













面試官問我 InnoDB 的物理存儲(chǔ)結(jié)構(gòu)!
前段時(shí)間去面試,面試官突然問我:聊聊 InnoDB 的物理存儲(chǔ)結(jié)構(gòu)吧!
樹義突然又眼圈一黑,啥都想不起來了!
雖說之前有大致了解過 MySQL,但對(duì) InnoDB 的物理結(jié)構(gòu),卻真的沒咋了解過!那么,今天就來聊聊 InnoDB 的物理存儲(chǔ)結(jié)構(gòu)吧!
相信很多人都知道邏輯結(jié)構(gòu)和物理結(jié)構(gòu)這兩個(gè)概念,但是都很好奇它們的區(qū)別是什么?
簡(jiǎn)單地說:所謂物理存儲(chǔ)結(jié)構(gòu),指的是 MySQL 的數(shù)據(jù)是怎么存儲(chǔ)在物理介質(zhì)上的,由哪些磁盤文件組成。所謂邏輯存儲(chǔ)結(jié)構(gòu),指的是這些數(shù)據(jù)是如何有結(jié)構(gòu)地組織起來的。
此文所描述的 InnoDB 物理存儲(chǔ)結(jié)構(gòu),依據(jù)的是 MySQL 8.0 版本。
從 MySQL 官方文檔中,我們可知 InnoDB 在物理層面上可劃分為如下 7 個(gè)模塊:
- 系統(tǒng)表空間(System Tablespace)
- 雙寫緩存文件(Doublewrite Buffer Files)
- Undo 表空間(Undo Tablespaces)
- Redo Log 文件(Redo Log)
- 獨(dú)占表空間(File-Per-Table Tablespaces)
- 通用表空間(General Tablespaces)
- 臨時(shí)表空間(Temporary Tablespaces)
而在這 7 個(gè)模塊中,最為關(guān)鍵的是如下三個(gè)模塊:系統(tǒng)表空間(System Tablespace)、獨(dú)立表空間(File-Per-Table Tablespaces)、日志文件組(Redo Log)。
