













Dfs、Bfs的終于弄明白了
本文轉(zhuǎn)載自微信公眾號(hào)「bigsai」,作者大賽。轉(zhuǎn)載本文請(qǐng)聯(lián)系bigsai公眾號(hào)。
前言
你問(wèn)一個(gè)人聽(tīng)過(guò)哪些算法,那么深度優(yōu)先搜索(dfs)和寬度優(yōu)先搜索(bfs)那肯定在其中,很多小老弟學(xué)會(huì)dfs和bfs就覺(jué)得好像懂算法了,無(wú)所不能,確實(shí)如此,學(xué)會(huì)dfs和bfs暴力搜索枚舉確實(shí)利用計(jì)算機(jī)超強(qiáng)計(jì)算大部分都能求的一份解,學(xué)會(huì)dfs和bfs去暴力杯混分是一個(gè)非常不錯(cuò)的選擇!
五大經(jīng)典算法的回溯算法其實(shí)也是dfs的一種應(yīng)用,是不是回憶起被折磨的八皇后問(wèn)題。基礎(chǔ)的dfs和bfs學(xué)習(xí)來(lái)思想很容易,寫(xiě)出來(lái)模板代碼也不難,但很多時(shí)候需要在此基礎(chǔ)上靈活變通就有不小難度了。
不過(guò)dfs 和bfs初步學(xué)習(xí)搞懂原理比較簡(jiǎn)單,但是想要精通 dfs和bfs還是很難的,因?yàn)楹芏鄦?wèn)題是在此基礎(chǔ)上進(jìn)行變形優(yōu)化的,比如dfs你可能考慮各種剪枝問(wèn)題,bfs可能會(huì)涉及很多貪心的策略,有的還要考慮到記憶化的問(wèn)題、雙向bfs、bfs+dfs等等才能更好解決的問(wèn)題,不過(guò)本文講的相對(duì)基礎(chǔ),不同的延伸需要自己刷題去學(xué)習(xí)才行。
鄰接矩陣和鄰接表
dfs和bfs一般用于處理圖論的問(wèn)題,那么在看問(wèn)題之前首先要關(guān)注圖的存儲(chǔ)問(wèn)題,正常一般用鄰接矩陣或者鄰接表存儲(chǔ)圖(對(duì)于十字鏈表、壓縮矩陣之類(lèi)空間優(yōu)化這里不進(jìn)行討論)。
鄰接矩陣:
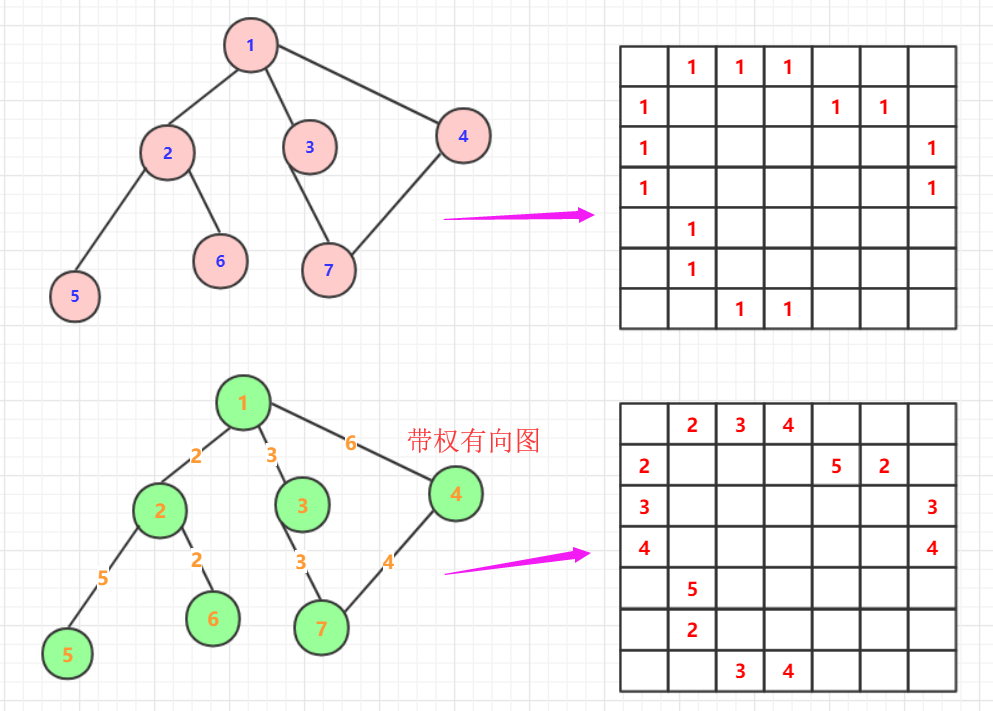
