基于Python創(chuàng)建語音識別控制系統(tǒng)
前言:
這篇文章主要介紹了通過Python實現創(chuàng)建語音識別控制系統(tǒng),能利用語音識別識別說出來的文字,根據文字的內容來控制圖形移動,感興趣的同學可以關注一下
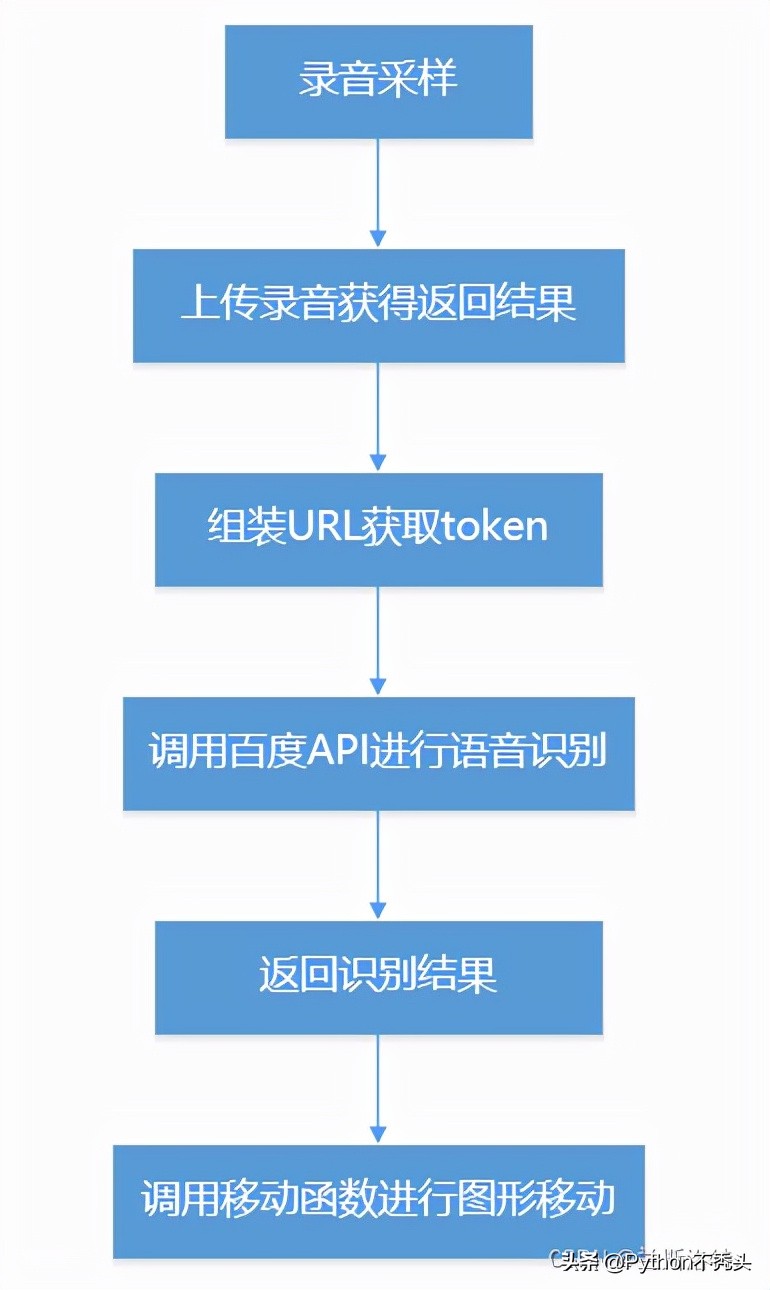
利用語音識別識別說出來的文字,根據文字的內容來控制圖形移動,例如說向上,識別出文字后,畫布上的圖形就會向上移動。本文使用的是百度識別API(因為免費),自己做的流程圖:
不多說,直接開始程序設計,首先登錄百度云,創(chuàng)建應用
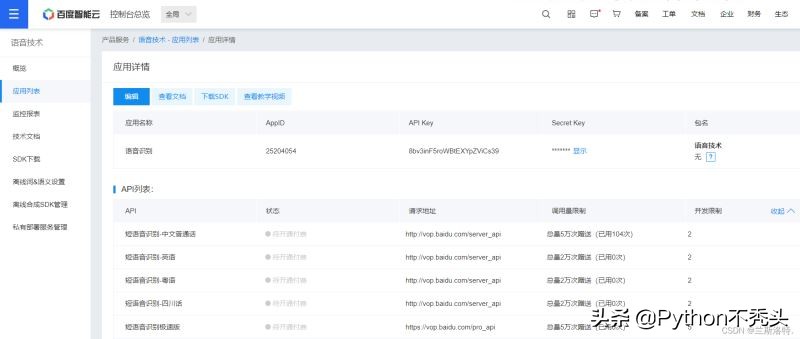
注意這里的API Key和Secret Key,要用自己的才能生效
百度語音識別有對應的文檔,具體調用方法說的很清晰,如果想學習一下可以查看REST API文檔
文檔寫的很詳細,本文只說明用到的方法,語音識別使用方法為組裝URL獲取token,然后處理本地音頻以JSON格式發(fā)送到百度語音識別服務器,獲得返回結果。
百度語音識別支持pcm、wav等多種格式,百度服務端會將非pcm格式轉成pcm格式,因此使用wav、amr格式會有額外的轉換耗時。保存為pcm格式可以識別,只是windows自帶播放器識別不了pcm格式的,所以改用wav格式,同時要引用wave庫,功能為可讀、寫wav類型的音頻文件。采樣率使用了pcm采樣率16000固定值,編碼為16bit位深得單聲道。

錄音函數中使用了PyAudio庫,是Python下的一個音頻處理模塊,用于將音頻流輸送到計算機聲卡上。在當前文件夾打開一個新的音頻進行錄音并存放錄音數據。本地錄音:

然后是獲取token,根據創(chuàng)建應用得到的APIKey和SecreKey(這里要使用自己的)來組裝URL獲取token。在語音識別函數中調用獲取的token和已經錄制好的音頻數據,按照要求的格式來寫進JSON參數進行上傳音頻。
