













圖圖的存儲(chǔ)、BFS、DFS(聽說疊詞很可愛)
1. 基本概念
圖的基本概念中我們需要掌握的有這么幾個(gè)概念:無向圖、有向圖、帶權(quán)圖;頂點(diǎn)(vertex);邊(edge);度(degree)、出度、入度。下面我們就從無向圖開始講解這幾個(gè)概念。
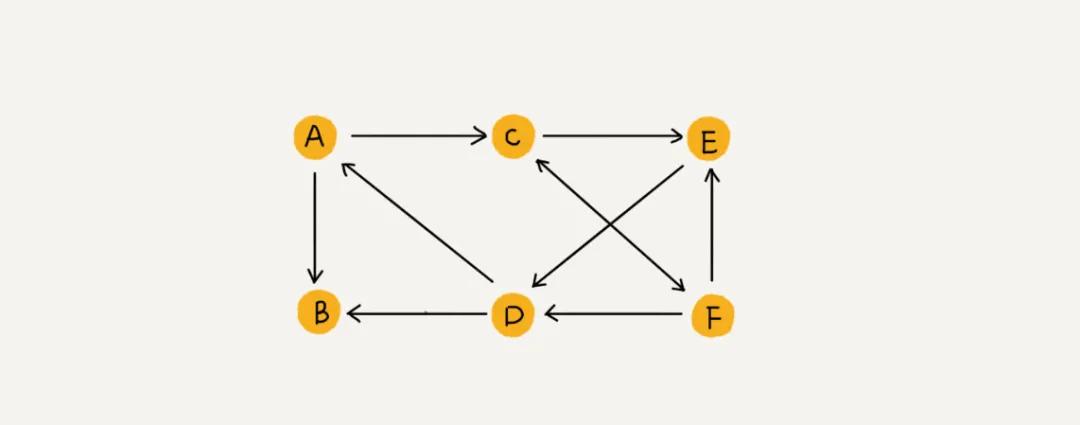
如圖所示是一個(gè)無向圖,圖中的元素(A、B、C、D、E、F)被稱為頂點(diǎn)(vertex),頂點(diǎn)可以與任意頂點(diǎn)建立連接關(guān)系,這種關(guān)系叫做邊(edge),無向圖中邊是沒有方向的。頂點(diǎn)相連接的邊的條數(shù)就被稱為度(degree),圖中頂點(diǎn) A 的度就是 3 。

還有一種圖,圖中的邊是有方向的,如圖所示,則將這種圖稱為有向圖。度這種概念在有向圖中又被擴(kuò)展為入度和出度。頂點(diǎn)的入度是指有多少條邊指向這個(gè)頂點(diǎn);頂點(diǎn)的出度指有多少條邊以這個(gè)頂點(diǎn)為起點(diǎn)。
上述的邊都沒有權(quán)重,假如我們要拿一個(gè)圖來存儲(chǔ)地圖數(shù)據(jù)的話,圖中的邊還需要表示距離,那么這個(gè)圖就變成了帶權(quán)圖(weighted graph)。在帶權(quán)圖中,每條邊都有一個(gè)權(quán)重,這個(gè)權(quán)重可以表示距離。

★綜上來看的,圖的類型主要是根據(jù)邊的類型來決定的。”
2. 圖的存儲(chǔ)
圖的基本概念不多,那么在計(jì)算機(jī)中我們該如何存儲(chǔ)圖這種數(shù)據(jù)結(jié)構(gòu)呢?主要有兩種方式來存儲(chǔ)圖,一種是鄰接矩陣的方法,另一種是鄰接表的方式。
2.1. 鄰接矩陣
鄰接矩陣是圖最直觀的一種存儲(chǔ)方式,底層依賴于二維數(shù)組。
- 對(duì)于無向圖來說,如果頂點(diǎn) i 和頂點(diǎn) j 之間有邊那么則將 A[i][j] 和 A[j][i] 標(biāo)記為 1
- 對(duì)于有向圖來說,如果頂點(diǎn) i 有一條邊指向頂點(diǎn) j,但是頂點(diǎn) j 沒有一條邊指向頂點(diǎn) i,那么則將 A[i][j] 標(biāo)記為 1,但是 A[j][i] 不用標(biāo)記為 1。
- 對(duì)于帶權(quán)圖來說,只是從存儲(chǔ) 1 變成存儲(chǔ)具體的權(quán)重。

- 鄰接矩陣的缺點(diǎn)是在表示一個(gè)圖時(shí)通常很浪費(fèi)存儲(chǔ)空間。
對(duì)于無向圖來說,它是一個(gè)對(duì)稱矩陣,即 A[i][j] 等于 1 的話,那么 A[j][i] 也等于 1。那么實(shí)際上只要存儲(chǔ)一半就可以了。
