人臉超分辨率,基于迭代合作的方法
分享一篇 2020CVPR 錄用論文:Deep Face Super-Resolution with Iterative Collaboration between Attentive Recovery and Landmark Estimation,其提出了一種基于迭代合作的人臉超分辨算法。
該方法將 16x16 的低分辨率圖片超分辨率為 128x128,在 CelebA 和 Helen數據集上的 PSNR 指標分別達到了 27.37 和 26.69,超過了當前已有的人臉超分辨率算法。
目前代碼已經開源:
https://github.com/Maclory/Deep-Iterative-Collaboration
(目前已有72星標)
論文作者信息:

作者來自清華大學自動化學院、智能技術與系統國家重點實驗室、北京信息科學與技術國家研究中心和清華大學深圳國際研究生院。
01
Motivation
在以往的一些人臉超分辨率算法中,人臉先驗信息(facial prior)如面部關鍵點通常被引入,用于輔助網絡生成更加真實的超分辨率圖像。但是這些方法存在兩個問題:
- 通過低分辨率圖片LR或者粗超分辨率圖片SR得到的人臉先驗信息不一定準確
- 大部分方法使用人臉先驗的方式為簡單的 concatenate 操作,不能充分利用先驗信息
為了解決上述的兩個問題,作者提出了一個基于迭代合作的人臉超分辨率算法DIC,為了讓生成的圖片更加真實,也給出了該網絡的 GAN 版本:DICGAN。
02
Method
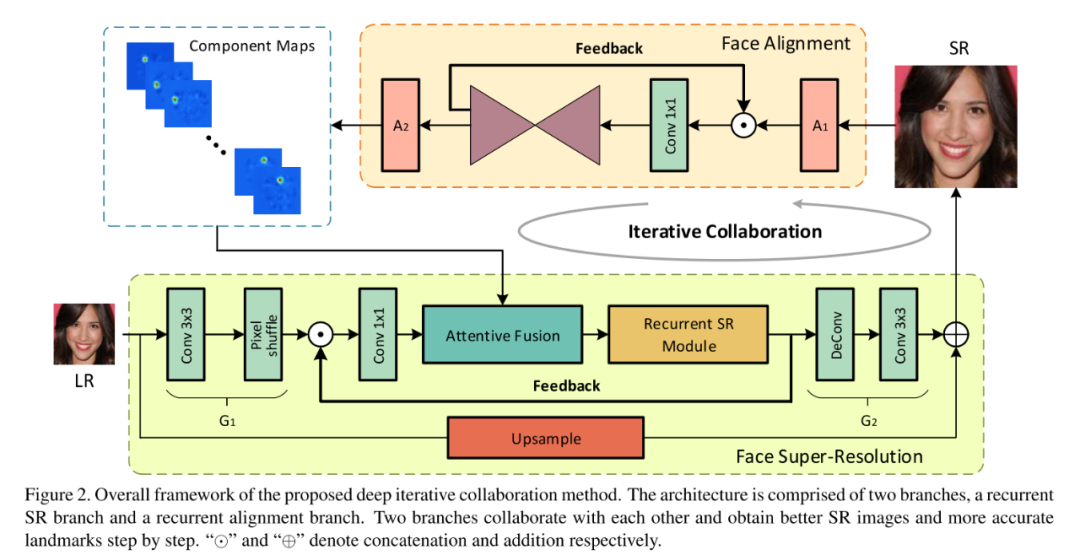
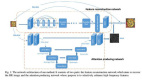
從網絡結構圖可以看出,為了解決先驗網絡不能從 coarse SR 中得到準確的先驗信息,作者設計了一個反饋迭代網絡,,使得生產的超分辨率圖片越來越趨近于真實圖片,而更加真實的圖片通過先驗網絡可以提取更加準確的先驗信息以再次提升圖片的質量。
下圖展示了該迭代的機制的優勢,隨著迭代次數的增加,關鍵點預測的也越來越準確,生成的圖像質量也越來越好。作者也通過實驗證明了,當迭代次數超過 3次時,網絡性能的提升有限。
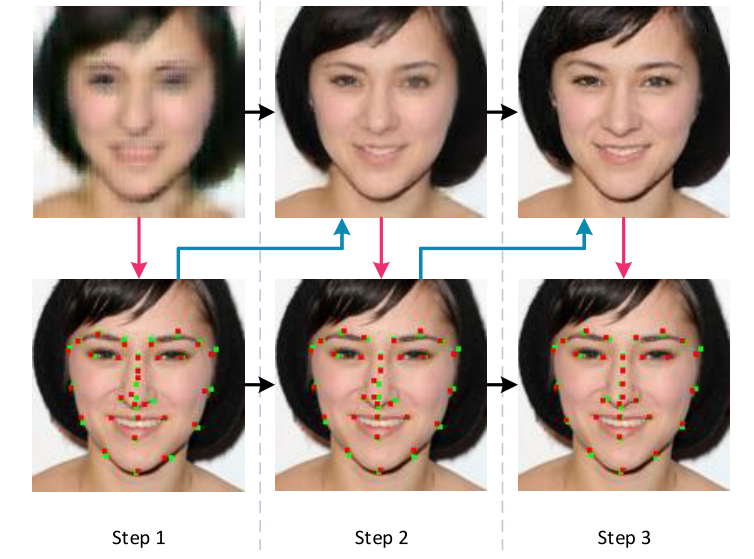

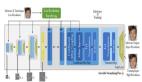
