Nature盤點的這些代碼,個個都改變了科學(xué)
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
今天,Nature的一篇報道有點不同。
沒有說最新的科學(xué)研究進展,也沒有說這個時代的科學(xué)家們。
而是將鏡頭聚焦在計算機上,更具體一點,是聚焦在計算機代碼上。

在過去的一年中,Nature對數(shù)十名研究人員進行了調(diào)查,以選出這幾十年以來,改變研究的關(guān)鍵代碼。
現(xiàn)在,評選結(jié)果新鮮出爐。
簡單看了下,有半世紀(jì)的“語言先驅(qū)”、“祖宗之法”Fortran,理工科的老朋友了,相信個中滋味很多人都能體會。
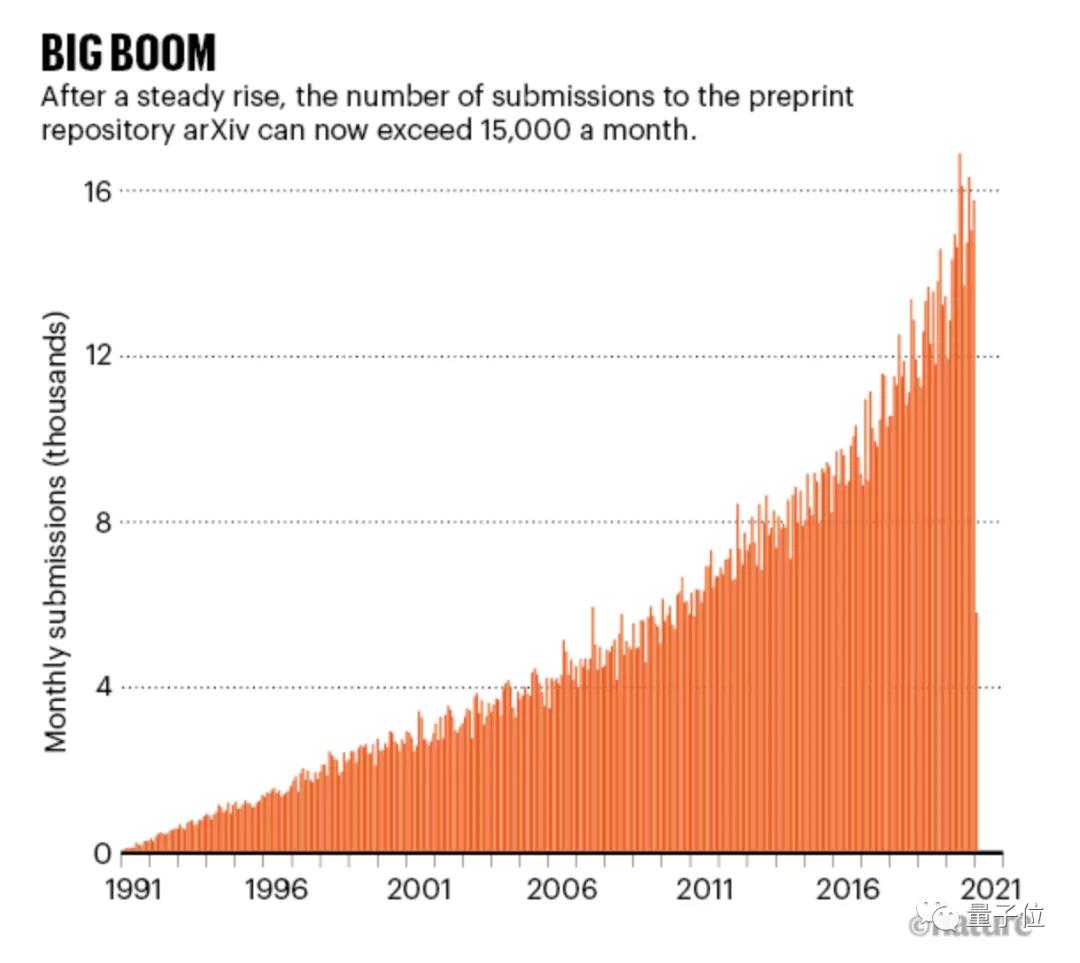
還有不知不覺已經(jīng)“而立之年”的論文利器arXiv.org——全球最大的免費預(yù)印本平臺,每月吸引超過15000份投稿和3000萬次下載。
……
究竟還有哪些代碼改變了現(xiàn)在的科學(xué)?Nature又為何Pick這些代碼?
“語言先驅(qū)”Fortran(1957)
說到Fortran,相信很多大學(xué)生都受到它的摧殘“洗禮”。
在知乎上有一個2015年的古早問答:“和 C++ 相比,用 Fortran 編程是怎樣的體驗?”