鄰接矩陣就是用數(shù)組(二維)表示圖,通常這種圖我們會(huì)對(duì)各個(gè)節(jié)點(diǎn)順序的編號(hào),在矩陣內(nèi)數(shù)值表示圖的聯(lián)通情況或者路徑長(zhǎng)度。
如果是無(wú)權(quán)圖:那么一般用boolean數(shù)組的01表示聯(lián)通性,如果是有權(quán)圖那么數(shù)組的值就用來(lái)表示兩者路徑長(zhǎng)度,如果為0那么就表示不通。另外如果圖是無(wú)向圖那么這個(gè)矩陣是對(duì)稱(chēng)的,如果是有向圖那么大概率不是對(duì)稱(chēng)的。
具體可以看下面例子,這種操作方式條理更清晰并且操作方便,當(dāng)然,這種情況很容易造成空間浪費(fèi),所以有人進(jìn)行空間優(yōu)化,或者是鄰接表的方式存儲(chǔ)圖。
鄰接表:
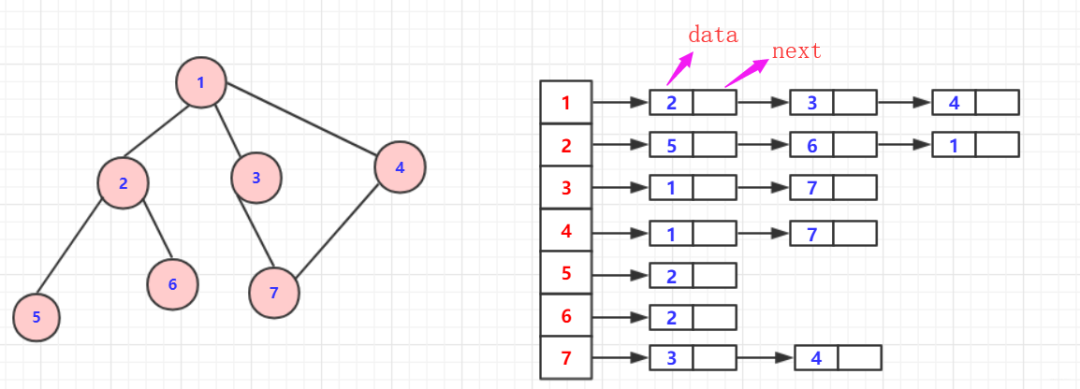
觀察上面的鄰接矩陣,如果節(jié)點(diǎn)很多但是聯(lián)通路徑很少,那么就浪費(fèi)了太多的存儲(chǔ)空間,這種情況就更適合鄰接表。
鄰接表一般是數(shù)組套鏈表,比起鄰接矩陣節(jié)省不少空間(直接存儲(chǔ)聯(lián)通信息或者路徑),在存儲(chǔ)的時(shí)候可以根據(jù)數(shù)據(jù)格式要求靈活運(yùn)用容器(無(wú)權(quán)圖省事一些)。
但是正常的無(wú)向圖依然會(huì)重復(fù)浪費(fèi)一半空間,就有十字鏈表,多重鏈接表等等出現(xiàn)優(yōu)化(大佬們的優(yōu)化是真的牛批),但在算法邏輯上稍復(fù)雜,不過(guò)一般圖論算法更注重的是算法的優(yōu)化這里就不介紹十字鏈表等,一個(gè)鄰接表存儲(chǔ)的圖可以看下圖:
深度優(yōu)先搜索(dfs)
概念:
深度優(yōu)先搜索屬于圖算法的一種,英文縮寫(xiě)為DFS即Depth First Search.其過(guò)程簡(jiǎn)要來(lái)說(shuō)是對(duì)每一個(gè)可能的分支路徑深入到不能再深入為止,而且每個(gè)節(jié)點(diǎn)只能訪(fǎng)問(wèn)一次.