百度語音要求對本地語音二進制數據進行base64編碼,使用base64庫來進行編碼。創(chuàng)建識別請求使用的是POST方式來進行提交,在識別函數中寫入百度語音提供的短語音識別請求地址。識別結果會立刻返回,采用JSON格式進行封裝,識別結果放在 JSON 的 “result” 字段中,統(tǒng)一采用 utf-8 方式編碼。
- # 組裝url獲取token
- base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"
- APIKey = "*****************"
- SecretKey = "********************"
- HOST = base_url % (APIKey, SecretKey)
- def getToken(host):
- res = requests.post(host)
- r = res.json()['access_token']
- return r
- # 傳入語音二進制數據,token
- # dev_pid為百度語音識別提供的幾種語言選擇,默認1537為有標點普通話
- def speech2text(speech_data, token, dev_pid=1537):
- FORMAT = 'wav'
- RATE = '16000'
- CHANNEL = 1
- CUID = '*******'
- SPEECH = base64.b64encode(speech_data).decode('utf-8')
- data = {
- 'format': FORMAT,
- 'rate': RATE,
- 'channel': CHANNEL,
- 'cuid': CUID,
- 'len': len(speech_data),
- 'speech': SPEECH,
- 'token': token,
- 'dev_pid': dev_pid
- }
- url = 'https://vop.baidu.com/server_api' # 短語音識別請求地址
- headers = {'Content-Type': 'application/json'}
- print('正在識別...')
