幾種特征選擇方法的比較,孰好孰壞?
本文轉載自微信公眾號「數據STUDIO」,作者云朵君。轉載本文請聯系數據STUDIO公眾號。
在本文中,重點介紹特征選擇方法基于評估機器學習模型的特征重要性在各種不可解釋(黑盒)及可解釋機器學習方法上的表現。比較了CART、Optimal Trees、XGBoost和SHAP正確識別相關特征子集的能力。
無論使用原生特征重要性方法還是SHAP、 XGBoost都不能清晰地區分相關和不相關的特征。而可解釋方法(interpretable methods)能夠正確有效地識別無關特征,從而為特征選擇提供了顯著的良好的性能。
特征選擇
在物聯網的時代,每天都在以越來越快的速度創建和收集數據,這導致與每個數據點相關的數據集具有成千上萬的特征。雖然眾多機器學習和人工智方法能都擁有強大的預測能力,但在這種高維數據集中,模型在理解各種特征的相對質量時,也會變得很復雜。事實上,在訓練模型時并不需要用到所有的高維數據集,而運用其中一小部分特征來訓練模型也可以得到大部分或所有的預測性能。
特征選擇(feature selection)從所有的特征中,選擇出意義的,對模型有幫助的特征,以避免必須將所有特征都導入模型中去訓練的情況。
我們一般有四種方法可以選擇:過濾法、嵌入法、包裝法和降維法。其中包裝法和嵌入法都是依賴于依賴于算法自身的選擇,即基于評估機器學習模型的特征重要性,根據重要性分數了解哪些特征與做出預測最相關的方法。這也是最常用的特征選擇方法之一。
特征選擇的重要性并不需要過多描述,因此由模型計算出的重要性分數能否反映實際情況是至關重要的。錯誤地高估不相關特征的重要性會導致錯誤的發現,而低估相關特征的重要性會導致我們丟棄重要的特征,從而導致模型性能較差。
此外,像XGBoost這樣的黑盒模型提供了更加先進的預測性能,但人類并不容易理解其內在原理,因需要依賴于特征重要性分數或SHAP之類的可解釋性方法來研究他們對特征選擇的行為。
基于評估器計算特征重要性原理
前面已經說過最常用的特征選擇方法之一是基于評估機器學習模型的特征重要性,而評估機器學習模型試圖量化每個特征的相對重要性,以預測目標變量。特征重要性的計算方式是通過度量模型中每個特性的使用所帶來的性能增量改進來,并在整個模型中總結這些信息。我們可以使用它來識別那些被認為很少或不重要的特性,并將它們從模型中刪除。
不足之處:任何特征選擇的方法只有在它也是準確的時候才有用。
CART樹特征選擇的優缺點
基于樹的模型是機器學習中最常用的方法之一,因為它們的能力和可解釋性。CART等單樹模型是完全可解釋的,因為可以很容易地通過觀察最終決策樹中的分割來遵循它們的預測邏輯。
然而,CART是使用每次形成一個分割的樹的貪婪啟發式方法進行訓練模型的,這種方法會產生許多缺點。