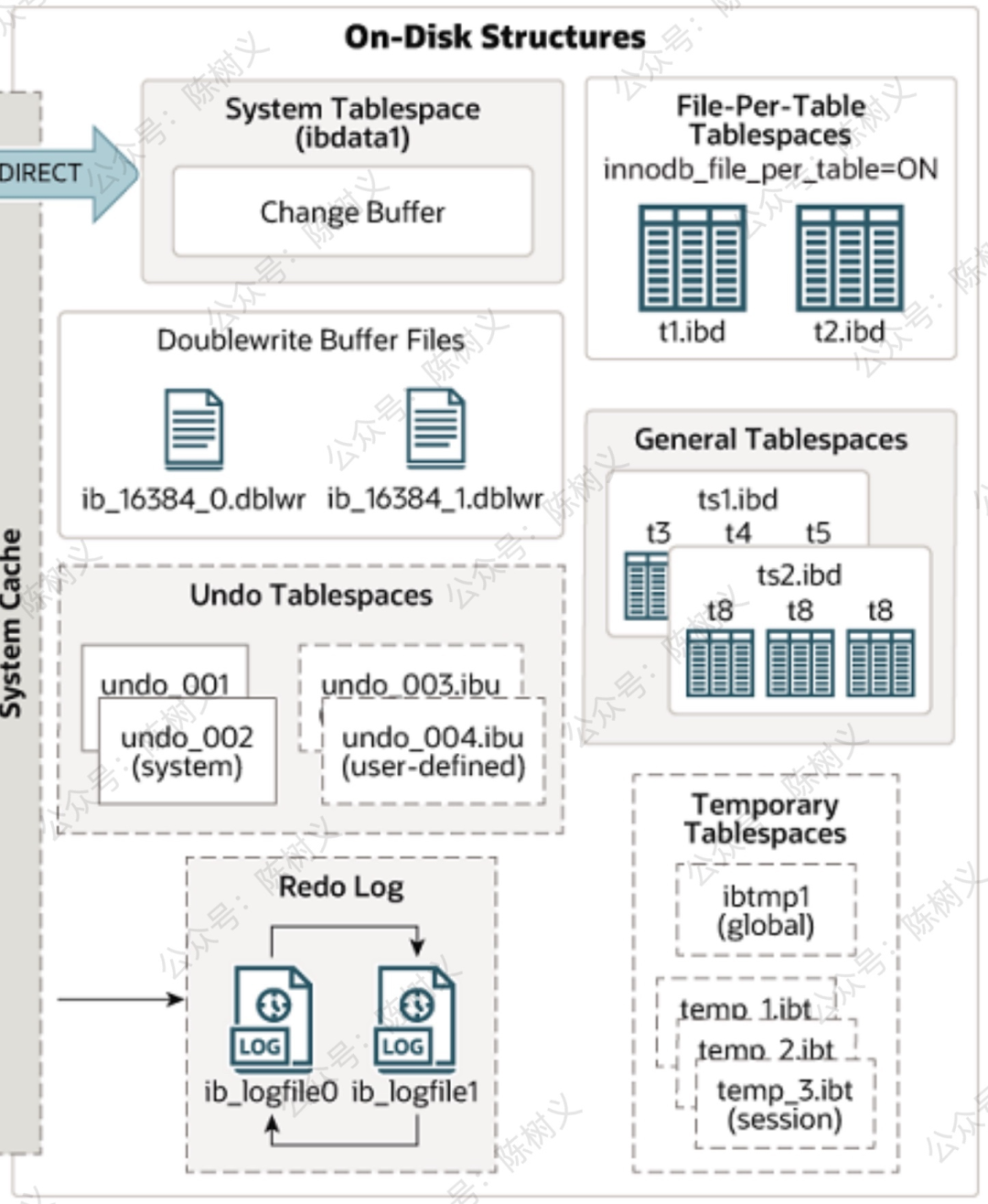
InnoDB 磁盤存儲(chǔ)結(jié)構(gòu) MySQL 8.0
系統(tǒng)表空間(System Tablespace)
在開始之前,我們需要理解表空間這個(gè)概念。其實(shí)表空間,就是存儲(chǔ)表的空間之意。它是 InnoDB 用于描述數(shù)據(jù)存儲(chǔ)的術(shù)語,大致是存儲(chǔ)表相關(guān)數(shù)據(jù)的地方之意。系統(tǒng)表空間,顧名思義就是 InnoDB 這個(gè)系統(tǒng)的默認(rèn)表空間,也叫共享表空間,對(duì)應(yīng)的是 MySQL 數(shù)據(jù)目錄下的 ibdata1 文件。如果我們將 innodb_file_per_table 設(shè)置為 off,那么我們使用 CREATE TABLE 語句創(chuàng)建的表數(shù)據(jù),都會(huì)存儲(chǔ)在系統(tǒng)表空間中。
而如果我們將 innodb_file_per_table 設(shè)置為 on,則每個(gè)表將獨(dú)立地產(chǎn)生一個(gè)表空間文件,以 ibd 結(jié)尾,數(shù)據(jù)、索引、表的內(nèi)部數(shù)據(jù)字典信息都將保存在這個(gè)單獨(dú)的表空間文件中。但是還有一些信息,例如 undo log 信息,還是會(huì)保存在系統(tǒng)表空間中。例如我們?cè)? test 數(shù)據(jù)庫中創(chuàng)建了一個(gè)名為 user 的表,那么就會(huì)在 MySQL 的數(shù)據(jù)文件夾的 test 文件夾下,有一個(gè)名為 user.ibd 文件。
我們注意到系統(tǒng)表空間還有一個(gè)名為 change buffer 的東西,它到底是啥東西呢?