- r = requests.post(url, json=data, headers=headers)
- Result = r.json()
- if 'result' in Result:
- return Result['result'][0]
- else:
- return Result
最后我們編寫控制移動函數,首先我們要知道如何來把控制圖形移動來呈現出來。本項目中我們使用的是tkinter模塊,Tkinter是一個python模塊,是一個調用Tcl/Tk的接口,它是一個跨平臺的腳本圖形界面接口。是一個比較流行的python圖形編程接口。最大的特點是跨平臺,缺點是性能不太好,執(zhí)行速度慢。
我們利用tkinter中的canvas來設置一個畫布,并創(chuàng)建一個事件ID為1的矩形,把矩形放在畫布中顯示。在畫布中添加Button按鈕,回調中寫入對應的函數,點擊觸發(fā)錄制音頻和語音識別。為了使代碼更加簡潔,我們把移動函數放在語音識別函數中調用,返回識別結果后對結果做出判斷,最后使圖形進行移動。
- def move(result):
- print(result)
- if "向上" in result:
- canvas.move(1, 0, -30) # 移動的是 ID為1的事物【move(2,0,-5)則移動ID為2的事物】,使得橫坐標加0,縱坐標減30
- elif "向下" in result:
- canvas.move(1, 0, 30)
- elif "向左" in result:
- canvas.move(1, -30, 0)
- elif "向右" in result:
- canvas.move(1, 30, 0)
- tk = Tk()
- tk.title("語音識別控制圖形移動")
- Button(tk, text="開始錄音", command=AI.my_record).pack()
- Button(tk, text="開始識別", command=speech2text).pack()
- canvas = Canvas(tk, width=500, height=500) # 設置畫布
