













面試官:Java中實例對象存儲在哪?
本文轉載自微信公眾號「java寶典」,作者iTengyu。轉載本文請聯系java寶典公眾號。
目錄:
- 理解Java編譯流程
- 前端編譯(Front End)
- 后端編譯(Back End)
- 什么是JIT (Just in time)
- 編譯器和解釋器的優缺點以及實用場景
- 熱點檢測算法
- 1)基于采樣的熱點探測
- 2) 基于計數器的熱點探測
- 對象棧上分配的優化
- 逃逸分析
- 標量替換
- 同步消除(鎖消除)
- 棧上分配
- 對象的內存分配
- 解決堆內存分配的并發問題
- CAS
- TLAB
- 總結
理解Java編譯流程
低級語言是計算機認識的語言、高級語言是程序員認識的語言。如何從高級語言轉換成低級語言呢?這個過程其實就是編譯。
不同的語言都有自己的編譯器,Java語言中負責編譯的編譯器是一個命令:javac
通過javac命令將Java程序的源代碼編譯成Java字節碼,即我們常說的.class文件。這也是我們所理解的編譯.
但是.class并不是計算機能夠識別的語言.要想讓機器能夠執行,需要把字節碼再翻譯成機器指令,這個過程是JVM來完成的.這個過程也叫編譯.只是層次更深..
因此我們了解到,編譯器可劃分為前端(Front End)與后端(Back End)。
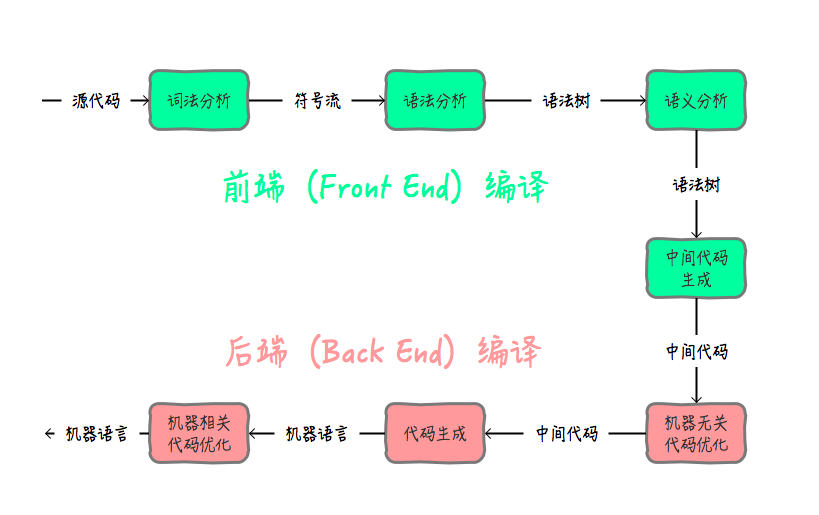
我們可以把將.java文件編譯成.class的編譯過程稱之為前端編譯。把將.class文件翻譯成機器指令的編譯過程稱之為后端編譯。
前端編譯(Front End)
前端編譯主要指與源語言有關但與目標機無關的部分,包括詞法分析、語法分析、語義分析與中間代碼生成。
例如我們使用很多的IDE,如eclipse,idea等,都內置了前端編譯器。主要功能就是把.java代碼轉換成`.class字節碼
后端編譯(Back End)
后端編譯主要指與目標機有關的部分,包括代碼優化和目標代碼生成等。
在后端編譯中,通常都經過前端編譯的處理,已經加工成.class字節碼文件了 JVM通過解釋字節碼將其逐條讀入并翻譯為對應機器指令,讀一條翻譯一條,勢必是分產生效率問題因此引入了JIT(just in time)
什么是JIT (Just in time)
當JVM發現某個方法或代碼塊運行特別頻繁的時候,就會認為這是“熱點代碼”(Hot Spot Code)。JIT會把部分“熱點代碼”翻譯成本地機器相關的機器碼,并進行優化,然后緩存起來,以備下次使用
在HotSpot虛擬機中內置了兩個JIT編譯器分別是:
- - Client complier [客戶端]
- - Server complier [服務端]
目前JVM中默認都是采用: 解釋器+一個JIT編譯器 配合的方式進行工作 即混合模式
下圖是我機器上安裝的JDK ,可以看出,使用的JIT是Server Complier, 解釋器和JIT的工作方式是mixed mode
面試題:為何HotSpot虛擬機要實現兩個不同的即時編譯器?