change buffer,其實(shí)在之前版本是插入緩沖(insert buffer),后續(xù)版本變成了 change buffer(參考:內(nèi)幕 2.4.1 章節(jié))。這一塊區(qū)域就是 Change Buffer。5.5 之前叫 Insert Buffer 插入緩沖,現(xiàn)在也能支持 delete 和 update,最后把 Change Buffer 記錄到數(shù)據(jù)頁的操作叫做 merge。
這里面有一句話很關(guān)鍵:除了主鍵聚合索引外,還產(chǎn)生了一個(gè) name 列的輔助索引,對(duì)于該非聚集索引來說,葉子節(jié)點(diǎn)的插入不再有序,這時(shí)就需要離散訪問非聚集索引頁,插入性能變低。
這句話的意思是:聚集索引的插入是有序自增的,那么插入的時(shí)候直接跟在后面就可以了,不需要再做其他隨機(jī)訪問操作。而由于插入的非聚集索引列,并不是有序的,可能會(huì)插在中間,這時(shí)候就需要看看中間這個(gè)頁是否加載到內(nèi)存里。如果加載了,那還好,那就做 B+ 樹操作,調(diào)整就行。不在內(nèi)存里的話,那就麻煩了,需要讀取多次 page 到內(nèi)存。
為了提高效率,就弄了一個(gè) insert buffer,簡(jiǎn)單地說,就是把多次 insert 或者修改操作,先緩存起來,然后等到差不多的時(shí)候,再一起去做,提高效率,避免多次 IO 讀取。
插入緩沖,并不是緩存的一部分,而是物理頁,對(duì)于非聚集索引的插入或更新操作,不是每一次直接插入索引頁。而是先判斷插入的非聚集索引頁是否在緩沖池中。如果在,則直接插入,如果不再,則先放入一個(gè)插入緩沖區(qū)中。然后再以一定的頻率執(zhí)行插入緩沖和非聚集索引頁子節(jié)點(diǎn)的合并操作。
當(dāng)需要更新一個(gè)數(shù)據(jù)頁時(shí),如果數(shù)據(jù)頁在內(nèi)存中就直接更新,而如果這個(gè)數(shù)據(jù)頁還沒有在內(nèi)存中的話,在不影響數(shù)據(jù)一致性的前提下,InnoDB 會(huì)將這些更新操作緩存在 change buffer 中,這樣就不需要從磁盤中讀入這個(gè)數(shù)據(jù)頁了。在下次查詢需要訪問這個(gè)數(shù)據(jù)頁的時(shí)候,將數(shù)據(jù)頁讀入內(nèi)存,然后執(zhí)行 change buffer 中與這個(gè)頁有關(guān)的操作。
雙寫緩存文件(Doublewrite Buffer Files)