簡(jiǎn)單的說(shuō),dfs就是在一個(gè)圖中按照一個(gè)規(guī)則進(jìn)行搜索,一般基于遞歸實(shí)現(xiàn),對(duì)于我們來(lái)說(shuō)dfs就像一個(gè)黑魔法一樣,設(shè)計(jì)好算法它就自動(dòng)搜索,所以我們要注意的是算法初始化、搜索規(guī)則、結(jié)束條件。二叉樹(shù)的前序遍歷就是一個(gè)最簡(jiǎn)單的dfs遍歷。
我們通常使用鄰接表或者鄰接矩陣儲(chǔ)存圖的信息,這里例子使用鄰接矩陣完成!
對(duì)于dfs的流程來(lái)說(shuō),大致可以認(rèn)為是這樣:
(1)某個(gè)節(jié)點(diǎn)開(kāi)始先按照一個(gè)方向一直遍歷到盡頭,同時(shí)標(biāo)記已經(jīng)走過(guò)的點(diǎn)。
(2)遍歷到盡頭后回退到上一個(gè)點(diǎn),同時(shí)清除當(dāng)前點(diǎn)的標(biāo)記。往下一個(gè)方向遍歷一次,然后繼續(xù)重復(fù)步驟(1).
(3)一直到所有流程都走完,即回退到起點(diǎn)。
在遍歷的過(guò)程中記得需要標(biāo)記 因?yàn)椴贿M(jìn)行標(biāo)記會(huì)出現(xiàn)死循環(huán),標(biāo)記就代表這個(gè)點(diǎn)被用過(guò)不能用了,而撤回標(biāo)記就說(shuō)明這個(gè)點(diǎn)又能重新使用了。
舉個(gè)例子,例如一個(gè)全排列s a i 當(dāng)s被枚舉到就要標(biāo)記這個(gè)s不能被使用(不可能ssss一直下去吧),并且遍歷到s a時(shí)候a也不能使用,到s a i 時(shí)候到盡頭回退 s a 依然要回退s 此時(shí) a和i都被解但是上次指標(biāo)方向?yàn)閍(for 循環(huán)到的位置),那么下一次就要往下個(gè)方向i 組成s i,然后在s i a,同理回退到s i,到s,下面兩個(gè)方向都被枚舉過(guò)所以還要回退到,解放了s a i但是第一個(gè)方向s已經(jīng)走過(guò),開(kāi)始從a 剩下的步驟依次類(lèi)推就得到了。
不過(guò)全排列這是一維空間的dfs運(yùn)用,在標(biāo)記時(shí)候可以選擇boolean數(shù)組對(duì)應(yīng)位置true標(biāo)記用過(guò),false表示沒(méi)用過(guò)。除此之外也可使用動(dòng)態(tài)數(shù)組List使用過(guò)先刪除對(duì)應(yīng)位置元素向下遞歸進(jìn)行搜索,然后結(jié)束后再對(duì)應(yīng)位置插入也行(不是很推薦,效率比較低)。