另一方面,為了充分利用人臉先驗信息,作者提出了一個 Attentive Fusion 模塊如下圖所示:
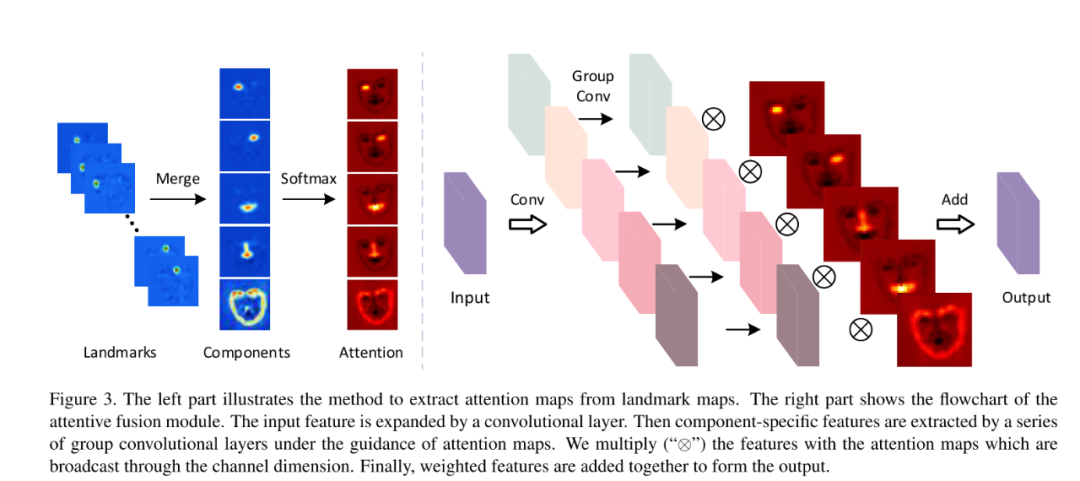
可以看出,作者將面部關鍵點預測網絡(網絡結構圖中的 Face Alignment 模塊)輸出的特征圖分成五組:左眼、右眼、嘴、鼻子和面部輪廓。再將每個組的特征圖通過 softmax 后相加得到每個注意力矩陣(Attention matrix)。
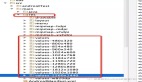
用這 5 個注意力矩陣分別去 reweight 網絡中的五個分支的 feature maps,再加在一起得到融合特征。那么作者如何確定關鍵點預測網絡輸出的特征圖那幾個channel 是左眼,哪些 channel 是右眼呢?從作者開源的代碼中可以看出,這些 channel 是人為指定的,如規定第 32 到第 41 個通道是左眼的關鍵點。
- if heatmap.size(1) == 5:
- return heatmap.detach() if detach else heatmap
- elif heatmap.size(1) == 68:
- new_heatmap = torch.zeros_like(heatmap[:, :5])
- new_heatmap[:, 0] = heatmap[:, 36:42].sum(1) # left eye
- new_heatmap[:, 1] = heatmap[:, 42:48].sum(1) # right eye
- new_heatmap[:, 2] = heatmap[:, 27:36].sum(1) # nose
- new_heatmap[:, 3] = heatmap[:, 48:68].sum(1) # mouse
- new_heatmap[:, 4] = heatmap[:, :27].sum(1) # face silhouette
- return new_heatmap.detach() if detach else new_heatmap
- elif heatmap.size(1) == 194: # Helen
- new_heatmap = torch.zeros_like(heatmap[:, :5])
- tmp_id = torch.cat((torch.arange(134, 153), torch.arange(174, 193)))