- 首先,這可能導致樹遠不是全局最優的,因為貪婪啟發式中任何給定點上的最佳分割,這已被證明在樹的未來生長環境中并不是最佳的選擇。
- 其次,由于CART算法采用每一步都窮盡搜索所有特征來拆分選擇方法,所以傾向于選擇拆分點較多的特征。由于特征的選擇很可能會偏向那些具有大量唯一值的特征,而貪婪算法可能導致在樹根附近的被用于分割數據的特征選擇錯誤,而這些特征往往是最重要的。
基于樹的集成學習器
基于樹的集成方法,如隨機森林和梯度增強(如XGBoost),通過集成大量單樹模型的預測來改進CART的性能。這樣確實帶來了更為先進的性能,但犧牲了模型的可解釋性,因為人類幾乎不可能理解成百上千的樹模型之間的交互及其他行為。因此,通常需要依賴可變重要性方法來理解和解釋這些模型的工作機制。
這些模型在計算特征重要性時,可能會存在一定的敏感性,尤其對具有很多潛在分裂點的特征,及特征中包含一些易形成偏倚問題的數據。
SHAP
SHAP是一種最新的方法,它統一了許多早期的方法,旨在解決集成樹模型中的偏倚問題,并使用博弈論方法來理解和解釋每個特性是如何驅動最終預測的。SHAP因為它的魯棒性和解決偏差問題,迅速被廣泛用于解釋黑箱模型和進行特征選擇。
最優樹
如前所述,與集成方法相比,CART的預測性能較差,但集成方法被迫犧牲單個決策樹的可解釋性來實現較好的預測性能,這使得從業者不得不在性能和可解釋性之間進行選擇。
最優樹利用混合整數優化在單步構造全局最優決策樹。所得到的模型不僅保持了單個決策樹的可解釋性,又能達到黑盒模型一樣的高性能。
由于該方法考慮同時優化樹中的所有分割,而不是貪婪地一個一個地優化,我們可以預期分割選擇,不像CART那樣容易受到同樣的偏倚問題的影響。
對比結果
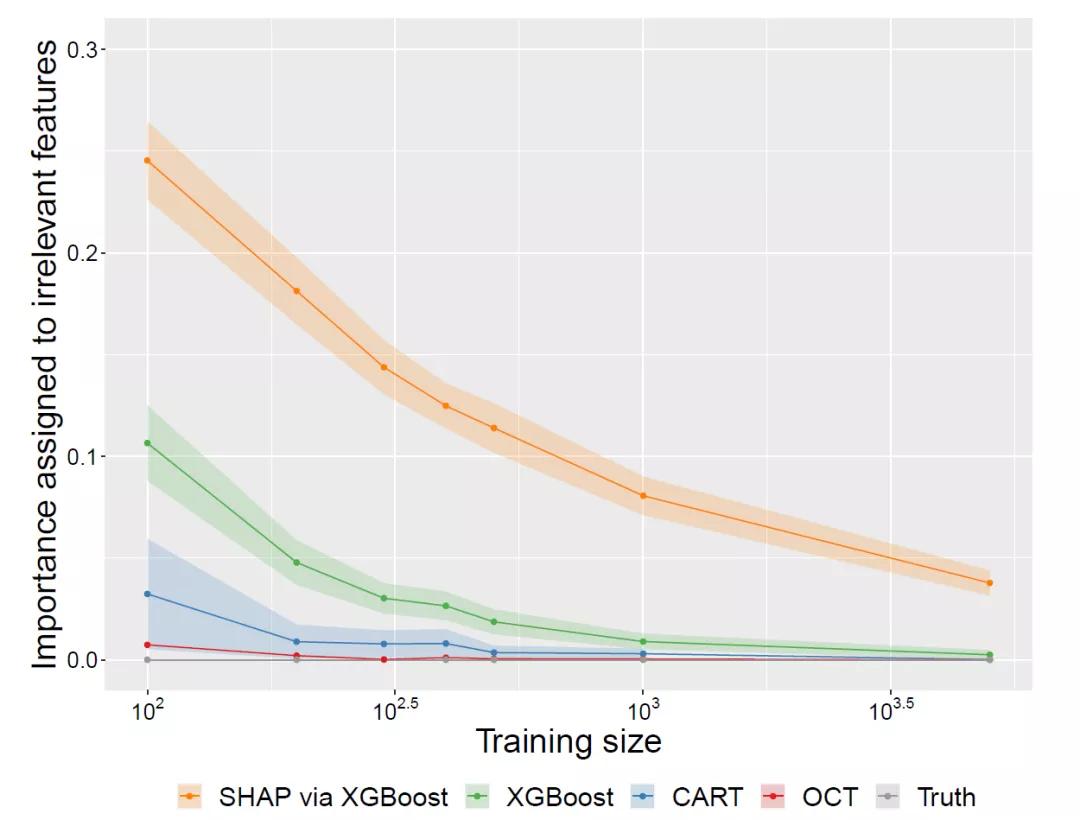
SHAP和XGBoost一直低估關鍵特征的重要性,而將不相關的特征賦予顯著的重要性,并且在較高的噪聲下無法完全區分相關與不相關的特征。顯然這些不能被用于特征選擇或解釋,否則這將會發生嚴重的后果。
另一方面,可解釋的單樹模型在識別與預測無關的特征方面優勢突出,在需要相對較少的訓練數據的情況下將其重要性降至零。
相對于CART樹,最優樹注重全局優化,因而其識別無關特征的速度更快以及對特征選擇的偏倚問題的敏感性更低。
可解釋的單樹模型在消除無關特征方面是完全透明和有效的;在使用最優樹時,通常以很少甚至沒有性能代價就能完成消除無關特征。
參考:
Comparing interpretability and explainability for feature selection
Interpretable AI Cambridge, MA 02142,Jack Dunn etc.