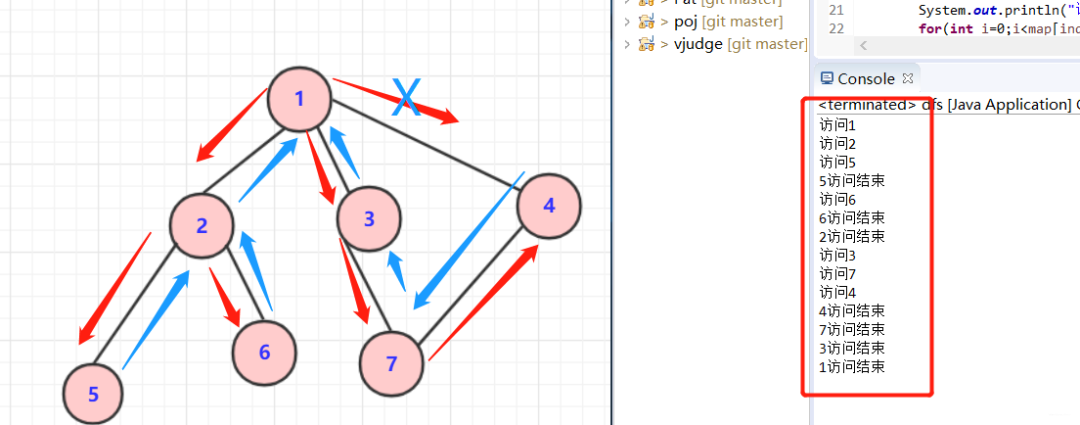
對(duì)于上面圖片中圖的dfs,得到其中一個(gè)dfs搜索的序列(可能有多個(gè))可以用代碼來(lái)表示一下:
- public class dfs {
- static boolean isVisit[];
- public static void main(String[] args) {
- int map[][]=new int[7][7];
- isVisit=new boolean[7];
- map[0][1]=map[1][0]=1;
- map[0][2]=map[2][0]=1;
- map[0][3]=map[3][0]=1;
- map[1][4]=map[4][1]=1;
- map[1][5]=map[5][1]=1;
- map[2][6]=map[6][2]=1;
- map[3][6]=map[6][3]=1;
- isVisit[0]=true;
- dfs(0,map);//從0開(kāi)始遍歷
- }
- private static void dfs(int index,int map[][]) {
- // TODO Auto-generated method stub
- System.out.println("訪(fǎng)問(wèn)"+(index+1)+" ");
- for(int i=0;i<map[index].length;i++)//查找聯(lián)通節(jié)點(diǎn)
- {
- if(map[index][i]>0&&isVisit[i]==false)
- {
- isVisit[i]=true;
- dfs(i,map);
- }
- }
- System.out.println((index+1)+"訪(fǎng)問(wèn)結(jié)束 ");
- }
- }
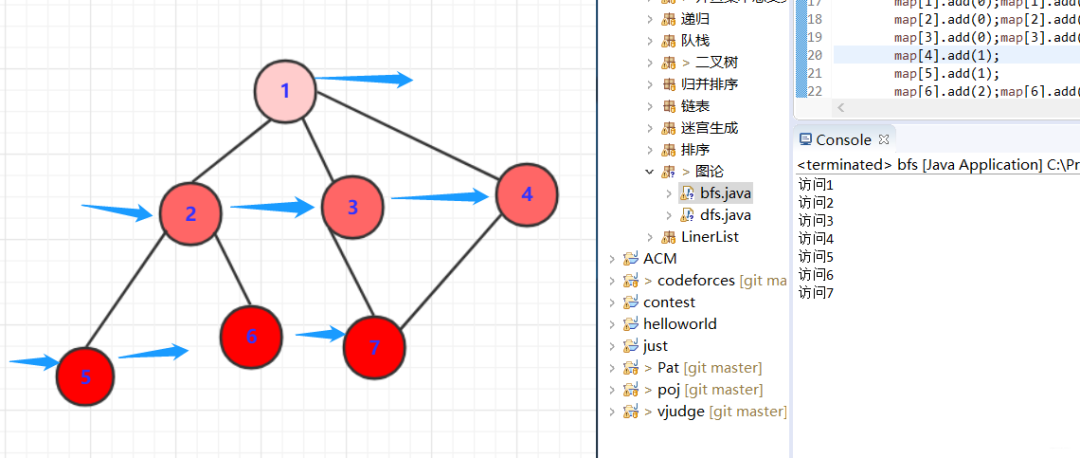
大致順序訪(fǎng)問(wèn)為
廣度優(yōu)先搜素(bfs)
概念:
BFS,其英文全稱(chēng)是Breadth First Search。BFS并不使用經(jīng)驗(yàn)法則算法。從算法的觀點(diǎn),所有因?yàn)檎归_(kāi)節(jié)點(diǎn)而得到的子節(jié)點(diǎn)都會(huì)被加進(jìn)一個(gè)先進(jìn)先出的隊(duì)列中。一般的實(shí)驗(yàn)里,其鄰居節(jié)點(diǎn)尚未被檢驗(yàn)過(guò)的節(jié)點(diǎn)會(huì)被放置在一個(gè)被稱(chēng)為 open 的容器中(例如隊(duì)列或是鏈表),而被檢驗(yàn)過(guò)的節(jié)點(diǎn)則被放置在被稱(chēng)為 closed 的容器中。(open-closed表)