HotSpot虛擬機中內置了兩個即時編譯器:Client Complier和Server Complier,簡稱為C1、C2編譯器,分別用在客戶端和服務端。目前主流的HotSpot虛擬機中默認是采用解釋器與其中一個編譯器直接配合的方式工作。程序使用哪個編譯器,取決于虛擬機運行的模式。HotSpot虛擬機會根據自身版本與宿主機器的硬件性能自動選擇運行模式,用戶也可以使用“-client”或“-server”參數去強制指定虛擬機運行在Client模式或Server模式。
用Client Complier獲取更高的編譯速度,用Server Complier 來獲取更好的編譯質量。和為什么提供多個垃圾收集器類似,都是為了適應不同的應用場景。
編譯器和解釋器的優缺點以及實用場景
在JVM執行代碼時,它并不是馬上開始編譯代碼,當一段經常被執行的代碼被編譯后,下次運行就不用重復編譯,此時使用JIT是劃算的,但是它也不是萬能的,比如說一些極少執行的代碼在編譯時花費的時間比解釋器還久,這時就是得不償失了
所以,解釋器和JIT各有千秋:
解釋器與編譯器兩者各有優勢:當程序需要迅速啟動和執行的時候,解釋器可以首先發揮作用,省去編譯的時間,立即執行。在程序運行后,隨著時間的推移,編譯器逐漸發揮作用,把越來越多的代碼編譯成本地代碼之后,可以獲取更高的執行效率。
當極少執行或者執行次數較少的JAVA代碼使用解釋器最優.
當重復執行或者執行次數較多的JAVA代碼使用JIT更劃算.
熱點檢測算法
要想觸發JIT,首先需要識別出熱點代碼。目前主要的熱點代碼識別方式是熱點探測(Hot Spot Detection),有以下兩種:
1)基于采樣的熱點探測
采用這種方法的虛擬機會周期性地檢查各個線程的棧頂,如果發現某些方法經常出現在棧頂,那這個方法就是“熱點方法”。這種探測方法的好處是實現簡單高效,還可以很容易地獲取方法調用關系(將調用堆棧展開即可),缺點是很難精確地確認一個方法的熱度,容易因為受到線程阻塞或別的外界因素的影響而擾亂熱點探測。
2) 基于計數器的熱點探測
采用這種方法的虛擬機會為每個方法(甚至是代碼塊)建立計數器,統計方法的執行次數,如果執行次數超過一定的閥值,就認為它是“熱點方法”。這種統計方法實現復雜一些,需要為每個方法建立并維護計數器,而且不能直接獲取到方法的調用關系,但是它的統計結果相對更加精確嚴謹。
那么在HotSpot虛擬機中使用的是哪個熱點檢測方式呢?
在HotSpot虛擬機中使用的是第二種,基于計數器的熱點探測方法,因此它為每個方法準備了兩個計數器:
>1 方法調用計數器
顧名思義,就是記錄一個方法被調用次數的計數器。
>2 回邊計數器
是記錄方法中的for或者while的運行次數的計數器。
在確定虛擬機運行參數的前提下,這兩個計數器都有一個確定的閾值,當計數器超過閾值溢出了,就會觸發JIT編譯。
對象棧上分配的優化
逃逸分析逃逸分析是一種有效減少JAVA程序中 同步負載 和 堆內存分配壓力 的分析算法.Hotspot編譯器能夠分析出一個新的對象的引用的使用范圍從而決定是否要將這個對象分配到棧上.
- public static StringBuffer method(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append("關注");
- sb.append("java寶典");
- return sb;
- //此時sb對象從method方法逃出..