如果說插入緩沖帶給 InnoDB 存儲(chǔ)引擎的是性能,那么雙寫帶給 InnoDB 存儲(chǔ)引擎的是數(shù)據(jù)的可靠性。當(dāng)數(shù)據(jù)庫宕機(jī)時(shí),可能數(shù)據(jù)庫正在寫一個(gè)頁面,而這個(gè)頁只寫了一部分(比如 16K 的頁,只寫了前 4K 的頁),我們稱之為寫失效。在 InnoDB 存儲(chǔ)引擎未使用 double write 之前,曾出現(xiàn)過因?yàn)椴糠謱懯Ф鴮?dǎo)致數(shù)據(jù)丟失的情況。
InnoDB 存儲(chǔ)引擎 double write 的體系架構(gòu)如下圖所示:
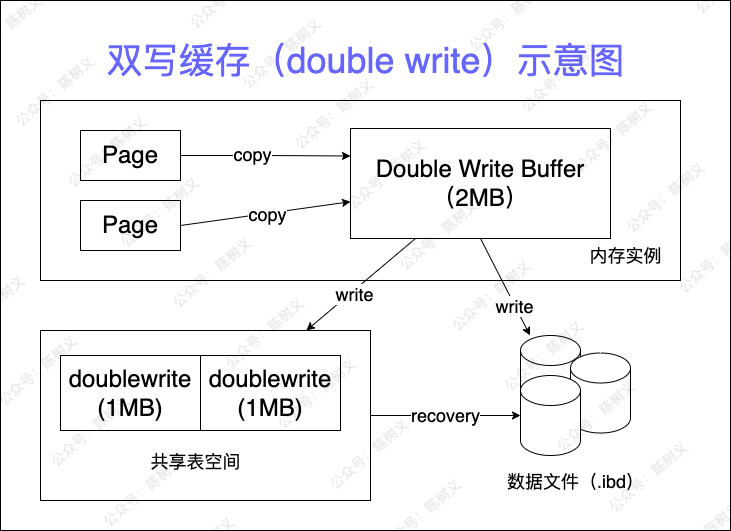
雙寫緩存(double write)示意圖
double write 由兩部分組成:一部分是內(nèi)存中的 double write buffer,大小為 2MB。另一部分是物理磁盤上共享表空間中連續(xù)的 128 個(gè)頁,即兩個(gè)區(qū),大小同樣為 2MB。
當(dāng)緩沖池的臟頁刷新時(shí),并不直接寫磁盤,而是會(huì)他通過 memcpy 函數(shù)將臟頁先拷貝到內(nèi)存中的 doublewrite buffer,之后通過 doublewrite buffer 再分兩次,每次寫入 1MB 到共享表空間的物理磁盤上,然后馬上調(diào)用 fsync 函數(shù),同步磁盤,避免緩沖寫帶來的問題。在這個(gè)過程中,因?yàn)?doublewrite 頁是連續(xù)的,因此這個(gè)過程是順序?qū)懀_銷不是很大。
在完成 doublewrite 頁的寫入之后,再將 doublewrite buffer 中的頁寫入各個(gè)表空間文件中,此時(shí)的寫入則是離散的。我們可以通過 show global status like 'innodb_dblwr%'\G 觀察具體情況。
所以說雙寫,其實(shí)指的是刷臟頁的時(shí)候,即會(huì)將臟頁數(shù)據(jù)寫入共享表空間的 2 個(gè)頁中,也會(huì)寫入具體的表空間中,共享表空間的數(shù)據(jù)起到備份作用。
如果操作系統(tǒng)在將頁寫入具體的表空間過程中崩潰了,在恢復(fù)過程中,InnoDB 存儲(chǔ)引擎可以從共享表空間中的 doublewrite 中找到該頁的一個(gè)副本,將其拷貝到表空間文件,再應(yīng)用重做日志。
Undo 表空間(Undo Tablespaces)
undo Log 的數(shù)據(jù)默認(rèn)在系統(tǒng)表空間 ibdata1 文件中,因?yàn)楣蚕肀砜臻g不會(huì)自動(dòng)收縮,也可以單獨(dú)創(chuàng)建一個(gè) undo 表空間。
一些疑問,關(guān)于 rollback segment 與 undo log?
很多時(shí)候,我們不太懂,為啥一些說 undo log 在系統(tǒng)表空間,而官方的圖卻有 undo tablespace ?下面這段話,描述得很清楚,原因是版本變化!