簡(jiǎn)單來(lái)說(shuō),bfs就是從某個(gè)節(jié)點(diǎn)開(kāi)始按層遍歷,估計(jì)大部分人第一次接觸bfs的時(shí)候是在學(xué)習(xí)數(shù)據(jù)結(jié)構(gòu)的二叉樹(shù)的層序遍歷!借助一個(gè)隊(duì)列一層一層遍歷。第二次估計(jì)就是在學(xué)習(xí)圖論的時(shí)候,給你一個(gè)圖,讓你寫(xiě)出一個(gè)bfs遍歷的順序,此后再無(wú)bfs…
如果從路徑上走來(lái)看,dfs就是一條跑的很快的瘋狗,到處亂咬,沒(méi)路了就跑回來(lái)去其他地方繼續(xù),而bfs就像是一團(tuán)毒氣,慢慢延伸!
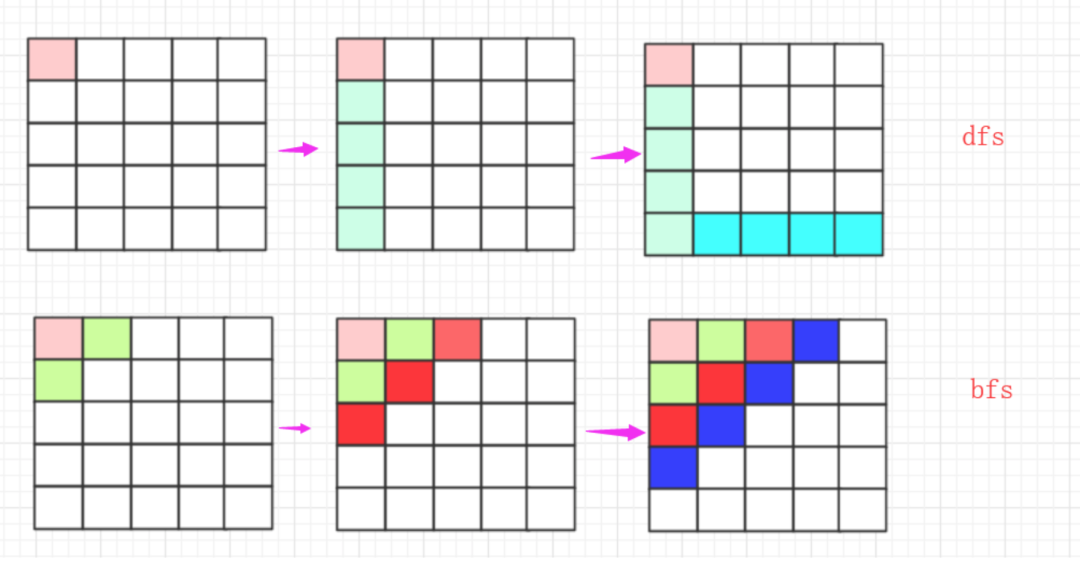
在實(shí)現(xiàn)上樸素的bfs就是控制一個(gè)隊(duì)列,后進(jìn)先出進(jìn)行層序遍歷,但很多時(shí)候可能有場(chǎng)景需求節(jié)點(diǎn)有權(quán)值可能就需要使用優(yōu)先隊(duì)列。
就拿上述的圖來(lái)說(shuō),我們使用鄰接表來(lái)實(shí)現(xiàn)一個(gè)bfs遍歷。
- import java.util.ArrayDeque;
- import java.util.ArrayList;
- import java.util.List;
- import java.util.Queue;
- public class bfs {
- public static void main(String[] args) {
- List<Integer> map[]=new ArrayList[7];
- boolean isVisit[]=new boolean[7];
- for(int i=0;i<map.length;i++)//初始化
- {
- map[i]=new ArrayList<Integer>();
- }
- map[0].add(1);map[0].add(2);map[0].add(3);
- map[1].add(0);map[1].add(4);map[1].add(5);
- map[2].add(0);map[2].add(6);
- map[3].add(0);map[3].add(6);
- map[4].add(1);
- map[5].add(1);
- map[6].add(2);map[6].add(3);
- Queue<Integer>q1=new ArrayDeque<Integer>();
- q1.add(0);isVisit[0]=true;