- }
- public static String method(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append("關注");
- sb.append("java寶典");
- return sb.toString();
- //此時sb對象 沒有離開 作用域
- }
- public void globalVariableEscape(){
- globalVariableObject = new Object(); //靜態變量,外部線程可見,發生逃逸
- }
- public void instanceObjectEscape(){
- instanceObject = new Object(); //賦值給堆中實例字段,外部線程可見,發生逃逸
- }
public void globalVariableEscape(){ globalVariableObject = new Object(); //靜態變量,外部線程可見,發生逃逸 } public void instanceObjectEscape(){ instanceObject = new Object(); //賦值給堆中實例字段,外部線程可見,發生逃逸 }
在確定對象不會逃逸后,JIT將可以進行以下優化: 標量替換 同步消除 棧上分配
第一段代碼中的sb就逃逸了,而第二段代碼中的sb就沒有逃逸。
在Java代碼運行時,通過JVM參數可指定是否開啟逃逸分析,
-XX:+DoEscapeAnalysis :表示開啟逃逸分析
-XX:-DoEscapeAnalysis :表示關閉逃逸分析
-XX:+PrintEscapeAnalysis 開啟打印逃逸分析篩選結果
從jdk 1.7開始已經默認開始逃逸分析
標量替換
允許將對象打散分配在棧上,比如若一個對象擁有兩個字段,會將這兩個字段視作局部變量進行分配。
逸分析只是棧上內存分配的前提,還需要進行標量替換才能真正實現。例:
- public static void main(String[] args) throws Exception {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 10000; i++) {
- allocate();
- }
- System.out.println((System.currentTimeMillis() - start) + " ms");
- Thread.sleep(10000);
- }
- public static void allocate() {
- MyObject myObject = new MyObject(2019, 2019.0);
- }
- public static class MyObject {
- int a;
- double b;
- MyObject(int a, double b) {
- this.a = a;
- this.b = b;
- }
- }
標量,就是指JVM中無法再細分的數據,比如int、long、reference等。相對地,能夠再細分的數據叫做聚合量
Java虛擬機中的原始數據類型(int,long等數值類型以及reference類型等)都不能再進一步分解,它們就可以稱為標量。相對的,如果一個數據可以繼續分解,那它稱為聚合量,Java中最典型的聚合量是對象
如果逃逸分析證明一個對象不會被外部訪問,并且這個對象是可分解的,那程序真正執行的時候將可能不創建這個對象,而改為直接創建它的若干個被這個方法使用到的成員變量來代替。拆散后的變量便可以被單獨分析與優化,可以各自分別在棧幀或寄存器上分配空間,原本的對象就無需整體分配空間了
仍然考慮上面的例子,MyObject就是一個聚合量,因為它由兩個標量a、b組成。通過逃逸分析,JVM會發現myObject沒有逃逸出allocate()方法的作用域,標量替換過程就會將myObject直接拆解成a和b,也就是變成了:
- static void allocate() {
- int a = 2019;
- double b = 2019.0;
- }
可見,對象的分配完全被消滅了,而int、double都是基本數據類型,直接在棧上分配就可以了。所以,在對象不逃逸出作用域并且能夠分解為純標量表示時,對象就可以在棧上分配
- 開啟標量替換 (-XX:+EliminateAllocations)
標量替換的作用是允許將對象根據屬性打散后分配在棧上,默認該配置為開啟
同步消除(鎖消除)
如果同步塊所使用的鎖對象通過逃逸分析被證實只能夠被一個線程訪問,那么JIT編譯器在編譯這個同步塊的時候就會取消對這部分代碼的同步。這個取消同步的過程就叫同步省略,也叫鎖消除
例子:
- public void f() {
- Object java_bible = new Object();
- synchronized(java_bible) {
- System.out.println(java_bible);
- }
- }
在經過逃逸分析后,JIT編譯階段會被優化成:
- public void f() {
- Object java_bible = new Object();
- System.out.println(java_bible); //鎖被去掉了.
- }
如果JIT經過逃逸分析之后發現并無線程安全問題的話,就會做鎖消除。
棧上分配
通過逃逸分析,我們發現,許多對象的生命周期會隨著方法的調用開始而開始,方法的調用結束而結束,很多的對象的作用域都不會逃逸出方法外,對于此種對象,我們可以考慮使用棧上分配,而不是在堆中分配.
因為一旦分配在堆空間中,當方法調用結束,沒有了引用指向該對象,該對象就需要被gc回收,而如果存在大量的這種情況,對gc來說反而是一種負擔。
JVM提供了一種叫做棧上分配的概念,針對那些作用域不會逃逸出方法的對象,在分配內存時不在將對象分配在堆內存中,而是將對象屬性打散后分配在棧(線程私有的,屬于棧內存,標量替換)上,這樣,隨著方法的調用結束,棧空間的回收就會隨著將棧上分配的打散后的對象回收掉,不再給gc增加額外的無用負擔,從而提升應用程序整體的性能
那么問題來了,如果棧上分配失敗了怎么辦?