另外,假如存儲(chǔ)的是稀疏圖,也就是頂點(diǎn)很多,但是每個(gè)頂點(diǎn)的邊不多的一種圖。那么使用鄰接矩陣存儲(chǔ)將更浪費(fèi)存儲(chǔ)空間,因?yàn)楹芏辔恢玫闹刀际?0,這些 0 其實(shí)都是沒有用的。
- 鄰接矩陣的優(yōu)點(diǎn)就是存儲(chǔ)方式簡單、直觀,而且獲取兩個(gè)頂點(diǎn)的關(guān)系時(shí)非常高效。另外,使用鄰接矩陣時(shí),在計(jì)算上也很方便。因?yàn)楹芏鄨D的運(yùn)算實(shí)際上可以轉(zhuǎn)換為矩陣的運(yùn)算,比如求最短路徑問題時(shí)會(huì)提到一個(gè) Floyd-Warshall 算法,這個(gè)算法會(huì)利用到矩陣循環(huán)相乘若干次的結(jié)果。
2.2. 鄰接表
圖的另一種存儲(chǔ)方法,是使用鄰接表(Adjacency List)。如圖所示,有向圖中的每個(gè)頂點(diǎn)對(duì)應(yīng)一個(gè)鏈表,該鏈表中存儲(chǔ)的是該頂點(diǎn)指向的頂點(diǎn)。對(duì)于無向圖來說是類似的,每個(gè)節(jié)點(diǎn)對(duì)應(yīng)的鏈表中存儲(chǔ)的是該節(jié)點(diǎn)所相連的頂點(diǎn)。
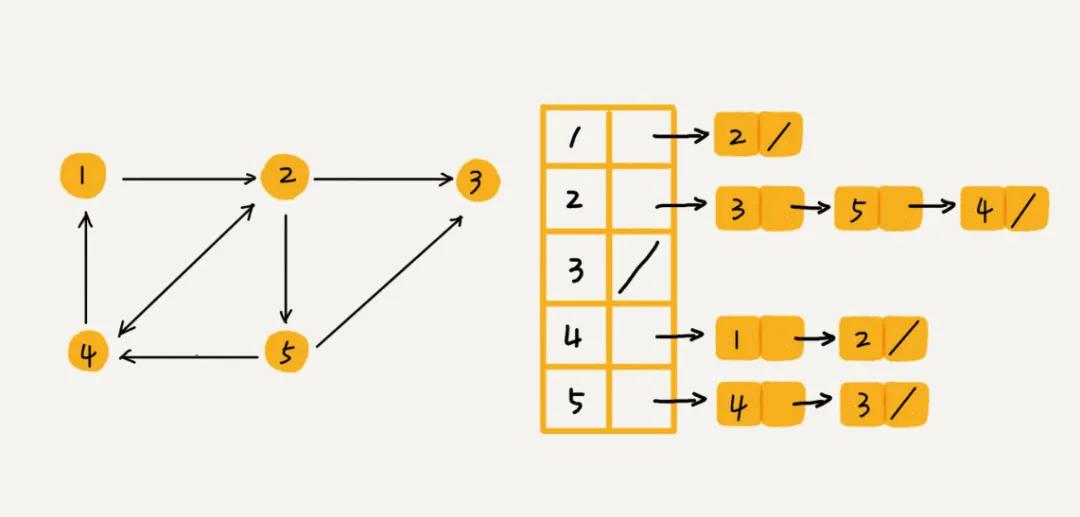
- 鄰接表相比鄰接矩陣的一個(gè)優(yōu)點(diǎn)就是節(jié)省空間,但是使用起來比較耗時(shí)間(時(shí)間換空間的設(shè)計(jì)思想)。在使用鄰接矩陣判斷無向圖中 i 和 j 之間是否存在一條邊,那么只需要判斷 A[i][j] 是否為 1,而在鄰接表中判斷無向圖中 i 和 j 之間是否存在一條邊,那么需要判斷 i 這個(gè)頂點(diǎn)對(duì)應(yīng)的鏈表中是否存在 j。而且鏈表的方式對(duì)于緩存來說不太友好。所以,綜上來說在鄰接表中查詢兩個(gè)頂點(diǎn)的關(guān)系沒有鄰接矩陣那么高效了。
- 但是,為了讓查詢變得更加高效。我們可以參考散列表中提到的那樣,將鏈表換成平衡二叉查找樹(比如紅黑樹),或者其他動(dòng)態(tài)數(shù)據(jù)結(jié)構(gòu),比如跳表、散列表,有序動(dòng)態(tài)數(shù)組(結(jié)合二分查找)等。
逆鄰接表
鄰接表中存儲(chǔ)的是這個(gè)頂點(diǎn)指向的頂點(diǎn),那么逆鄰接表中存儲(chǔ)的是指向這個(gè)頂點(diǎn)的頂點(diǎn)。比如要想查看 4 這個(gè)頂點(diǎn)指向了哪些節(jié)點(diǎn)就可以使用鄰接表。但是想要查看有哪些節(jié)點(diǎn)指向了 4 這個(gè)頂點(diǎn),那么就需要逆鄰接表了。

2.3. 總結(jié)