- new_heatmap[:, 0] = heatmap[:, tmp_id].sum(1) # left eye
- tmp_id = torch.cat((torch.arange(114, 133), torch.arange(154, 173)))
- new_heatmap[:, 1] = heatmap[:, tmp_id].sum(1) # right eye
- tmp_id = torch.arange(41, 57)
- new_heatmap[:, 2] = heatmap[:, tmp_id].sum(1) # nose
- tmp_id = torch.arange(58, 113)
- new_heatmap[:, 3] = heatmap[:, tmp_id].sum(1) # mouse
- tmp_id = torch.arange(0, 40)
- new_heatmap[:, 4] = heatmap[:, tmp_id].sum(1) # face silhouette
- return new_heatmap.detach() if detach else new_heatmap
- else:
- raise NotImplementedError('Fusion for face landmark number %d not implemented!' % heatmap.size(1))
以上就是本篇論文最為核心的兩個創新點。了解了整個網絡運行的原理之后,網絡的損失函數就很好理解了:


03
Result
下圖為 DIC/DICGAN 與其他方法的結果對比圖:
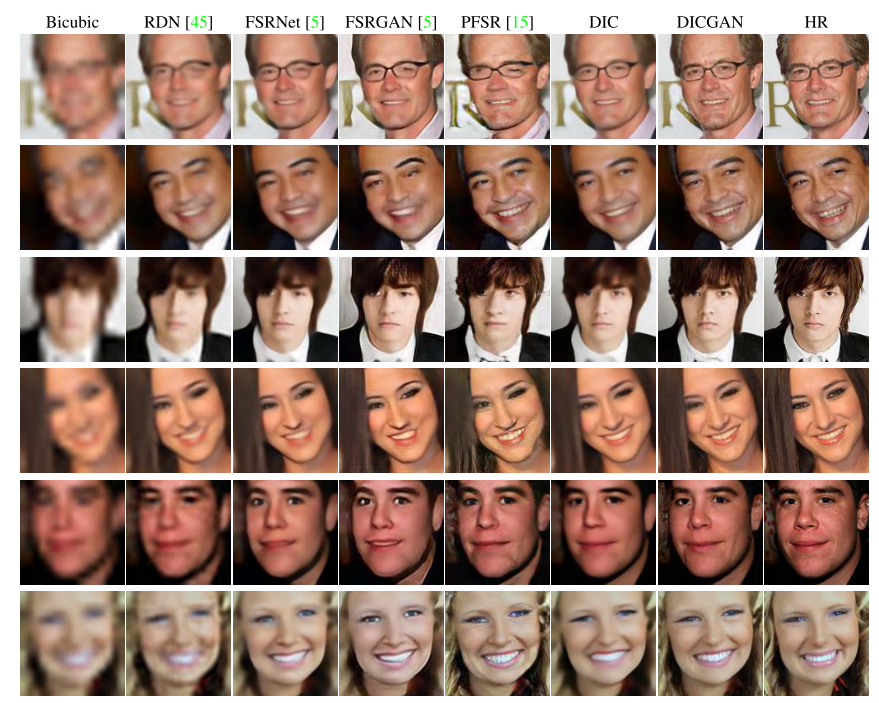
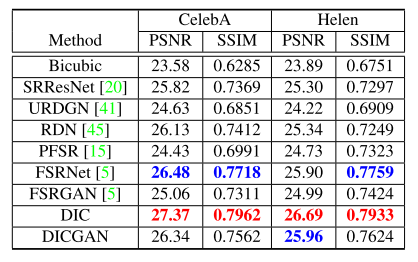
可以看出 DIC/DICGAN 生成的圖片恢復了更多的細節,更加真實。由于DICGAN 是基于 GAN 的方法,相較于基于 PSNR 方法的 FSRNet,指標略低,但是生成的圖像更加真實。這也是當前超分辨率任務中存在的一個問題:基于 GAN 的方法生成的圖像視覺質量更好,但是 PSNR 指標低。
04
Resource
- 論文鏈接:https://arxiv.org/pdf/2003.13063.pdf
- 項目鏈接:https://github.com/Maclory/Deep-Iterative-Collaboration