最喜歡隨機森林?TensorFlow開源決策森林庫TF-DF
在人工智能發展史上,各類算法可謂層出不窮。近十幾年來,深層神經網絡的發展在機器學習領域取得了顯著進展。通過構建分層或「深層」結構,模型能夠在有監督或無監督的環境下從原始數據中學習良好的表征,這被認為是其成功的關鍵因素。
而深度森林,是 AI 領域重要的研究方向之一。
2017 年,周志華和馮霽等人提出了深度森林框架,這是首次嘗試使用樹集成來構建多層模型的工作。2018 年,周志華等人又在研究《Multi-Layered Gradient Boosting Decision Trees》中探索了多層的決策樹。今年 2 月,周志華團隊開源深度森林軟件包 DF21:訓練效率高、超參數少,在普通設備就能運行。
就在近日,TensorFlow 開源了 TensorFlow 決策森林 (TF-DF)。TF-DF 是用于訓練、服務和解釋決策森林模型(包括隨機森林和梯度增強樹)生產方面的 SOTA 算法集合。現在,你可以使用這些模型進行分類、回歸和排序任務,具有 TensorFlow 和 Keras 的靈活性和可組合性。
谷歌大腦研究員、Keras之父François Chollet表示:「現在可以用Keras API訓練TensorFlow決策森林了。」

對于這一開源項目,網友表示:「這非常酷!隨機森林是我最喜歡的模型。」

決策森林
決策森林是一系列機器學習算法,其質量和速度可與神經網絡相競爭(它比神經網絡更易于使用,功能也很強大),實際上與特定類型的數據配合使用時,它們比神經網絡更出色,尤其是在處理表格數據時。
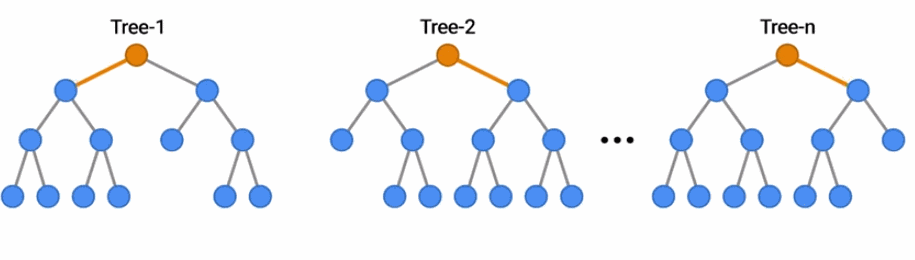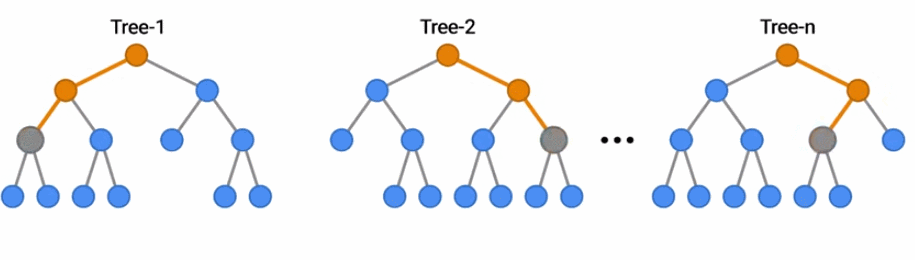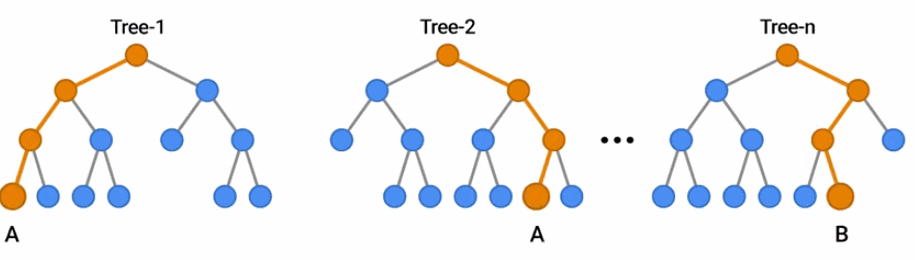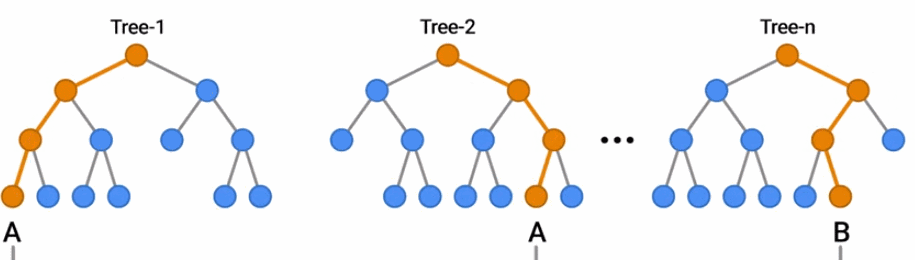
隨機森林是一種流行的決策森林模型。在這里,你可以看到一群樹通過投票結果對一個例子進行分類。
決策森林是由許多決策樹構建的,它包括隨機森林和梯度提升樹等。這使得它們易于使用和理解,而且可以利用已經存在的大量可解釋性工具和技術進行操作。
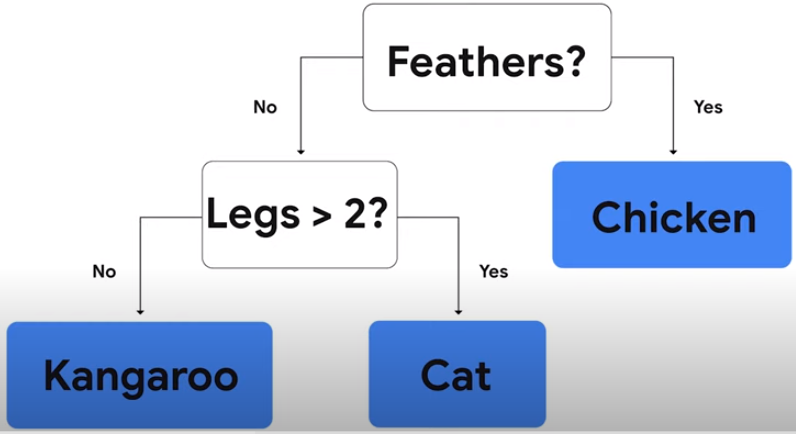
決策樹是一系列僅需做出是 / 否判斷的問題,使用決策樹將動物分成雞、貓、袋鼠。
TF-DF 為 TensorFlow 用戶帶來了模型和一套定制工具:
- 對初學者來說,開發和解釋決策森林模型更容易。不需要顯式地列出或預處理輸入特征(因為決策森林可以自然地處理數字和分類屬性)、指定體系架構(例如,通過嘗試不同的層組合,就像在神經網絡中一樣),或者擔心模型發散。一旦你的模型經過訓練,你就可以直接繪制它或者用易于解釋的統計數據來分析它。
- 高級用戶將受益于推理時間非常快的模型(在許多情況下,每個示例的推理時間為亞微秒)。而且,這個庫為模型實驗和研究提供了大量的可組合性。特別是,將神經網絡和決策森林相結合是很容易的。

