PULSE:一種基于隱式空間的圖像超分辨率算法
分享一篇 CVPR 2020 錄用論文:PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models,作者提出了一種新的圖像超分辨率方法,區別于有監督的PSNR-based和GANs-based方法,該方法是一種無監督的方法,即只需要低分辨率的圖片就可以恢復高質量、高分辨率的圖片。
目前代碼已經開源:
https://github.com/adamian98/pulse
論文信息:

1. Motivation
圖像超分辨率任務的基本目標就是把一張低分辨率的圖像超分成其對應的高分辨率圖像。無論是基于PNSR還是GAN的監督學習方法,或多或少都會用到pixel-wise誤差損失函數,而這往往會導致生成的圖像比較平滑,一些細節效果不是很好。于是作者換了一個思路:**以往的方法都是從LR,逐漸恢復和生成HR;如果能找到一個高分辨率圖像HR的Manifold,并從該Manifold中搜尋到一張高分辨率的圖像使其下采樣能恢復到LR,那么搜尋到的那張圖像就是LR超分辨率后的結果。**所以本篇文章主要解決了以下的兩個問題:
如何找到一個高分辨率圖像的Manifold?
如何在高分辨率圖像的Manifold上搜尋到一張圖片使其下采樣能恢復LR?
2. Method
假設高分辨率圖像的Manifold是,是M上的一個高分辨率圖片,給定一個低分辨率圖像,如果可以通過下采樣操作DS恢復LR,那么就可以認為是LR的超分辨率結果,該問題定義如下:
即當兩者的差值小于某個閾值時。令,那么本文任務其實就是找到一個如下圖所示:
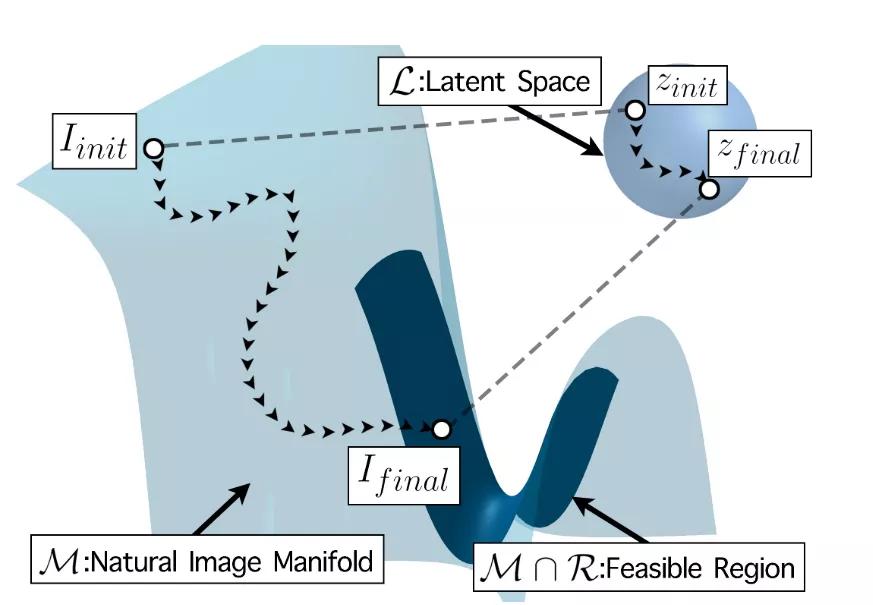