綜上來說,鄰接矩陣的缺點(diǎn)是比較浪費(fèi)空間,但是優(yōu)點(diǎn)是查詢效率高,還方便矩陣運(yùn)算。鄰接表的優(yōu)點(diǎn)是節(jié)省存儲(chǔ)空間,但是不方便查找(查找效率肯定沒鄰接矩陣高)。對(duì)于此,我們可以將鏈表替換成查詢效率較高的動(dòng)態(tài)數(shù)據(jù)結(jié)構(gòu),比如平衡二叉樹(紅黑樹)、跳表、散列表等。
3. 圖的搜索
圖上的搜索算法,最直接的理解就是,在圖中找出從一個(gè)頂點(diǎn)出發(fā),到另一個(gè)頂點(diǎn)的路徑。具體方法有很多,比如有最簡單、最“暴力”的深度優(yōu)先、廣度優(yōu)先搜索,還有 A*、IDA* 等啟發(fā)式搜索算法。深度優(yōu)先、廣度優(yōu)先搜索即可以用在有向圖,也可以用在無向圖上。下面的實(shí)現(xiàn)以無向圖和鄰接表的存儲(chǔ)方式為例。
3.1. 廣度優(yōu)先搜索(Breath-First-Search)
廣度優(yōu)先搜索,簡稱 BFS。這種搜索方法是一層層的向外搜索,先從起點(diǎn)開始,然后再搜索離起點(diǎn)最近的頂點(diǎn);之后再從離起點(diǎn)最近的頂點(diǎn)出發(fā)搜索離這些頂點(diǎn)最近的頂點(diǎn)。整個(gè)過程示意圖如圖所示,跟二叉樹的層次遍歷是一樣的。
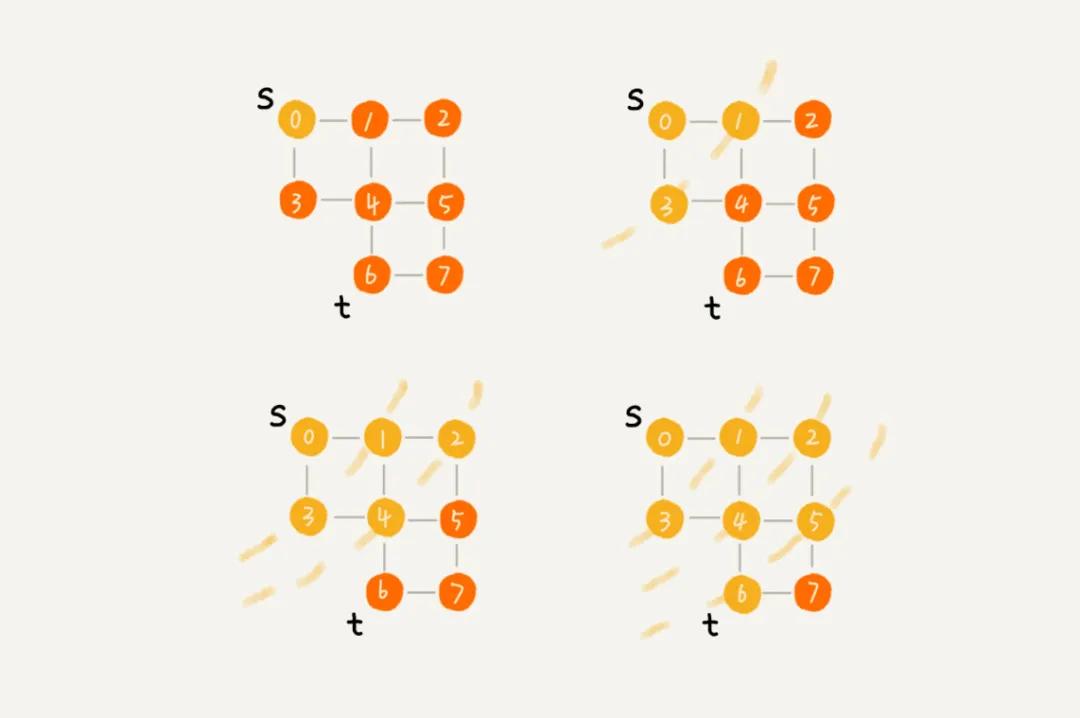
相應(yīng)的代碼實(shí)現(xiàn),如下代碼所示。from 表示起點(diǎn),to 表示終點(diǎn)。和層次遍歷一樣,廣度優(yōu)先搜索使用了隊(duì)列這種數(shù)據(jù)結(jié)構(gòu)。隊(duì)列主要用來存儲(chǔ)那些已經(jīng)被訪問,但是相鄰的頂點(diǎn)還沒有被訪問的頂點(diǎn)。為什么使用隊(duì)列這種數(shù)據(jù)結(jié)構(gòu)呢?從應(yīng)用場景出發(fā),因?yàn)閺V度優(yōu)先搜索方法是逐層訪問的。也就是先訪問 k 層的頂點(diǎn),訪問之后再去訪問 k+1 層的頂點(diǎn)。但是,在訪問第 k 層頂點(diǎn)的時(shí)候需要將 k+1 層的頂點(diǎn)也保存下來,而且 k+1 層頂點(diǎn)是在第 k 層頂點(diǎn)之后被訪問并從隊(duì)列中退出,也就相當(dāng)于 “后來后出”。
但是,相比層次遍歷又多一些內(nèi)容,主要多出的是 visited 和 paths 這兩個(gè)數(shù)組,visited 數(shù)組主要是用來存儲(chǔ)頂點(diǎn)是否已經(jīng)被訪問過了,因?yàn)閳D相比樹更為復(fù)雜,有些頂點(diǎn)會(huì)有多個(gè)相鄰頂點(diǎn)。為了避免頂點(diǎn)被重復(fù)訪問,所以借用了一個(gè)數(shù)組。