- while (!q1.isEmpty()) {
- int va=q1.poll();
- System.out.println("訪(fǎng)問(wèn)"+(va+1));
- for(int i=0;i<map[va].size();i++)
- {
- int index=map[va].get(i);
- if(!isVisit[index])
- {
- q1.add(index);
- isVisit[index]=true;
- }
- }
- }
- }
- }
搜索之延伸
本文主要任務(wù)是幫助初學(xué)者認(rèn)清dfs和bfs,比較偏基礎(chǔ),但是事實(shí)中dfs和bfs比較偏向?qū)崙?zhàn)。
對(duì)于dfs和bfs,有些區(qū)別也有些共性,例如在迷宮很多問(wèn)題dfs能解決bfs也能解決。
對(duì)于dfs一般解決的經(jīng)典問(wèn)題有:
- 二叉樹(shù)的搜索遍歷(非層序)
- 經(jīng)典全排列、組合、子集問(wèn)題
- 回溯算法之八皇后問(wèn)題
- 迷宮搜索問(wèn)題(能否找到)
- 其他圖搜索
而bfs一般解決的問(wèn)題有:
- 二叉樹(shù)層序搜索遍歷(各種變形例如分層輸出、之字形等等空間優(yōu)化)
- 無(wú)權(quán)圖的最短路徑
- 其他迷宮搜索問(wèn)題(節(jié)點(diǎn)帶某些權(quán)值的)
- 其他問(wèn)題
當(dāng)然這里面羅列不全,dfs關(guān)注更多的可能是剪枝問(wèn)題或者記憶化,剪枝就是剪掉沒(méi)必要的搜索,記憶化就是防止太多重復(fù)操作。而bfs關(guān)注更多的可能是貪心策略選擇(大部分搜索可能有一些附加的條件)可能需要使用優(yōu)先隊(duì)列來(lái)解決。
然而,當(dāng)數(shù)據(jù)達(dá)到一定程度,我們使用簡(jiǎn)單的方法肯定會(huì)爆炸的。就可能需要一些特殊的巧妙方法處理,比如想不到的剪枝優(yōu)化、優(yōu)先隊(duì)列、A*、dfs套bfs,又或者利用一些非常厲害的數(shù)學(xué)方法比如康托展開(kāi)(逆展開(kāi))等等。而今天在這里,我們談?wù)勲p向bfs,體驗(yàn)一下算法的奧妙!
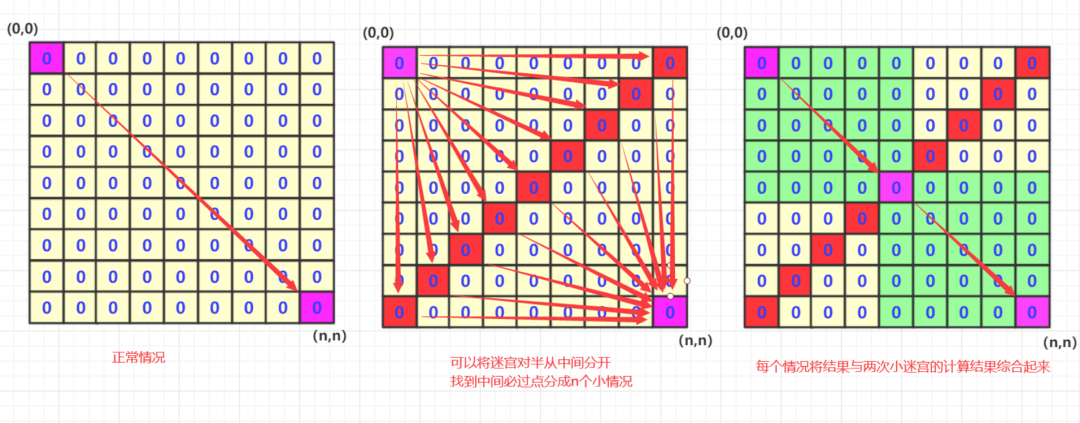
什么樣的情況可以使用雙向bfs來(lái)優(yōu)化呢?其實(shí)雙向bfs的主要思想是問(wèn)題的拆分吧,比如在一個(gè)迷宮中可以往下往右行走,問(wèn)你有多少種方式從左上到右下。
正常情況下,我們就是搜索遍歷,如果迷宮邊長(zhǎng)為n,那么這個(gè)復(fù)雜度大概是2^n級(jí)別.