Rollback Segment(rseg)稱為回滾段。Mysql5.6 之前 undo 默認(rèn)記錄到系統(tǒng)表空間(ibdata),如果開啟了 innodb_file_per_table ,將放在每個(gè)表的.ibd 文件中。5.6 之后還可以創(chuàng)建獨(dú)立的 undo 表空間,8 之后更是默認(rèn)打開獨(dú)立 undo 表空間,最低數(shù)量為 2,這樣才能保證至少一個(gè) undo 表空間進(jìn)行 truncate,一個(gè) undo 表空間繼續(xù)使用。
每個(gè) rollback Segment 中默認(rèn)有 1024 個(gè) undo log segment,mysql5.5 后 1 個(gè) undo 表空間支持 128 個(gè) rollback Segment。0 號(hào) rollback Segment 默認(rèn)在系統(tǒng)表空間 ibdata 中,1-32rollback Segment 在臨時(shí)表空間,33~128 在獨(dú)立 undo 表空間中(沒有打開則在系統(tǒng)表空間 ibdata 中,這樣系統(tǒng)表空間會(huì)太大),所以 1 個(gè)表空間最多支持 96*1024 個(gè)事務(wù),超了就報(bào)錯(cuò)啦。
一個(gè) undo log segment 稱為 undo log 或 undo slot 或 undo;一個(gè) undo log 對(duì)象對(duì)應(yīng)多個(gè) undo log record,也就是記錄的歷史版本。(Rollback segment -> 多個(gè) Undo log segment (undo log) -> 多個(gè) undo log record)。
疑問 2:mysql rollback segment 和 undo segment 區(qū)別
感覺這兩個(gè)應(yīng)該是差不多的呀?
結(jié)論:Rollback segment 與 undo segment 是包含的關(guān)系,每個(gè) Rollback segment 有 1024 個(gè) undo segment。
undo log 有兩個(gè)作用:提供回滾和多個(gè)行版本控制 (MVCC)。
在數(shù)據(jù)修改的時(shí)候,不僅記錄了 redo,還記錄了相對(duì)應(yīng)的 undo,如果因?yàn)槟承┰驅(qū)е率聞?wù)失敗或回滾了,可以借助該 undo 進(jìn)行回滾。
undo log 和 redo log 記錄物理日志不一樣,它是邏輯日志。可以認(rèn)為當(dāng) delete 一條記錄時(shí),undo log 中會(huì)記錄一條對(duì)應(yīng)的 insert 記錄,反之亦然,當(dāng) update 一條記錄時(shí),它記錄一條對(duì)應(yīng)相反的 update 記錄。
rollback segment 稱為回滾段,每個(gè)回滾段中有 1024 個(gè) undo log segment。
Redo Log 文件(Redo Log)
redo log 即重做日志,從字面意思來看,其表示可以將事情重做一遍的意思。而事實(shí)上,它確實(shí)是代表著這個(gè)意思。對(duì)于上文的更新語句 update t set c=c+1 where id = 2,我們的正常實(shí)現(xiàn)思路應(yīng)該是:
找到 id 為 2 的記錄,取出其 c 字段的值。
將 c 字段的值加一,之后將 id 為 2 的字段的 c 字段更新。
但實(shí)際上 MySQL 并不是這么做的,因?yàn)樯鲜鲞@種實(shí)現(xiàn)方式雖然能實(shí)現(xiàn),但是每次都要去讀取磁盤查找記錄、寫入磁盤更新記錄,整個(gè)過程的磁盤 IO 成本很高。為了提高效率,MySQL 使用了一種叫做 WAL(Write-Ahead Logging)的技術(shù),即寫之前先記錄變更日志(redo log),等待合適的時(shí)間再將其變更應(yīng)用到數(shù)據(jù)庫里。因?yàn)槲覀儗⒉僮饔涗浵聛砹耍晕覀兛梢詮?fù)現(xiàn)這個(gè)操作,這就好像我們將事情重現(xiàn)了一樣,因此叫 redo log。
