5張圖帶你了解Pulsar的存儲引擎BookKeeper
本文轉載自微信公眾號「程序員jinjunzhu」,作者 jinjunzhu。轉載本文請聯系程序員jinjunzhu公眾號。
Apache BookKeeper是一款企業級存儲系統,最初由雅虎研究院研發,在2011年作為Apache ZooKeeper的子項目進行孵化,在2015年1月成為 Apache頂級項目。
起初,BookKeeper是一個預寫日志(WAL)系統,經過幾年的發展,BookKeeper的功能更加完善,比如為Hadoop分布式文件系統(HDFS)的NameNode提供高可用和多副本,為消息系統比Pulsar提供存儲服務,為多個數據中心提供跨機器復制。
1 使用場景
BookKeeper最初的一個使用場景是為HDFS的NameNode保存edit log,如下圖:
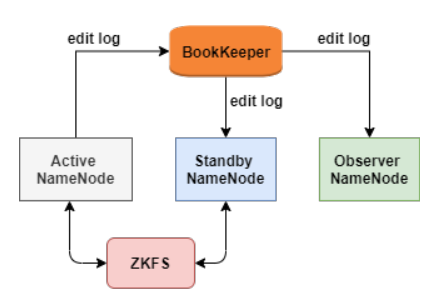
ZKFC是一個Zookeeper的客戶端,主要用來監測和管理NameNode狀態,每個NameNode機器上都會運行一個ZKFC,它的職責主要有三個:
- 健康檢查
- Zookeeper會話管理
- 選舉,當集群中一個Active NameNode宕機,Zookeeper會自動選擇一個節點作為新的Active NameNode。
BookKeeper記錄NameNode的edit log(edit log存放文件系統的操作日志),NameNode的所有修改都會記錄到BookKeeper。這樣active NameNode宕機后,BookKeeper用保存的edit log去standby NameNode做回放,之后切換成active NameNode。
BookKeeper具有如下特性:
- 一致性:因為edit log保存的是HDFS的元數據,對一致性要求很高
- 低延遲:為了不丟數據,需要低延遲
- 高吞吐:為了支持更多的NameNode節點,需要高吞吐
2 節點對等
Bookie中保存的數據結構如下圖:
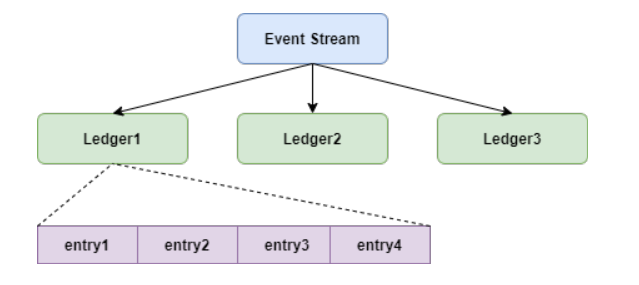
writer寫數據時,把entry并發寫入多個bookie節點的Ledger。這類似于文件系統寫數據時首先會打開一個文件,如果文件不存在,則會創建文件元數據。
Ledger也就是Pulsar中的segment。
writer寫數據時,首先會打開一個新Ledger,函數如下:
- openLedger(組內節點數目、數據備份數目、等待刷盤節點數目)
比如(5,3,2)代表組內共有5個Bookie節點,寫數據時需要寫入3個節點,有2個節點返回成功代表寫入成功。
這樣寫入的這3個節點數據完全一樣,關系是對等的,不存在主從關系。
2.1 數據讀寫
BookKeeper數據讀寫如下圖:
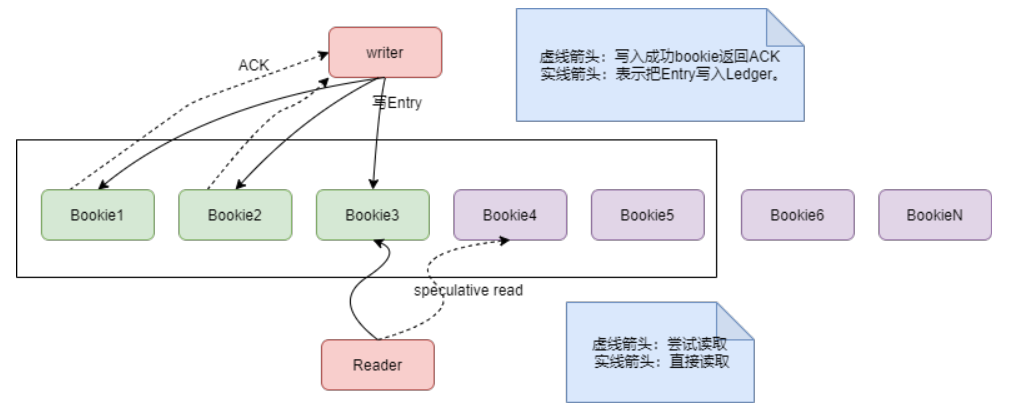
writer以roundrobin的方式寫入bookie,比如在上圖中,第一條數據寫入Bookie1、Bookie2和Bookie3,第二條數據寫入Bookie2、Bookie3、Bookie4,第三條數據寫入Bookie3、Bookie4、Bookie5,第四條數據寫入Bookie4、Bookie5和Bookie1。