但是實(shí)際上我們可以將迷宮拆分一下,比如根據(jù)對(duì)角線(xiàn)(比較多),將迷宮一分為二。其實(shí)你的結(jié)果肯定必然經(jīng)過(guò)對(duì)角線(xiàn)的這些點(diǎn)對(duì)吧!我們只要分別計(jì)算出各個(gè)對(duì)角線(xiàn)各個(gè)點(diǎn)的次數(shù)然后相加就可以了!
怎么算? 就是從(0,0)到中間這個(gè)點(diǎn)mid的總次數(shù)為n1,然后這個(gè)mid到(n,n)點(diǎn)的總次數(shù)為n2,然后根據(jù)排列組合總次數(shù)就是n1*n2(n1和n2正常差不多大)這樣就可以通過(guò)乘法減少加法的運(yùn)算次數(shù)啦!
簡(jiǎn)單的說(shuō),從數(shù)據(jù)次數(shù)來(lái)看如果直接搜索全圖經(jīng)過(guò)下圖的那個(gè)點(diǎn)的次數(shù)為n1*n2次,如果分成兩個(gè)部分相乘那就是n1+n2次。兩者差距如果n1,n2=1000左右,那么這么一次差距是平方(根號(hào))級(jí)別的。從搜索圖形來(lái)看其實(shí)這么一次搜索是本來(lái)一個(gè)n*n大小的搜索轉(zhuǎn)變成n次(每次大概是(n/2)*(n/2)大小的迷宮搜索兩次)。也就是如果18*18的迷宮如果使用直接搜索,那么大概2^18次方量級(jí),而如果采用雙向bfs,那么就是2^9這個(gè)量級(jí)。
例題實(shí)戰(zhàn)一下,就拿一道經(jīng)典雙向bfs問(wèn)題給大家展示一下吧!
題目鏈接:http://oj.hzjingma.com/contest/problem?id=20&pid=8#problem-anchor

分析:對(duì)于題目的要求還是很容易理解的,就是找到所有的路徑種類(lèi),再判斷其中是對(duì)稱(chēng)路徑的有幾個(gè)輸出即可!
對(duì)于一個(gè)普通思考是這樣的,首先是進(jìn)行dfs,然后動(dòng)態(tài)維護(hù)一個(gè)字符串,每次跑到最后判斷這個(gè)路徑字符串是否滿(mǎn)足對(duì)稱(chēng)要求,如果滿(mǎn)足那么就添加到容器中進(jìn)行判斷。可惜很遺憾這樣是超時(shí)的,僅能通過(guò)40%的樣例。
接著用普通bfs進(jìn)行嘗試,維護(hù)一個(gè)node節(jié)點(diǎn),每次走的時(shí)候路徑儲(chǔ)存起來(lái)其實(shí)這個(gè)效率跟dfs差不多依然超時(shí)。只能通過(guò)40%數(shù)據(jù)。
接下來(lái)就開(kāi)始雙向bfs進(jìn)行分析!
(1) 既然只能右下,那么對(duì)角線(xiàn)的那個(gè)位置的肯定是中間的那個(gè)字符串的!它的存在不影響是否對(duì)稱(chēng)的(n*n的迷宮路徑長(zhǎng)度為n-1 + n為奇數(shù)).
