













AI識圖驢唇不對馬嘴?Google AI:用交錯訓練集提升圖像描述準確性
如果一張圖片可以用一千個單詞描述,那么圖片中所能被描繪的對象之間便有如此多的細節(jié)和關系。我們可以描述狗皮毛的質(zhì)地,要被追逐的飛盤上的商標,剛剛?cè)舆^飛盤的人臉上的表情,等等。
現(xiàn)階段,包含文本描述及其相應圖像的描述的數(shù)據(jù)集(例如MS-COCO和Flickr30k)已被廣泛用于學習對齊的圖像和文本表示并建立描述模型。
然而,這些數(shù)據(jù)集的跨模態(tài)關聯(lián)有限:圖像未與其他圖像匹配,描述僅與同一張圖片的其他描述匹配,存在圖像與描述的匹配但未被標記為匹配項,并且沒有標簽標明何時圖像與描述之間是不匹配的。
為了彌補這一評估空白,我們提出了「交叉描述:針對MS-COCO的擴展的模內(nèi)和模態(tài)語義相似性判斷」。
縱橫交錯描述(CxC)數(shù)據(jù)集使用圖像-文本,文本-文本和圖像-圖像對的語義相似性評級擴展了MS-COCO的開發(fā)和測試范圍。
評級標準基于「語義文本相似性」,這是一種在短文本對之間廣泛存在的語義相關性度量,我們還將其擴展為包括對圖像的判斷。我們已經(jīng)發(fā)布了CxC的評分以及將CxC與現(xiàn)有MS-COCO數(shù)據(jù)合并的代碼。
創(chuàng)建CxC數(shù)據(jù)集
CxC數(shù)據(jù)集擴展了MS-COCO評估拆分,并在模態(tài)內(nèi)和模態(tài)之間具有分級的相似性關聯(lián)。鑒于隨機選擇的圖像和描述匹配的相似性不高,我們提出了一種方法來對項目進行選擇,通過人工評級從而產(chǎn)生一些具有較高相似性的新匹配。為了減少所選匹配對用于查找它們的模型的依賴性,我們引入了一種間接采樣方案,其中我們使用不同的編碼方法對圖像和描述進行編碼,并計算相同模態(tài)項匹配之間的相似度進而生成相似度矩陣。圖像使用Graph-RISE嵌入進行編碼,而描述則使用兩種方法進行編碼-基于GloVe嵌入的通用語句編碼器(USE)和平均單詞袋(BoW)。