對象的內存分配
創建個對象有多種方法: 比如 使用new , reflect , clone 不管使用哪種 ,我們都要先分配內存
我們拿new 來舉個例子:
- T t = new T()
- class T{
- int m = 8;
- }
- //javap
- 0 new #2<T> //new作用在內存申請開辟一塊空間 new完之后m的值為 0
- 3 dup
- 4 invokespecial #3 <T.<init>>
- 7 astore_1
- 8 return
那么它是怎么分配的呢?
當我們使用new創建對象后代碼開始運行后,虛擬機執行到這條new指令的時候,會先檢查要new的對象對應的類是否已被加載,如果沒有被加載則先進行類加載,檢查通過之后,就需要給對象進行內存分配,分配的內存主要用來存放對象的實例變量
為對象分配空間的任務等同于把一塊確定大小的內存從Java堆中劃分出來
根據內存連續和不連續的情況,JVM使用不同的分配方式.
- 連續: 指針碰撞
- 不連續:空閑列表
指針碰撞(Serial、ParNew等帶Compact過程的收集器) 假設Java堆中內存是絕對規整的,所有用過的內存都放在一邊,空閑的內存放在另一邊,中間放著一個指針作為分界點的指示器,那所分配內存就僅僅是把那個指針向空閑空間那邊挪動一段與對象大小相等的距離,這種分配方式稱為“指針碰撞”(Bump the Pointer)。
空閑列表(CMS這種基于Mark-Sweep算法的收集器) 如果Java堆中的內存并不是規整的,已使用的內存和空閑的內存相互交錯,那就沒有辦法簡單地進行指針碰撞了,虛擬機就必須維護一個列表,記錄上哪些內存塊是可用的,在分配的時候從列表中找到一塊足夠大的空間劃分給對象實例,并更新列表上的記錄,這種分配方式稱為“空閑列表”(Free List)。
無論那種方式,最終都需要確定出一塊內存區域,用于給新建對象分配內存。對象的內存分配過程中,主要是對象的引用指向這個內存區域,然后進行初始化操作,那么在并發場景之中,如果多線程并發去堆中獲取內存區域,怎么保證內存分配的線程安全性.
解決堆內存分配的并發問題
保證分配過程中的線程安全有兩種方式:
- CAS
- TLAB
CAS
CAS:采用CAS機制,配合失敗重試的方式保證線程安全性
CAS對于內存的控制是使用重試機制,因此效率比較低,目前JVM使用的是TLAB方式,我們著重介紹TLAB.
TLAB
TLAB:每個線程在Java堆中預先分配一小塊內存,然后再給對象分配內存的時候,直接在自己這塊"私有"內存中分配,當這部分區域用完之后,再分配新的"私有"內存,注意這個私有對于創建對象時是私有的,但是對于讀取是共享的.
TLAB (Thread local allcation buffer ) 在“分配”這個動作上是線程獨占的,至于在讀取、垃圾回收等動作上都是線程共享的。在對象的創建時,首先嘗試進行棧上分配,如果分配失敗,會使用TLAB嘗試分配,如果失敗查看是否是大對象,如果是大對象直接進入老年代,否則進入新生代(Eden).這里我總結了一張流程圖,如下:
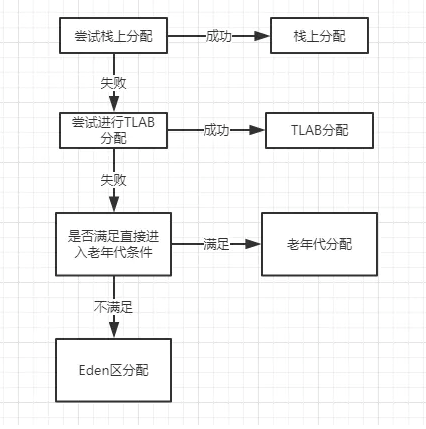
我們可以總結出: 創建大對象和創建多個小對象相比,多個小對象的效率更高
不知道大家有沒有注意到,TLAB分配空間,每個線程在Java堆中預先分配一小塊內存,他們在堆中去搶地盤的時候,也會出現并發問題,但是對于TLAB的同步控制和我們直接在堆中分配相比效率高了不少(不至于因為要分配一個對象而鎖住整個堆了).
總結
為了保證Java對象的內存分配的安全性,同時提升效率,每個線程在Java堆中可以預先分配一小塊內存,這部分內存稱之為TLAB(Thread Local Allocation Buffer),這塊內存的分配時線程獨占的,讀取、使用、回收是線程共享的。
虛擬機是否使用TLAB 可以通過 -XX:+/-UseTLAB 參數指定






















