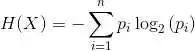Apache Spark中的決策樹
Apache Spark中的決策樹
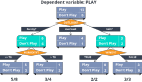
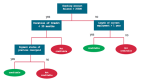
決策樹是在順序決策問題進行分類,預測和促進決策的有效方法。決策樹由兩部分組成:
- 決策(Desion)
- 結果(Outcome)
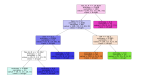
決策樹包含三種類型的節點:
- 根節點(Root node):包含所有數據的樹的頂層節點。
- 分割節點(Splitting node):將數據分配給子組(subgroup)的節點。
- 終端節點(Terminal node):最終決定(即結果)。
(分割節點(Splitting node),僅就離散數學中的樹的概念而言,就是指分支節點,下面的翻譯為了強調"分支"有時會翻譯成分支結點,譯者注)
為了抵達終端結點或者說獲得結果,該過程從根節點開始。根據在根節點上做出的決定,選擇分支節點。基于在分支節點上做出的決定,選擇下一個子分支節點。這個過程繼續下去,直到我們到達終端節點,終端節點的值是我們的結果。
Apache Spark中的決策樹
Apache Spark中沒有決策樹的實現可能聽起來很奇怪。然而從技術上來說是有的。在Apache Spark中,您可以找到一個隨機森林算法的實現,該算法實現可以由用戶指定樹的數量。因此,Apache Spark使用一棵樹來調用隨機森林。
在Apache Spark中,決策樹是在特征空間上執行遞歸二進制分割的貪婪算法。樹給每個***部(即葉子結點)分區預測了相同的標簽。為了***化樹的節點處的信息增益,通過在一組可能的分支中選擇其中的***分割來貪婪地選擇每個分支結點。
節點不純度(impurity)是節點上標簽一致性的度量。目前的實施提供了兩種不純的分類方法(Gini雜質和熵(Gini impurity and entropy))。

停止規則
在滿足以下列條件之一的情況下,在節點處停止遞歸樹構建(即只要滿足一個就停止,譯者注):
- 節點深度等于訓練用的 maxDepth 參數。
- 沒有候選的分割結點導致信息收益大于 minInfoGain 。
- 沒有候選的分割結點去產生(至少擁有訓練minInstancesPerNode實例)的子節點 。
有用的參數
- algo:它可以是分類或回歸。
- numClasses:分類類的數量。
- maxDepth:根據節點定義樹的深度。
- minInstancesPerNode:對于要進一步拆分的節點,其每個子節點必須至少接收到這樣的訓練實例數(即實例數必須等于這個參數)。
- minInfoGain:對于一個節點進一步拆分,必須滿足拆分后至少提高這么多信息量。
- maxBins:離散連續特征時使用的bin數。
準備決策樹的訓練數據
您不能直接向決策樹提供任何數據。它需要一種特殊的格式來提供。您可以使用 HashingTF 技術將訓練數據轉換為標記數據,以便決策樹可以理解。這個過程也被稱為數據的標準化。
(數據)供給和獲得結果
一旦數據被標準化,您就可以提供相同的決策樹算法進來行分類。但在此之前,您需要分割數據以用于訓練和測試目的; 為了測試的準確性,你需要保留一部分數據進行測試。你可以像這樣提供數據:
- al splits = data.randomSplit(Array(0.7, 0.3))
- val (trainingData, testData) = (splits(0), splits(1))
- // Train a DecisionTree model.
- // Empty categoricalFeaturesInfo indicates all features are continuous.
- val numClasses = 2
- val categoricalFeaturesInfo = Map[Int, Int]()
- val impurity = "gini"
- val maxDepth = 5
- val maxBins = 32
- val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
- impurity, maxDepth, maxBins)
在這里,數據是我的標準化輸入數據,為了訓練和測試目的,我將其分成7:3的比例。我們正在使用***深度的為5的"gini" 雜質("gini" impurity)。
一旦模型生成,您也可以嘗試預測其他數據的分類。但在此之前,我們需要驗證最近生成的模型的分類準確性。您可以通過計算"test error"來驗證其準確性。
- / Evaluate model on test instances and compute test error
- val labelAndPreds = testData.map { point =>
- val prediction = model.predict(point.features)
- (point.label, prediction)
- }
- val testErr = labelAndPreds.filter(r => r._1 != r._2).count().toDouble / testData.count()
- println("Test Error = " + testErr)
就是這樣!你可以在這里查看一個正在運行的例子。