paths 數(shù)組主要用來記錄從 from 到 to 的廣度搜索路徑,但是每個(gè)數(shù)組元素(數(shù)組下標(biāo)即頂點(diǎn)編號(hào))只存儲(chǔ)該頂點(diǎn)前面的那個(gè)頂點(diǎn),比如 paths[3] 存儲(chǔ) 2,則表示是先訪問到 2 ,然后從 2 再訪問到 3。這樣的存儲(chǔ)方式是逆向的,為了正向地輸出搜索路徑,可以使用遞歸的方式,遞歸的時(shí)候?qū)⑤敵龇胖玫竭f歸之后。因?yàn)橹挥械惹懊娴捻旤c(diǎn)遞歸完成之后,再輸出本頂點(diǎn),才是正向的路徑。
- public void bfsSearch(int from, int to) {
- if (this.v == 0 || from == to) {
- return;
- }
- boolean[] visited = new boolean[this.v];
- int[] paths = new int[this.v]; // 記錄路徑,記錄該節(jié)點(diǎn)前面的節(jié)點(diǎn)是哪個(gè)
- for (int i = 0; i < this.v; i++) {
- visited[i] = false;
- paths[i] = -1;
- }
- Queue<Integer> queue = new LinkedList<>();
- queue.offer(from);
- visited[from] = true;
- while (!queue.isEmpty()) {
- int w = queue.poll();
- for (Integer i : this.adj[w]) {
- if (!visited[i]) {
- queue.offer(i);
- visited[i] = true;
- paths[i] = w;
- if (i == to) {
- printPath(paths, to);
- break;
- }
- }
- }
- }
- }
★另外,需要明白的是在沒有權(quán)重的圖中,廣度優(yōu)先搜索的結(jié)果就是最短路徑。這個(gè)是因?yàn)閺V度優(yōu)先搜索的方式中,每次都是取最近的節(jié)點(diǎn),那么當(dāng)?shù)竭_(dá)終點(diǎn)時(shí),其實(shí)所需次數(shù)是最少的。”
時(shí)間復(fù)雜度
廣度優(yōu)先搜索的時(shí)間復(fù)雜度最壞是遍歷整個(gè)圖,那么此時(shí)每個(gè)頂點(diǎn)都會(huì)被遍歷到,每條邊也會(huì)被訪問一次。那么,假設(shè)邊數(shù)為 E,頂點(diǎn)數(shù)為 V,此時(shí)時(shí)間復(fù)雜度為 O(V+E)(針對(duì)鄰接表來說)。
空間復(fù)雜度
廣度優(yōu)先搜索時(shí),空間復(fù)雜度主要來自于隊(duì)列、visited 數(shù)組、paths 數(shù)組。這些數(shù)組的大小最大為 V,因?yàn)榭臻g復(fù)雜度是 O(V)。
3.2. 深度優(yōu)先搜索(Depth-First-Search)