- canvas.pack() # 顯示畫布
- r = canvas.create_rectangle(180, 180, 220, 220, fill="red") # 事件ID為1
- mainloop()
個人習慣,我把語音識別和圖形控制寫在了兩個文件里,這就導致main.py文件中沒有辦法使用AI.py文件函數中的返回值,因為我們使用的tkinter模塊是不斷循壞的,通過mainloop()才能結束循環(huán),這樣不斷循壞就調用不了返回值,使用的方法是在main.py中重新構建一樣函數來調用AI.py文件中的函數,并聲明全局變量,把AI.py文件中的返回值放在main.py文件的全局變量中,這樣就得到了返回值,再將函數寫到Button回調中就實現了對應的功能。
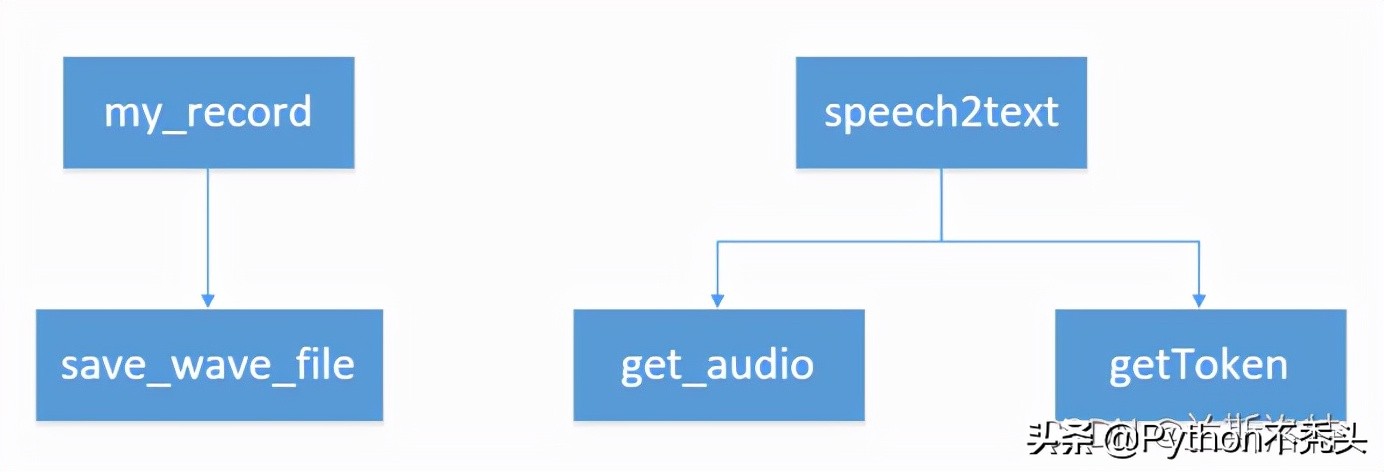
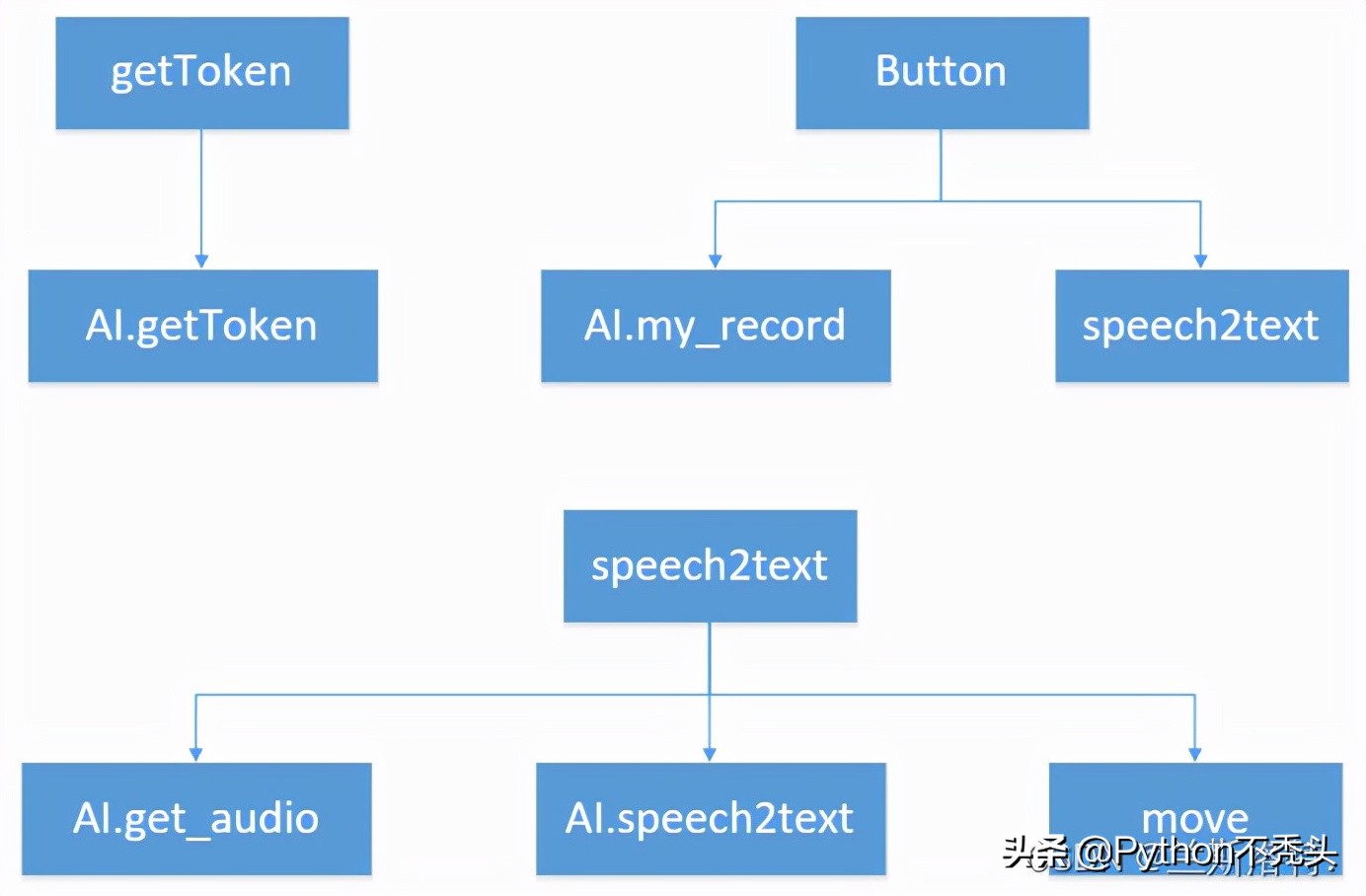
其實代碼寫得十分麻煩,寫在一個文件里會簡單些,我畫了兩個文件的調用關系:
完整demo如下
AI.py
- import wave # 可讀、寫wav類型的音頻文件。
- import requests # 基于urllib,采⽤Apache2 Licensed開源協(xié)議的 HTTP 庫。在本項目中用于傳遞headers和POST請求
- import time
- import base64 # 百度語音要求對本地語音二進制數據進行base64編碼
- from pyaudio import PyAudio, paInt16 # 音頻處理模塊,用于將音頻流輸送到計算機聲卡上
- framerate = 16000 # 采樣率
- num_samples = 2000 # 采樣點
- channels = 1 # 聲道
- sampwidth = 2 # 采樣寬度2bytes
- FILEPATH = 'speech.wav'
- # 組裝url獲取token
- base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"
