過程是這樣的:
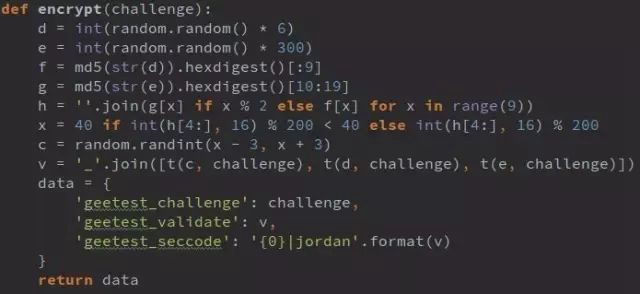
1. 從0到6(不含)中取隨機整數,賦值給d, d=5;
2. 從0到300(不含)中取隨機整數,賦值給e, e=293;
3. 將d轉化為字符串并作MD5加密,加密字符串取前9位賦值給f, f=’e4da3b7fb’;
4. 將e轉化為字符串并作MD5加密,加密字符串從第11位開始取9位賦值給g, g=’43be4f209’;
5. 取f的偶數位和g的奇數位組成新的9位字符串給h, h=’e3de3f70b’;
6. 取h的后4位與200做MOD運算,其結果小于40,則取40,否則取其本身賦值給x,x=51;
7. 取[x-3, x+3]以內隨機數賦值給c,c=51;
8. 分別取c,d,e跟challenge做t加密(t(c,challenge), t(d, challenge), t(e,challenge))并用(_)拼接即為geetest_validate, ‘9ccccc997288_999c9ccaa83_999cc9c9999990d’
這里f, g參數決定了下載圖片地址:

而x為滑塊拖動的橫向偏移量,至此解答了疑問1中圖片下載地址怎么來的問題。
前邊提到的t加密過程是這樣的:
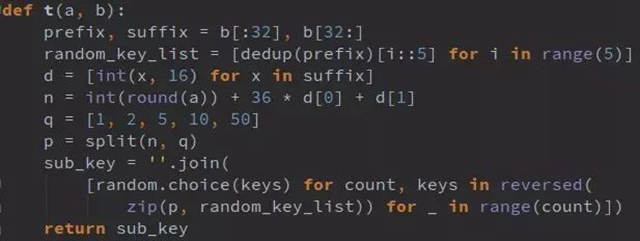
t(a,b),此處以a=51演示
1. challenge為34位16進制字符串,取前32位賦值給prefix,后2位賦值給suffix,prefix=’34173cb38f07f89ddbebc2ac9128303f’, suffix=’a8′
2. prefix去重并保持原順序,得到列表 [‘3’, ‘4’, ‘1’, ‘7’, ‘c’, ‘b’, ‘8’, ‘f’, ‘0’, ‘9’, ‘d’, ‘e’, ‘2’, ‘a’]
3. 將2中列表循環順序放入包含5個子列表的列表中,得到random_key_list: [[‘3’, ‘b’, ‘d’], [‘4’, ‘8’, ‘e’], [‘1’, ‘f’, ‘2’], [‘7’, ‘0’, ‘a’], [‘c’, ‘9’]]
4. 將suffix字符串(16進制)逐位轉化為10進制,得到[10, 8]
6. 將4中列表逐位與[36,0]做乘法和運算并與a的四舍五入結果相加, n= 51 + 36*10 + 0*8=419
7. q=[1,2,5,10,50], 用q對n做分解(n=50*13+10*0+5*1+2*1+1*1),將其因數倒序賦值給p,p=[0,2,1,1,8]
8. 從random_key_list右側開始隨機取值,次數為p中數值,拼成字符串sub_key,sub_key=’9ccccc997288′
至此,我們完成了整個分析過程,我們又有了新發現:
1. 按照前邊的抓***程,其實不需要真的下載圖片,只需執行1、3、4步就可以得到目標數據了。步驟1也可以不要,只需3、4即可,但是少了步驟1, 我們還需要額外請求一次cookie,所以還是保留1, 這樣也偽裝的像一點嘛。
2. 相同的challenge,每次運算都可以得出不同的validate和seccode,那么問題來了:到底服務端是怎么根據challenge驗證其他數據是否有效呢?
總結一下,對于驗證碼,本文只是提供了一種新的思路,利用了網站開發過程中的一點小疏漏,而***的滑動驗證碼也只是分析了offline模式的驗證方法。不要指望所有驗證碼都可以能繞過,沒有阿登高地,二戰德國就不打法國了么?只要覺得有價值,即使正面面對驗證碼,作為爬蟲工程師建議也就一句話:不要慫,就是干!