深度優(yōu)先搜索,簡稱 DFS。怎么直觀的理解呢?就是你從一個(gè)頂點(diǎn)出發(fā),假如這個(gè)頂點(diǎn)有未被訪問過的頂點(diǎn)則訪問它,然后一個(gè)一個(gè)這么套下去。當(dāng)一個(gè)頂點(diǎn)的相鄰頂點(diǎn)都被訪問過了,那么則退回上一個(gè)頂點(diǎn),然后看一下上一個(gè)頂點(diǎn)是否有未被訪問過的鄰接頂點(diǎn),有的話則訪問它,然后一層一層下去。如果也都被訪問過了,那么則再退。一個(gè)典型的生活中的例子就是走迷宮,先一條道走到“黑”,然后看不到出口了,上一個(gè)分叉口再換條道。
如圖所示,這是在圖上采用深度優(yōu)先搜索之后的樣子,實(shí)現(xiàn)表示搜索方向,虛線表示回退。
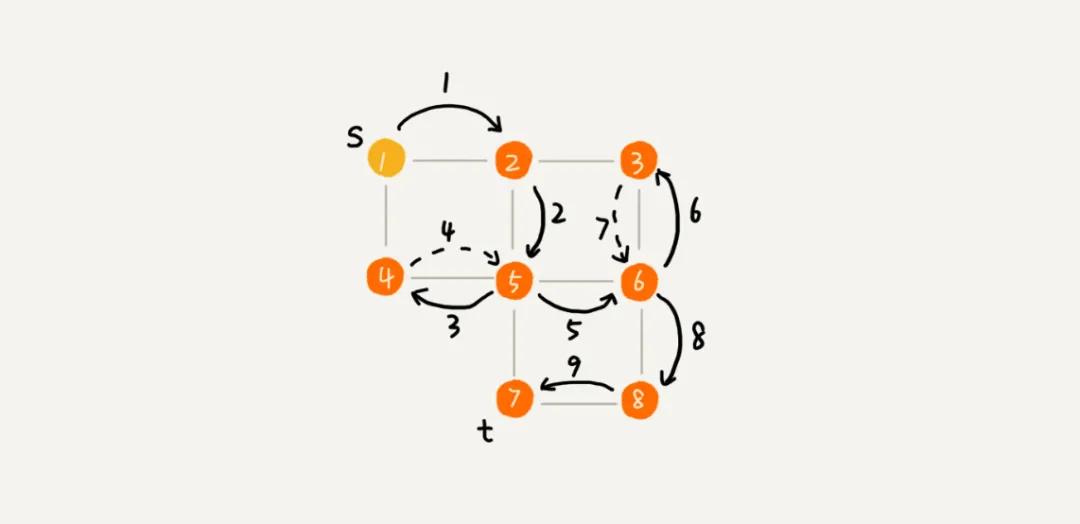
深度優(yōu)先搜索采用的思想是回溯思想,這種思想比較適合使用遞歸。我們使用遞歸的方式實(shí)現(xiàn)一下 DFS。相比 BFS,DFS 多了一個(gè) find 變量,這個(gè)變量用于判斷是否有找到頂點(diǎn)的。如果在沒有遍歷到一個(gè)頂點(diǎn)的最后一個(gè)鄰接頂點(diǎn)之前就找到了終點(diǎn),那么接下去的鄰接頂點(diǎn)就可以不用遍歷了,直接返回即可。
- public void dfsSearch(int from, int to) {
- if (this.v == 0 || from == to) {
- return;
- }
- boolean[] visited = new boolean[this.v];
- int[] paths = new int[this.v];
- for (int i = 0; i < this.v; i++) {
- visited[i] = false;
- paths[i] = -1;
- }
- visited[from] = true;
- reDFSS(from, to, visited, paths);
- if (this.FIND_DFS == true) {
- printPath(paths, to);
- }
- }
- public void reDFSS(int from, int to, boolean[] visited, int[] paths) {
- if (from == to) {
- this.FIND_DFS = true;
- return;
- }
- for (Integer i : this.adj[from]) {
- if (this.FIND_DFS) {
- return;
- }
- if (!visited[i]) {
- visited[i] = true;
- paths[i] = from;
- reDFSS(i, to, visited, paths);
- }
- }
- }