- APIKey = "8bv3inF5roWBtEXYpZViCs39"
- SecretKey = "HLXYiLGCpeOD6ddF1m6BvwcDZVOYtwwD"
- HOST = base_url % (APIKey, SecretKey)
- def getToken(host):
- res = requests.post(host)
- r = res.json()['access_token']
- return r
- def save_wave_file(filepath, data):
- wf = wave.open(filepath, 'wb')
- wf.setnchannels(channels)
- wf.setsampwidth(sampwidth)
- wf.setframerate(framerate)
- wf.writeframes(b''.join(data))
- wf.close()
- # 錄音
- def my_record():
- pa = PyAudio()
- # 打開一個新的音頻stream
- stream = pa.open(format=paInt16, channels=channels,
- rate=framerate, input=True, frames_per_buffer=num_samples)
- my_buf = [] # 存放錄音數據
- t = time.time()
- print('正在錄音...')
- while time.time() < t + 5: # 設置錄音時間(秒)
- # 循環(huán)read,每次read 2000frames
- string_audio_data = stream.read(num_samples)
- my_buf.append(string_audio_data)
- print('錄音結束.')
- save_wave_file(FILEPATH, my_buf)
- stream.close()
- def get_audio(file):
- with open(file, 'rb') as f:
- data = f.read()