如上圖所示,只需使用一行代碼就能構建模型,相比之下,動圖中的下面代碼是用于構建神經網絡的代碼。在 TensorFlow 中,決策森林和神經網絡都使用 Keras。可以使用相同的 API 來實驗不同類型的模型,更重要的是,可以使用相同的工具,例如 TensorFlow Serving 來部署這兩種模型。
以下是 TF-DF 提供的一些功能:
- TF-DF 提供了一系列 SOTA 決策森林訓練和服務算法,如隨機森林、CART、(Lambda)MART、DART 等。
- 基于樹的模型與各種 TensorFlow 工具、庫和平臺(如 TFX)更容易集成,TF-DF 庫可以作為通向豐富 TensorFlow 生態系統的橋梁。
- 對于神經網絡用戶,你可以使用決策森林這種簡單的方式開始 TensorFlow,并繼續探索神經網絡。
代碼示例
下面進行示例展示,可以讓使用者簡單明了。
項目地址:https://github.com/tensorflow/decision-forests
- TF-DF 網站地址:https://www.tensorflow.org/decision_forests
- Google I/O 2021 地址:https://www.youtube.com/watch?v=5qgk9QJ4rdQ
模型訓練
在數據集 Palmer's Penguins 上訓練隨機森林模型。目的是根據一種動物的特征來預測它的種類。該數據集包含數值和類別特性,并存儲為 csv 文件。