除了使用遞歸的方式實(shí)現(xiàn)之外,還可以將遞歸的方式轉(zhuǎn)化成棧和循環(huán)結(jié)合的方式。在圖的遍歷這小節(jié)內(nèi)容,你會(huì)看到非遞歸的方式。
★深度優(yōu)先搜索找到的并不是最短路徑。”
時(shí)間復(fù)雜度
采用同樣的方法,從頂點(diǎn)和邊的被訪問次數(shù)出發(fā),每條邊最多被兩次訪問(一次遍歷,一次回退),每個(gè)頂點(diǎn)被訪問一次,那么時(shí)間復(fù)雜度是 O(V+E)(針對(duì)鄰接表來說)。
空間復(fù)雜度
同樣的,深度優(yōu)先搜索的方式的空間復(fù)雜度主要來源棧、visited 數(shù)組和 paths 數(shù)組,棧的長度不可能超過頂點(diǎn)的個(gè)數(shù),因此空間復(fù)雜度還是 O(V)。
3.3. 總結(jié)
- 廣度和深度相比其他高級(jí)搜索算法(比如 A*算法)更簡單粗暴,沒有什么優(yōu)化,也被稱為暴力搜索算法。這兩種算法適用于圖不大的情況。
- 深度優(yōu)先搜索主要借助了棧的方式,這個(gè)棧可以是函數(shù)調(diào)用棧也可以是棧這種數(shù)據(jù)結(jié)構(gòu)(因?yàn)檫f歸也可以轉(zhuǎn)化為非遞歸的方式)。廣度優(yōu)先搜索主要使用隊(duì)列。
- 圖和樹的比較,圖的 DFS 類似于樹的先序遍歷;BFS 類似于樹的層次遍歷。
- 在沒有權(quán)重的圖中,BFS 搜索的路徑結(jié)果就是最短路徑;DFS 搜索的結(jié)果卻不一定,因?yàn)?DFS 會(huì)“繞來繞去”,而 BFS 很直接每次都是最近的。
- 在求圖的時(shí)間復(fù)雜度時(shí),常用的方法是從頂點(diǎn)和邊被遍歷的次數(shù)出發(fā)。
4. 圖的遍歷
與圖的搜索算法有點(diǎn)不同的是,圖的遍歷是指將圖中的所有點(diǎn)都遍歷一次。常見的遍歷方法有深度優(yōu)先遍歷和廣度優(yōu)先遍歷。這兩種遍歷方法的思想還是一樣的,簡單來說就是圖的搜索方法就是加了一個(gè)節(jié)點(diǎn)判斷,如果找到相應(yīng)的節(jié)點(diǎn)就停止搜索。下面直接給出相應(yīng)的代碼,不再贅述。
4.1. 廣度優(yōu)先遍歷
- public void bfsTraversal() {
- if (this.v == 0) {
- return;
- }
- boolean[] visited = new boolean[this.v];
- for (int i = 0; i < this.v; i++) {
- visited[i] = false;
- }
- Queue<Integer> queue = new LinkedList<>();
- queue.offer(0);
- visited[0] = true;
- while (!queue.isEmpty()) {
- int w = queue.poll();