- return data
- # 傳入語音二進制數據,token
- # dev_pid為百度語音識別提供的幾種語言選擇,默認1537為有標點普通話
- def speech2text(speech_data, token, dev_pid=1537):
- FORMAT = 'wav'
- RATE = '16000'
- CHANNEL = 1
- CUID = '*******'
- SPEECH = base64.b64encode(speech_data).decode('utf-8')
- data = {
- 'format': FORMAT,
- 'rate': RATE,
- 'channel': CHANNEL,
- 'cuid': CUID,
- 'len': len(speech_data),
- 'speech': SPEECH,
- 'token': token,
- 'dev_pid': dev_pid
- }
- url = 'https://vop.baidu.com/server_api' # 短語音識別請求地址
- headers = {'Content-Type': 'application/json'}
- print('正在識別...')
- r = requests.post(url, json=data, headers=headers)
- Result = r.json()
- if 'result' in Result:
- return Result['result'][0]
- else:
- return Result
main.py
- import AI
- from tkinter import * # 導入tkinter模塊的所有內容
- token = None
- speech = None
- result = None
- def getToken():
- temptoken = AI.getToken(AI.HOST)
- return temptoken
- def speech2text():
- global token
- if token is None:
- token = getToken()
- speech = AI.get_audio(AI.FILEPATH)
- result = AI.speech2text(speech, token, dev_pid=1537)
- print(result)
- move(result)
- def move(result):
- print(result)
- if "向上" in result:
- canvas.move(1, 0, -30) # 移動的是 ID為1的事物【move(2,0,-5)則移動ID為2的事物】,使得橫坐標加0,縱坐標減30
- elif "向下" in result:
- canvas.move(1, 0, 30)
- elif "向左" in result:
- canvas.move(1, -30, 0)
- elif "向右" in result:
- canvas.move(1, 30, 0)
- tk = Tk()
- tk.title("語音識別控制圖形移動")
- Button(tk, text="開始錄音", command=AI.my_record).pack()
- Button(tk, text="開始識別", command=speech2text).pack()
- canvas = Canvas(tk, width=500, height=500) # 設置畫布
- canvas.pack() # 顯示畫布
- r = canvas.create_rectangle(180, 180, 220, 220, fill="red") # 事件ID為1
- mainloop()
文件關系
錄制的音頻會自動保存在當前文件夾下,就是speech文件
測試結果,運行
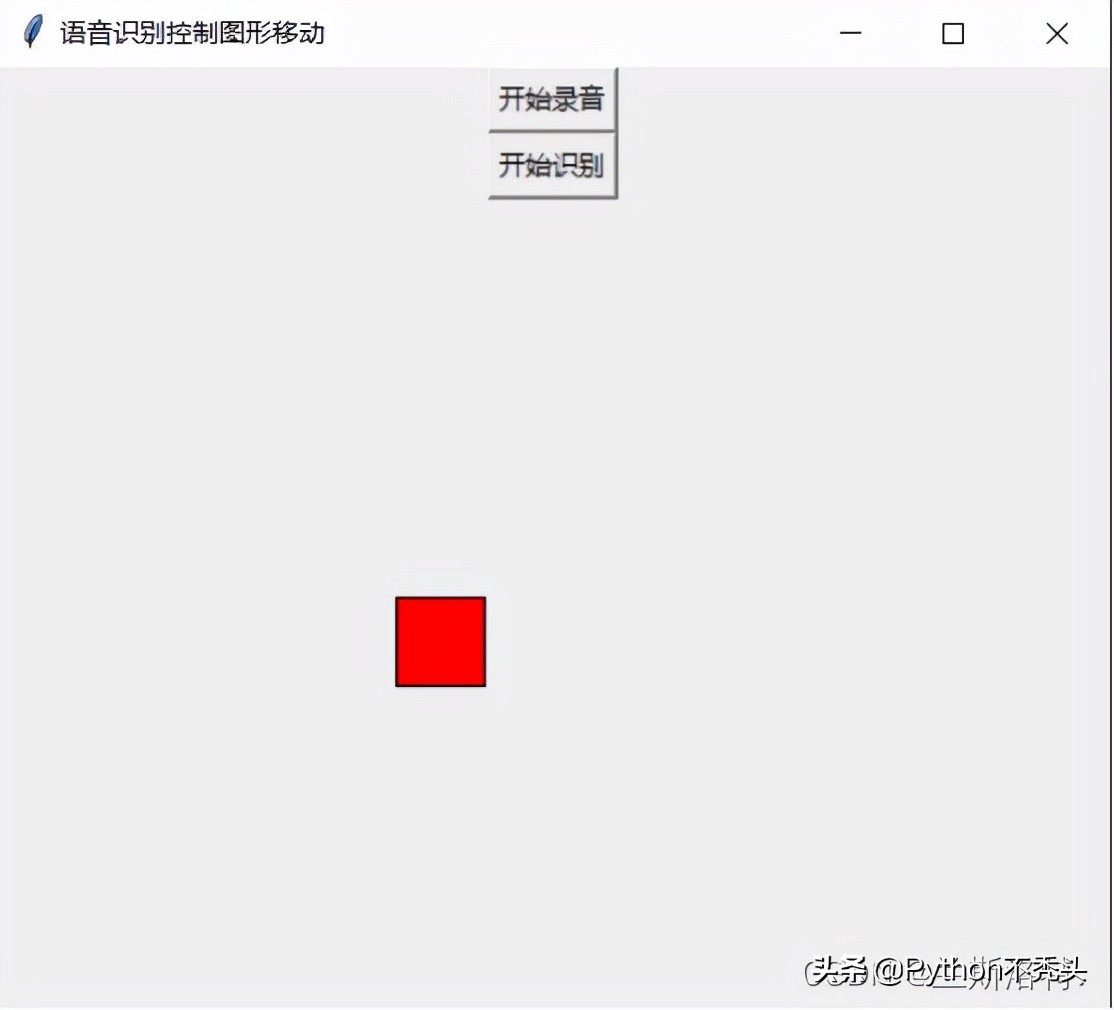
點擊開始錄音

點擊開始識別

然后可以看到圖形往右移動
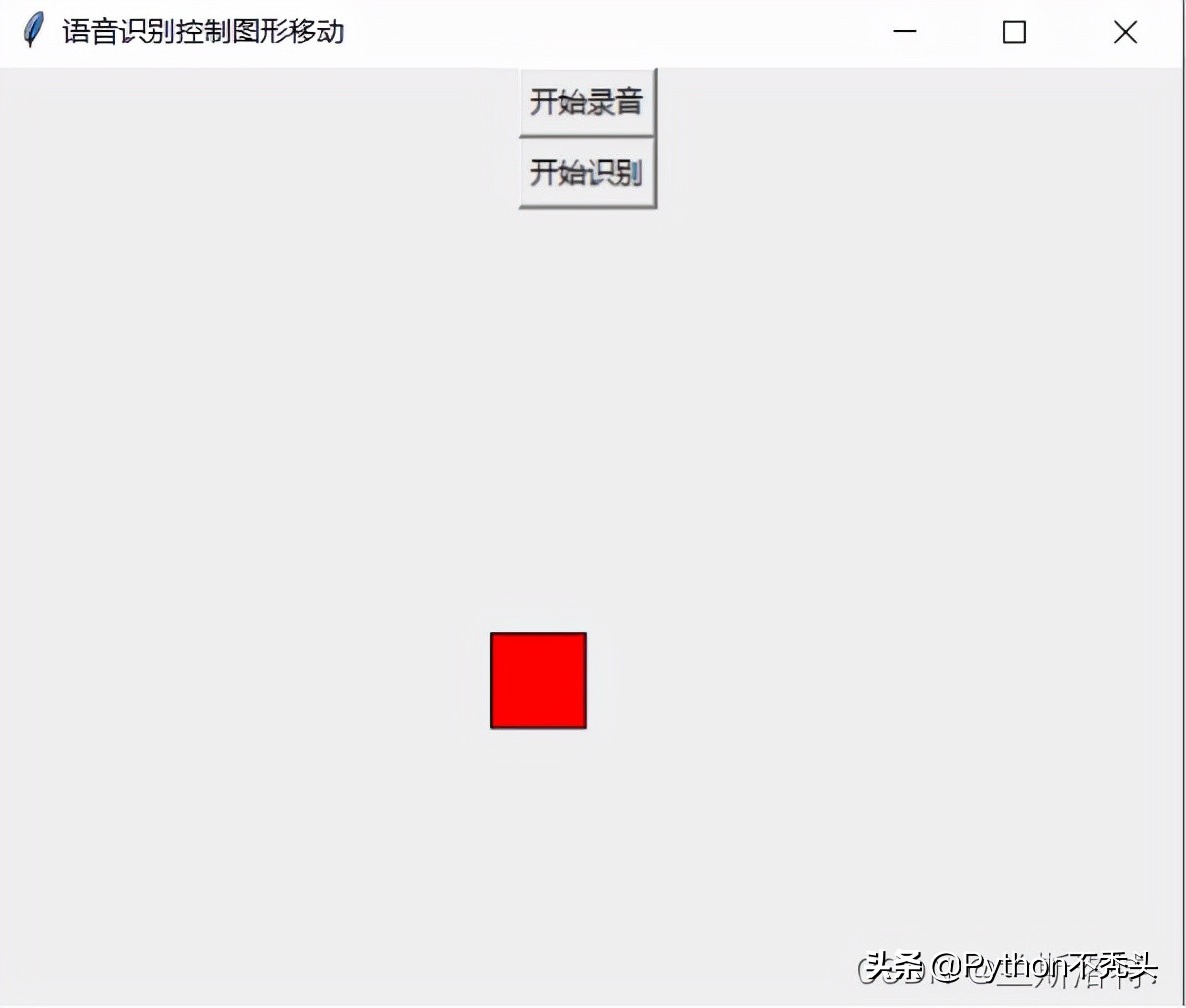
經測試,大吼效果更佳
到此這篇關于基于Python創(chuàng)建語音識別控制系統(tǒng)的文章就介紹到這了!