在打開一個Ledger時,就傳入了bookie數量,這樣在寫每個entry時,就用entry的id跟bookie數量取模,來確定寫到哪幾個bookie上。比如第3條消息跟5取模是3,就寫到Bookie3、Bookie4和Bookie5。
這樣以輪詢的方式將Ledger數據寫入各個bookie節點,每個bookie節點的數據是均衡的,每個bookie節點的磁盤帶寬和網卡帶寬都能得到充分利用。
2.2 讀高可用
Reader在讀取數據時,可以讀取多份數據中的任意一份數據。BookKeeper會設置一個讀超時時間,如果讀取超時了,會給另外一個bookie節點(speculative read)發送讀請求。
2.3 寫高可用
如果某個bookie節點(比如bookie5)發生故障不能寫入了,BookKeeper會做如下處理:
- 記錄出錯的entry id
- 對故障節點的數據進行封裝
- 關閉當前的Ledger,重新打開一個新的Ledger,這個Ledger會重新選擇bookie節點,1、2、3、4、6。
- 如果bookie5恢復,就不再提供寫服務了,只提供讀服務。
- 如果不能恢復,就把bookie5的數據,從其他節點的備份中恢復到新的節點上,這個過程需要根據Ledger id跟5取模來判斷是否落到bookie5上,數據恢復過程并不影響Reader,因為其他兩份數據可以繼續提供服務。
3 I/O模型
BookKeeper的I/O模型如下圖,這個圖是單個bookie的數據流轉:
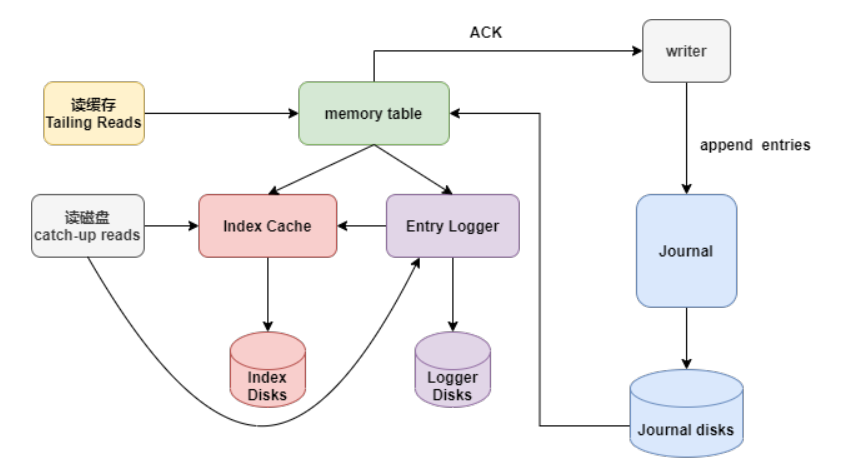
整個流程入下:
Writer寫入的數據首先到達Journal,Journal將數據進行group后刷到到Journal盤,這個刷盤的數據順序跟writer寫入順序一致。
Writer寫入Journal Disk是實時刷盤。
Journal Disk的數據會寫入memory table進行數據整理,把同一個topic的數據整理到一起。
把整理好的數據刷盤。Index Disk保存entry的index,對應entry在Logger Disks的offset。
3.1 讀寫分離
讀取數據時,首先從Memory Cache中讀取數據,如果數據不存在,才會去Index Disk和Logger Disk讀取數據。而寫數據是實時落盤到Journal Disk,這樣實現了讀寫隔離。
3.2 強一致性
數據可以實時刷盤到Journal Disk,保證了數據的強一致性。
3.3 靈活SLA
對于寫性能要求高的業務場景,可以單獨加強Journal盤性能,而對于讀性能要求高的場景,可以加強Ledger Disk和Index Disk的性能。
4 Pulsar中的使用
Pulsar的架構圖如下:
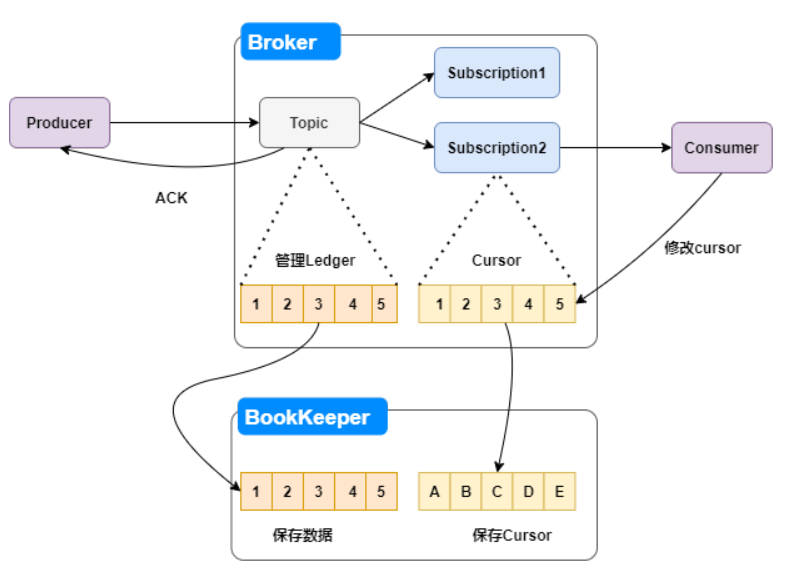
每次Producer生成的消息實時落盤后,給Producer返回一個ACK。
Consumer消費消息后,還會修改Cusor中保存的offset,并且也會記錄到BookKeeper。這樣保證了Cursor的一致性。