使用 WAL 技術(shù),上面這條更新語句的大致實(shí)現(xiàn)思路就變成了:
記錄下更新操作日志:其要將 id 為 2 的記錄的 c 字段加 1。
某個(gè)時(shí)刻,MySQL 數(shù)據(jù)庫應(yīng)用這個(gè) redo log 日志,將數(shù)據(jù)庫 id 為 2 的記錄的 c 字段加 1。
注意:redo log 并不會(huì)應(yīng)用于磁盤的表空間,而是在重啟時(shí)應(yīng)用于內(nèi)存表空間緩存,用于實(shí)現(xiàn) crash-safe。
可以看到,使用 WAL 技術(shù)的方式,可以不需要去讀寫磁盤,極大提高了執(zhí)行效率。
我們舉一個(gè)很形象的例子來理解 WAL 技術(shù)。想象有一個(gè)酒館,生意非常好,老板也愿意賒賬。每次別人想要賒賬,老板都得去翻賬本,看看這個(gè)人有沒有賒過賬,有賒賬的話就需要在原來的賒賬金額上再加上本次消費(fèi)的金額。
在平時(shí)酒館人不多的時(shí)候,這種方式還是可以應(yīng)付應(yīng)付的。但是一旦到了酒館高峰期的時(shí)候,每個(gè)人都等著結(jié)賬,這時(shí)候再用這種方式去結(jié)賬,很可能讓客戶等太久,引起民憤。于是老板想了個(gè)辦法:我不去賬本上找誰賒賬了,我直接在黑板上記錄下誰賒賬了多少錢。例如:張三賒賬 3 塊銀元,李四賒賬 4 塊銀元。
等生意沒那么忙的時(shí)候,老板拿出賬本,將粉板上的變更記錄進(jìn)賬本:哦,之前張三賒賬了 4 塊銀元,現(xiàn)在又賒賬了 3 塊銀元,所以張三現(xiàn)在總共賒賬 7 塊銀元。在這個(gè)例子中,賬本就相當(dāng)于我們的 MySQL 數(shù)據(jù)庫,粉板就相當(dāng)于我們的 redo log,它將消費(fèi)記錄保存下來。
獨(dú)占表空間(File-Per-Table Tablespaces)
如果我們將 innodb_file_per_table 設(shè)置為 on,則每個(gè)表將獨(dú)立地產(chǎn)生一個(gè)表空間文件,以 ibd 結(jié)尾,數(shù)據(jù)、索引、表的內(nèi)部數(shù)據(jù)字典信息都將保存在這個(gè)單獨(dú)的表空間文件中。但是還有一些信息,例如 undo log 信息,還是會(huì)保存在系統(tǒng)表空間中。例如我們?cè)? test 數(shù)據(jù)庫中創(chuàng)建了一個(gè)名為 user 的表,那么就會(huì)在 MySQL 的數(shù)據(jù)文件夾的 test 文件夾下,有一個(gè)名為 user.ibd 文件。
通用表空間(General Tablespaces)
通用表空間是后續(xù)的 MySQL 推出的表空間,其與系統(tǒng)表空間類似,可以用于存儲(chǔ)表的數(shù)據(jù)和索引。其作用是可以將一些業(yè)務(wù)邏輯不同的表,存放在這個(gè)通用表空間中,從而達(dá)到物理隔離的作用。
臨時(shí)表空間(Temporary Tablespaces)
存儲(chǔ)臨時(shí)表的數(shù)據(jù),包括用戶創(chuàng)建的臨時(shí)表,和磁盤的內(nèi)部臨時(shí)表。對(duì)應(yīng)數(shù)據(jù)目錄下的 ibtmp1 文件。當(dāng)數(shù)據(jù)服務(wù)器正常關(guān)閉時(shí),該表空間被刪除,下次重新產(chǎn)生。
參考資料:
- MySQL :: MySQL 5.7 Reference Manual :: 14.6.3 Tablespaces
- InnoDB 內(nèi)存結(jié)構(gòu)和磁盤結(jié)構(gòu)_wang2963973852 的博客 - CSDN 博客
- [Mysql] 漫游 undo log | 土川的自留地
- 詳細(xì)分析 MySQL 事務(wù)日志 (undo log) - 裸奔的小鴕鳥 - 博客園


