Palmer's Penguins 數據集示例。
模型訓練代碼:
- # Install TensorFlow Decision Forests
- !pip install tensorflow_decision_forests
- # Load TensorFlow Decision Forests
- import tensorflow_decision_forests as tfdf
- # Load the training dataset using pandas
- import pandas
- train_df = pandas.read_csv("penguins_train.csv")
- # Convert the pandas dataframe into a TensorFlow dataset
- train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="species")
- # Train the model
- model = tfdf.keras.RandomForestModel()
- model.fit(train_ds)
請注意,代碼中沒有提供輸入特性或超參數。這意味著,TensorFlow 決策森林將自動檢測此數據集中的輸入特征,并對所有超參數使用默認值。
評估模型
現在開始對模型的質量進行評估:
- # Load the testing dataset
- test_df = pandas.read_csv("penguins_test.csv")
- # Convert it to a TensorFlow dataset
- test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="species")
- # Evaluate the model
- model.compile(metrics=["accuracy"])
- print(model.evaluate(test_ds))
- # >> 0.979311
- # Note: Cross-validation would be more suited on this small dataset.
- # See also the "Out-of-bag evaluation" below.
- # Export the model to a TensorFlow SavedModel
- model.save("project/my_first_model")
帶有默認超參數的隨機森林模型為大多數問題提供了一個快速和良好的基線。決策森林一般會對中小尺度問題進行快速訓練,與其他許多類型的模型相比,需要較少的超參數調優,并且通常會提供強大的結果。
解讀模型
現在,你已經了解了所訓練模型的準確率,接下來該考慮它的可解釋性了。如果你希望理解和解讀正被建模的現象、調試模型或者開始信任其決策,可解釋性就變得非常重要了。如上所述,有大量的工具可用來解讀所訓練的模型。首先從 plot 開始:
- tfdf.model_plotter.plot_model_in_colab(model, tree_idx=0)

其中一棵決策樹的結構。
你可以直觀地看到樹結構。此外,模型統計是對 plot 的補充,統計示例包括:
- 每個特性使用了多少次?
- 模型訓練的速度有多快(樹的數量和時間)?
- 節點在樹結構中是如何分布的(比如大多數 branch 的長度)?
這些問題的答案以及更多類似查詢的答案都包含在模型概要中,并可以在模型檢查器中訪問。
- # Print all the available information about the model
- model.summary()
- >> Input Features (7):
- >> bill_depth_mm
- >> bill_length_mm
- >> body_mass_g>>
- ...
- >> Variable Importance:
- >> 1. "bill_length_mm" 653.000000 ################
- >> ...
- >> Out-of-bag evaluation: accuracy:0.964602 logloss:0.102378
- >> Number of trees: 300
- >> Total number of nodes: 4170
- >> ...
- # Get feature importance as a array
- model.make_inspector().variable_importances()["MEAN_DECREASE_IN_ACCURACY"]
- >> [("flipper_length_mm", 0.149),
- >> ("bill_length_mm", 0.096),
- >> ("bill_depth_mm", 0.025),
- >> ("body_mass_g", 0.018),
- >> ("island", 0.012)]
在上述示例中,模型通過默認超參數值進行訓練。作為首個解決方案而言非常好,但是調整超參數可以進一步提升模型的質量。可以如下這樣做:
- # List all the other available learning algorithms
- tfdf.keras.get_all_models()
- >> [tensorflow_decision_forests.keras.RandomForestModel,
- >> tensorflow_decision_forests.keras.GradientBoostedTreesModel,
- >> tensorflow_decision_forests.keras.CartModel]
- # Display the hyper-parameters of the Gradient Boosted Trees model
- ? tfdf.keras.GradientBoostedTreesModel
- >> A GBT (Gradient Boosted [Decision] Tree) is a set of shallow decision trees trained sequentially. Each tree is trained to predict and then "correct" for the errors of the previously trained trees (more precisely each tree predicts the gradient of the loss relative to the model output)..
- ...
- Attributes:
- num_trees: num_trees: Maximum number of decision trees. The effective number of trained trees can be smaller if early stopping is enabled. Default: 300.
- max_depth: Maximum depth of the tree. `max_depth=1` means that all trees will be roots. Negative values are ignored. Default: 6.
- ...
- # Create another model with specified hyper-parameters
- model = tfdf.keras.GradientBoostedTreesModel(
- num_trees=500,
- growing_strategy="BEST_FIRST_GLOBAL",
- max_depth=8,
- split_axis="SPARSE_OBLIQUE"
- ,)
- # Evaluate the model
- model.compile(metrics=["accuracy"])
- print(model.evaluate(test_ds))#
- >> 0.986851