以上就是本篇文章的核心內容,下面我們結合代碼來看一下具體是怎么實現的。
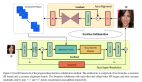
首先我們需要一個生成模型來近似高分辨率的Manifold,在本文中,作者采用的是StyleGAN的預訓練模型:
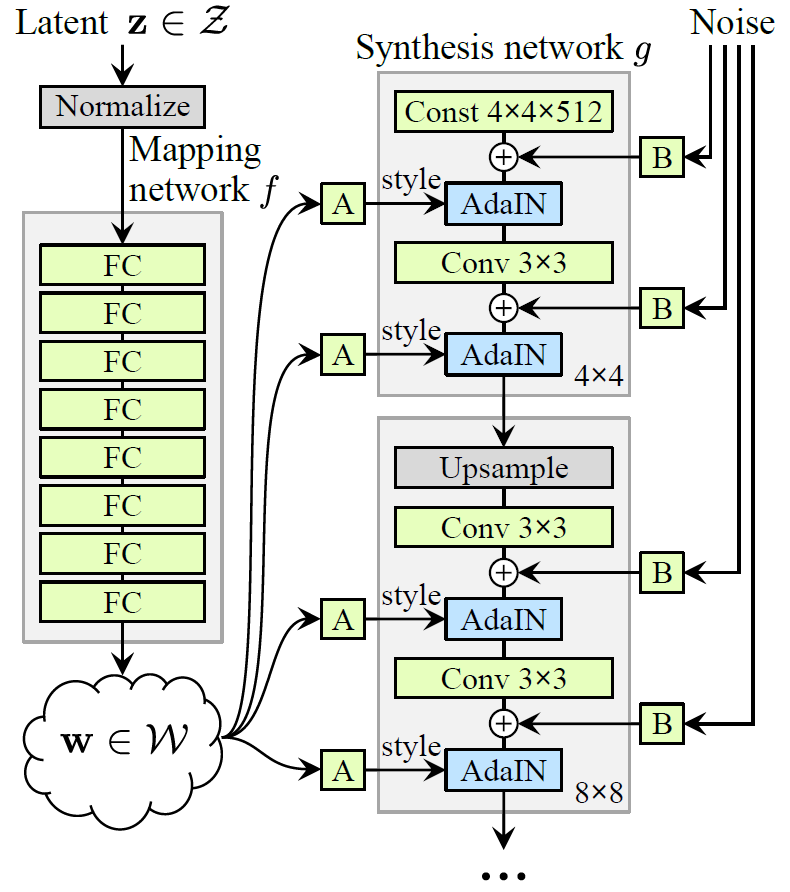
StyleGAN的生成器網絡中有兩個部分,一個是Mapping Network用于將latent code映射為style code,一個Synthesis Network用于將映射后得到的style code用于指導圖像的生成。這里需要注意的是,本篇文章只是使用了StyleGAN的預訓練模型,并不訓練更新其參數。加載兩個部分的參數之后,隨機構造100000個隨機latent code,經過Mapping Network,用得到新的latent code計算均值與方差:
- latent = torch.randn((1000000,512),dtype=torch.float32, device="cuda")
- latent_out = torch.nn.LeakyReLU(5)(mapping(latent))
- self.gaussian_fit = {"mean": latent_out.mean(0), "std": latent_out.std(0)}
這個均值與方差就可以用來映射新的latent code。接下就是隨機初始化latent code和noise(StyleGAN需要):
- # 初始化latent code
- latent = torch.randn((batch_size, 18, 512), dtype=torch.float, requires_grad=True, device='cuda')
- # 初始化noise
- for i in range(18): # [?, 1, 4, 4] -> [?, 1, 1024, 1024]
- res = (batch_size, 1, 2**(i//2+2), 2**(i//2+2))
- new_noise = torch.randn(res, dtype=torch.float, device='cuda')
- if (i < num_trainable_noise_layers): # num_trainable_noise_layers
- new_noise.requires_grad = True
- noise_vars.append(new_noise)
- noise.append(new_noise)
**從這里我們可以看出,模型優化的其實是latent code與noise的前5層,而不是模型參數。**初始化完成了之后就可以執行前向了:
- # 根據之前的求得的均值和方差,映射latent code
- latent_in = self.lrelu(latent_in*self.gaussian_fit["std"] + self.gaussian_fit["mean"])
- # 加載Synthesis Network用于生產圖像
- # 把圖像結果從[-1, 1]修改到[0, 1]
- gen_im = (self.synthesis(latent_in, noise)+1)/2
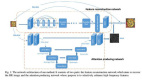
根據原始的低分辨率圖像和生成的高分辨率圖像計算loss。在代碼中,loss由兩個部分組成:
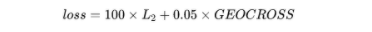
其中L2損失是將生成的高分辨率圖像gen_im通過bicubic下采樣恢復LR,并與輸入的LR計算pixel-wise誤差,GEOCROSS是測地線距離。
最后優化器選擇的是球面優化器:
- # opt = SphericalOptimizer(torch.optim.Adam, [x], lr=0.01)
- class SphericalOptimizer(Optimizer):
- def __init__(self, optimizer, params, **kwargs):
- self.opt = optimizer(params, **kwargs)
- self.params = params
- with torch.no_grad():
- self.radii = {param: (param.pow(2).sum(tuple(range(2,param.ndim)),keepdim=True)+1e-9).sqrt() for param in params}
- @torch.no_grad()
- def step(self, closure=None):
- loss = self.opt.step(closure)
- for param in self.params:
- param.data.div_((param.pow(2).sum(tuple(range(2,param.ndim)),keepdim=True)+1e-9).sqrt())
- param.mul_(self.radii[param])
- return loss
3. Result

從結果可以看出,PULSE生成的圖像細節更豐富,包括頭發絲、眼睛和牙齒這些比較細微的地方都能生成的很好。而且對于有噪聲的LR,也能生成的很好,說明該算法有很強的魯棒性:

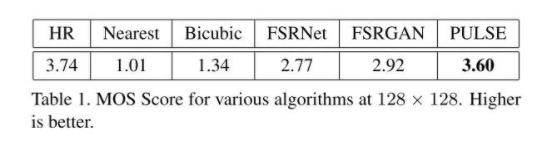
最終的比較指標采用的是MOS:
4. Questions
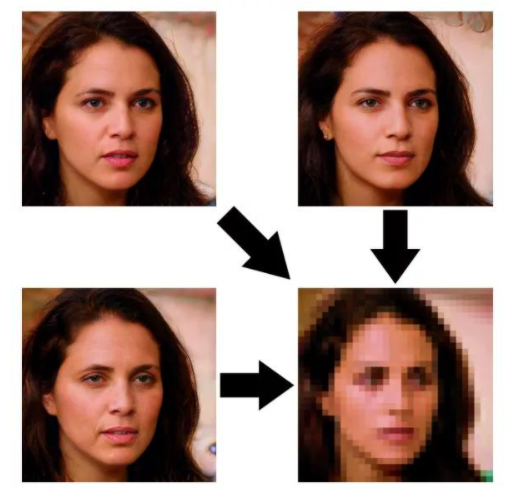
PULSE是一個無監督的圖像超分辨率模型,其圖像的質量其實很大程度上取決于所選取的生成模型的好壞。另一方面,由于PULSE的基礎原理就是找到一個高分辨率的圖像,使其下采樣之后能恢復LR,那么意味著結果不唯一,可能生成的圖像很清楚,但是已經失去了身份信息:
5. Resource
PaperPULSE:https://arxiv.org/pdf/2003.03808.pdfStyleGAN: https://arxiv.org/abs/1812.04948Random Vectors in High Dimen- sions: https://www.sci-hub.ren/10.1017/9781108231596.006
Github: https://github.com/adamian98/pulse.git