- System.out.print(w + "\t");
- for (Integer i : this.adj[w]) {
- if (visited[i] == false) {
- queue.offer(i);
- visited[i] = true;
- }
- }
- }
- }
4.2. 深度優(yōu)先遍歷
- // 遞歸的方式
- public void dfsTraversal() {
- if (this.v == 0) {
- return;
- }
- boolean[] visited = new boolean[this.v];
- for (int i = 0; i < this.v; i++) {
- visited[i] = false;
- }
- for (int i = 0; i < this.v; i++) {
- if (!visited[i]) {
- reDFST(i, visited);
- }
- }
- }
- public void reDFST(int f, boolean[] visited) {
- visited[f] = true;
- System.out.print(f + "\t");
- for (Integer i : this.adj[f]) {
- if(!visited[i]) {
- reDFST(i, visited);
- }
- }
- }
- // 非遞歸的方式,使用了棧
- public void dfsTraversalStack() {
- if (this.v == 0) {
- return;
- }
- boolean[] visited = new boolean[this.v];
- for (int i = 0; i < this.v; i++) {
- visited[i] = false;
- }
- Stack<Integer> stack = new Stack<>();
- stack.push(0);
- visited[0] = true;
- System.out.print(0 + "\t");
- while (!stack.isEmpty()) {
- int w = stack.peek();
- int flag = 0;
- for (Integer i : this.adj[w]) {
- if (!visited[i]) {
- stack.push(i);
- visited[i] = true;
- System.out.print(i + "\t");
- flag = 1;
- break;
- }
- }
- if (flag == 0) {
- stack.pop();
- }
- }
- }
本文轉(zhuǎn)載自微信公眾號(hào)「多選參數(shù)」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系多選參數(shù)公眾號(hào)。