由于每個MS-COCO示例都有五個輔助描述,因此我們平均每個輔助描述編碼以創(chuàng)建每個示例的單個表征,從而確保所有描述對都可以映射到圖像。
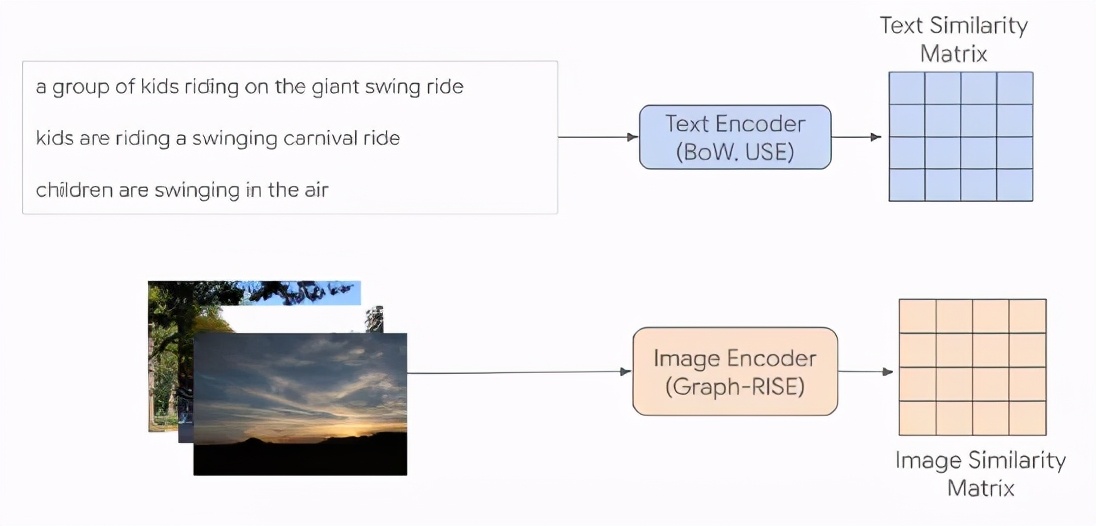
上:使用平均輔助描述編碼構造的文本相似度矩陣(每個單元格對應一個相似度分數(shù)),每個文本條目對應于單個圖像。下:數(shù)據(jù)集中每個圖像的圖像相似度矩陣。
我們從文本相似度矩陣中選擇兩個具有較高計算相似度的描述,然后獲取它們的每個圖像,從而生成一對新的圖像,這些圖像在外觀上不同,但根據(jù)描述的相似。
例如,「一只害羞地向側(cè)面看的狗」和「一只黑狗抬起頭來享受微風」具有相當高的模型相似性,因此下圖中兩只狗的對應圖像 可以選擇圖像相似度等級。此步驟也可以從兩個具有較高計算相似度的圖像開始,以產(chǎn)生一對新的描述。
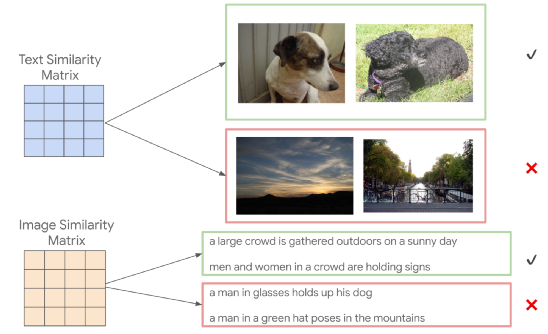
上:根據(jù)描述相似度來選擇圖像匹配。下:根據(jù)描圖像的相似度來選擇描述匹配。
通過使用現(xiàn)有的圖像標題對在模態(tài)之間進行鏈接來做到這一點。例如,如果人對一個描述匹配樣本ij的評級為高度相似,我們從樣本i中選擇圖像,并從樣本j中選擇描述,以獲得一個新的用于人工評級的模態(tài)內(nèi)匹配。然后,我們使用具有最高相似性的模態(tài)內(nèi)對進行采樣,這可以包括一些具有高度相似性的新匹配。






不同相似度的語義圖像相似性(SIS)和語義圖像文本相似性(SITS)示例,其中5為最相似,0為完全不相似。
評估