(2) 我們判斷路徑是否對(duì)稱(chēng),只需要判斷從(1,1)到對(duì)角節(jié)點(diǎn)k(設(shè)為k節(jié)點(diǎn))的路徑有沒(méi)有和從(n,n)到k相同的。如果有路徑相同的那么就說(shuō)明這一對(duì)構(gòu)成對(duì)稱(chēng)路徑
(3) 在具體實(shí)現(xiàn)上,我們對(duì)每個(gè)對(duì)角線(xiàn)節(jié)點(diǎn)可以進(jìn)行兩次bfs(一次左上到(1,1),一次右下到(n,n)).并且將路徑放到兩個(gè)hashset(set1,set2)中,跑完之后用遍歷其中一個(gè)hashset中的路徑,看看另一個(gè)set是否存在該路徑,如果存在就說(shuō)明這個(gè)是對(duì)稱(chēng)路徑放到 總的hashset(set) 中。對(duì)角線(xiàn)每個(gè)位置都這樣判斷完最后只需要輸出總的hashset(set)的集合大小即可!
ac代碼如下:
- import java.util.ArrayDeque;
- import java.util.HashSet;
- import java.util.Queue;
- import java.util.Scanner;
- import java.util.Set;
- public class test2 {
- static class node{
- int x;
- int y;
- String path="";
- public node() {}
- public node(int x,int y,String team)
- {
- this.x=x;
- this.y=y;
- this.path=team;
- }
- }
- public static void main(String[] args) {
- Scanner sc=new Scanner(System.in);
- Set<String>set=new HashSet<String>();//儲(chǔ)存最終結(jié)果
- int n=Integer.parseInt(sc.nextLine());
- char map[][]=new char[n][n];
- for(int i=0;i<n;i++)
- {
- String string=sc.nextLine();
- map[i]=string.toCharArray();
- }
- Queue<node>q1=new ArrayDeque<node>();//左上的隊(duì)列
- Queue<node>q2=new ArrayDeque<node>();//右下的隊(duì)列
- for(int i=0;i<n;i++)
- {
- q1.clear();q2.clear();
- Set<String>set1=new HashSet<String>();//儲(chǔ)存zuoshang
- Set<String>set2=new HashSet<String>();//儲(chǔ)右下
- q1.add(new node(i,n-1-i,""+map[i][n-1-i]));
- q2.add(new node(i,n-1-i,""+map[i][n-1-i]));
- while(!q1.isEmpty()&&!q2.isEmpty())
- {
- node team=q1.poll();
- node team2=q2.poll();
- if(team.x==n-1&&team.y==n-1)//到終點(diǎn),將路徑儲(chǔ)存
- {
- //System.out.println(team2.path);
- set1.add(team.path);
- set2.add(team2.path);
- }
- else {
- if(team.x<n-1)//可以向下
- {
- q1.add(new node(team.x+1, team.y, team.path+map[team.x+1][team.y]));
- }
- if(team.y<n-1)//可以向右
- {
- q1.add(new node(team.x, team.y+1, team.path+map[team.x][team.y+1]));
- }
- if(team2.x>0)//上
- {
- q2.add(new node(team2.x-1, team2.y, team2.path+map[team2.x-1][team2.y]));
- }
- if(team2.y>0)//左
- {
- q2.add(new node(team2.x, team2.y-1, team2.path+map[team2.x][team2.y-1]));
- }
- }
- }
- for(String va:set1)
- {
- if(set2.contains(va))
- {
- set.add(va);
- }
- }
- }
- System.out.println(set.size());
- }
- }

總結(jié)
dfs和bfs是圖論中非常經(jīng)典的搜索算法,兩種算法的重要程度都非常高,這里面主要對(duì)其簡(jiǎn)單介紹,對(duì)于普通開(kāi)發(fā)者,能夠用dfs和bfs能夠解決二叉樹(shù)問(wèn)題、迷宮搜索問(wèn)題等基礎(chǔ)簡(jiǎn)單的就夠了(面試官不會(huì)那么騷難為你)。
如果理解比較困難,多看教程、多刷題,多刷題之后每做一題算法跑的大概流程是有個(gè)數(shù)的。




