MS-COCO的匹配是不完整的,因為有時為一幅圖像的描述同樣適用于另一幅圖像,但這些關聯(lián)并未記錄到數(shù)據(jù)集中。CxC使用新的正向匹配增強了這些現(xiàn)有的檢索任務,并且還支持新的圖像-圖像檢索任務。
通過其相似度的評級判斷,CxC還可以測量模型和人工評級之間的相關性。不僅如此,CxC的相關性分數(shù)還考慮相似度的相對順序,其中包括低分項(不匹配項)。
我們進行了一系列實驗,以展示CxC評級的效用。為此,我們使用基于BERT的文本編碼器和使用EfficientNet-B4作為圖像編碼器構造了三個雙編碼器(DE)模型:
1. 文本-文本(DE_T2T)模型,雙方使用共享的文本編碼器。
2. 使用上述文本和圖像編碼器的圖像文本模型(DE_I2T),且在文本編碼器上方有一個用來匹配圖像編碼器輸出的層。
3. 在文本-文本和圖像-文本任務的加權組合上訓練的多任務模型(DE_I2T + T2T)。
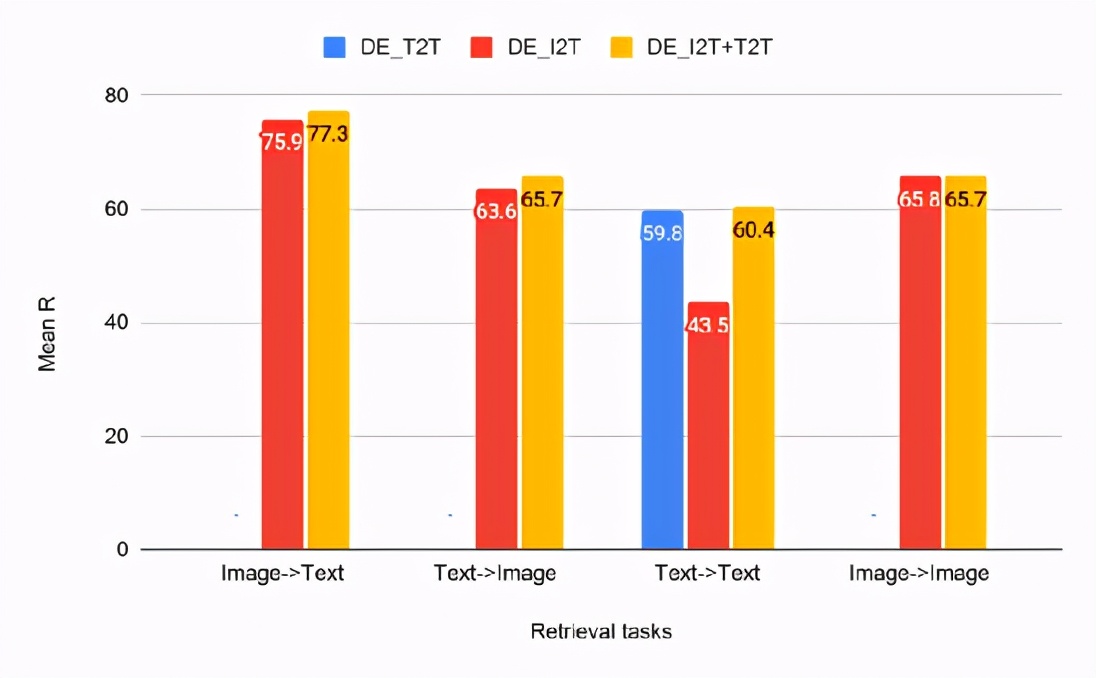
文本-文本(T2T),圖像-文本(I2T)和多任務(I2T + T2T)雙編碼器模型的CxC檢索結果
從檢索任務的結果可以看出,DE_I2T + T2T(黃色條)在圖像文本和文本圖像檢索任務上的性能優(yōu)于DE_I2T(紅色條)。因此,添加模態(tài)內(nèi)(文本-文本)訓練任務有助于提高模態(tài)間(圖像-文本,文本-圖像)性能。
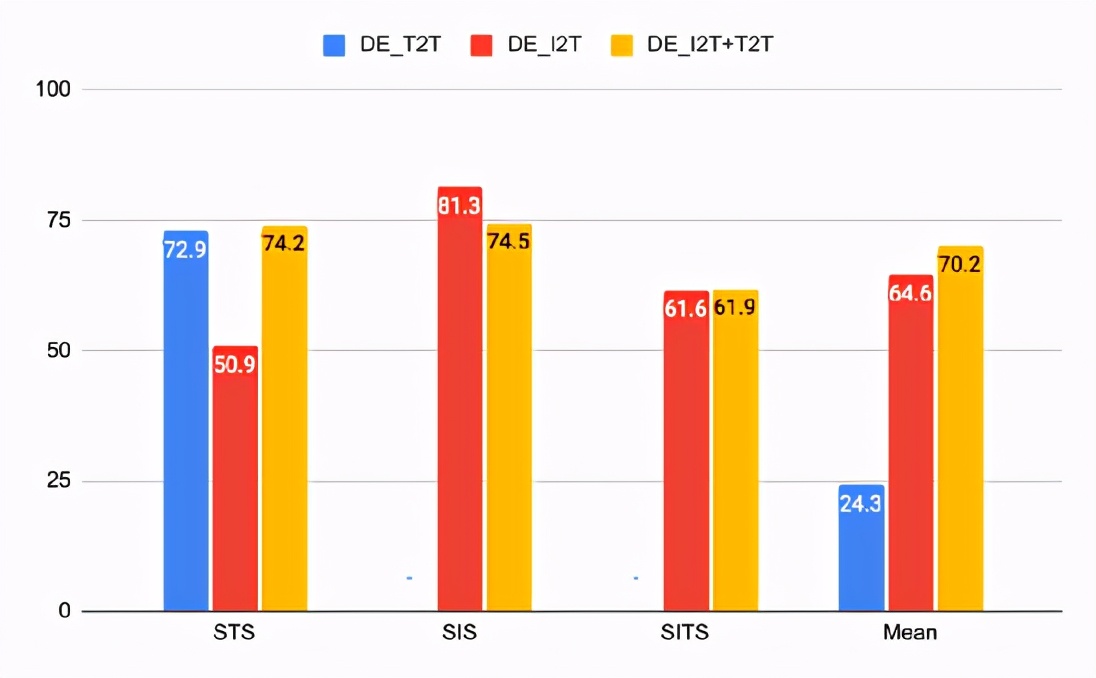
相同模型的CxC相關結果
對于關聯(lián)任務,DE_I2T在SIS上表現(xiàn)最好,而DE_I2T + T2T在總體上是最好的。相關分數(shù)還顯示DE_I2T僅在圖像上表現(xiàn)良好:它具有最高的SIS,但具有更差的STS。
添加文本-文本損失到DE_I2T訓練中(DE_I2T + T2T),可以使整體性能更加均衡。



