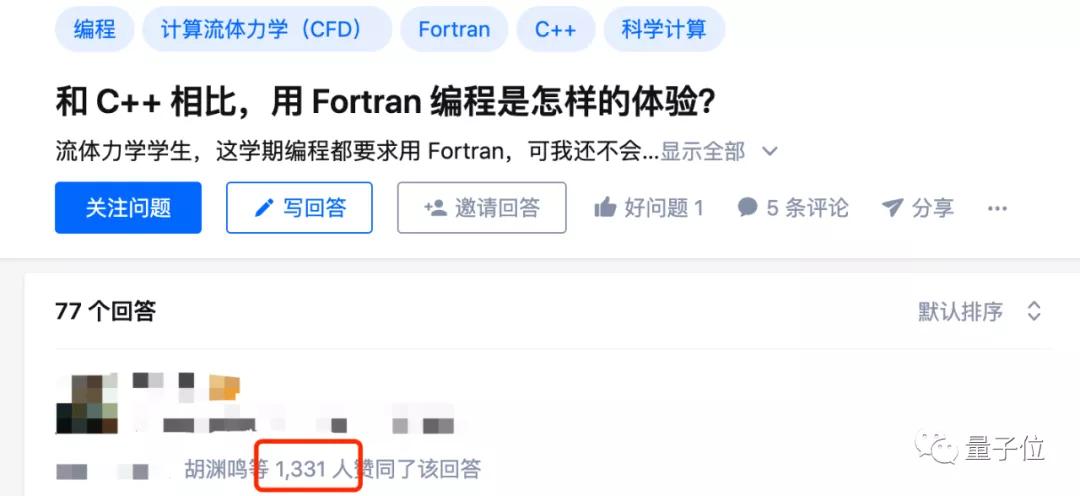
其中一個高贊回答講述了他被Fortran“洗禮”的經(jīng)歷,引發(fā)廣泛共鳴,得到了1331個點贊。
即便如此,依然沒辦法磨滅它在語言界的地位。
最早的現(xiàn)代計算機對用戶,尤其對科學(xué)家并不友好。其中的機器語言、編程語言需要科學(xué)家對計算機的體系結(jié)構(gòu)有深入的了解。
直到在上個世紀(jì)50年代,IBM團隊開發(fā)了“公式翻譯語言”Fortran,情況發(fā)生了改變。
普林斯頓大學(xué)的氣候?qū)W家Syukuro Manabe表示,F(xiàn)ortran使非計算機科學(xué)家的研究人員可以訪問程序。
他和他的同事使用該語言開發(fā)了全球第一個氣候模型,被美國國家海洋和大氣管理局200年來發(fā)生的十大突破之一。
如今,F(xiàn)ortran已經(jīng)發(fā)展到第八個十年了,它仍然被廣泛地應(yīng)用于氣候建模、流體動力學(xué)、計算化學(xué)等一些涉及復(fù)雜計算的學(xué)科。
古早的Fortran代碼庫仍然活躍在實驗室和全球的超級計算機上。
而立之年的arXiv.org(1991)
一定沒有想過,幾乎所有科研人員都使用過的論文福音——arXiv已進入第三十個年頭。
目前,它已經(jīng)收錄約180萬份預(yù)印本,全部免費提供大家交流。
每月的投稿和下載數(shù)量也一直只增不減。
據(jù)Nature統(tǒng)計,現(xiàn)在每月將吸引了15000多份投稿和約3000萬次下載。
而它一開始,也不過只是一個聚焦于高能物理的電子郵件自動回復(fù)系統(tǒng)。
在沒有arXiv之前,科學(xué)家們大多通過郵寄的方式將提交的手稿副本寄給同事,以征求評價。
但寄出的數(shù)量有限,看到論文的也不過幾個人。
見到此狀,一位墨西哥州工作的高能物理學(xué)家Ginsparg決定編寫了一個電子郵件自動回復(fù)系統(tǒng)。
訂閱者每天都會收到預(yù)印本的清單,每個清單都有一個文章標(biāo)識符。
于是,通過一封電子郵件,世界各地的用戶可以從實驗室的計算機系統(tǒng)中提交或檢索文章,獲得新文章列表或按作者、標(biāo)題搜索。
一開始,Ginsparg計劃是將文章保留三個月,論文內(nèi)容限制在高能物理學(xué)界。
但在同事的說服之下,1993年他將該系統(tǒng)遷移到互聯(lián)網(wǎng)上。5年之后,他給它起了今天的名字:arXiv.org。
Hinton指導(dǎo)的AlexNet(2012年)
如果要說當(dāng)前更接地氣一點,就要提到這個快速學(xué)習(xí)AI——AlexNet。
一開始,人工智能有兩種。一種是使用編碼規(guī)則,另一種使用計算機通過模擬大腦的神經(jīng)結(jié)構(gòu)來“學(xué)習(xí)”,幾十年來,人工智能研究人員一直將后一種方法視為“廢話”。直到2012年,Hinton改變了這一格局。
最初的ImageNet全球挑戰(zhàn)賽,最好的算法錯誤率也有25%之高。
而Hinton的兩位研究生提出的這個AlexNet,一種深度學(xué)習(xí)算法,直接將錯誤率降低到了16%。
Hinton表示,我們基本上將錯誤率降低了一半,或者說幾乎降低了一半。而這樣的成績,揭開了深度學(xué)習(xí)在各個領(lǐng)域上的應(yīng)用。
200年“歷史”的快速傅里葉變換(1965)
相信很多數(shù)學(xué)、工程領(lǐng)域的同學(xué)都對它很熟悉, 快速傅里葉變換 (fast Fourier transform) 即利用計算機快速計算離散傅里葉變換(DFT)的統(tǒng)稱,簡稱FFT。
值得一提的是,這里的基本思想早在1805年就已推導(dǎo)出來,但直到在1965年才得到普及。
來自美國的兩位數(shù)學(xué)家James Cooley和John Tukey提出利用算法讓計算所需要的乘法次數(shù)大為減少,特別是被變換的抽樣點數(shù)N越多,F(xiàn)FT算法計算量的節(jié)省就越顯著,計算速度也會提高。
比如,對于1000抽樣點數(shù),速度提升約100倍;對于100萬點,速度提升5萬倍。
由此,快速傅里葉變換開啟了數(shù)字信號處理、圖像分析、結(jié)構(gòu)生物學(xué)等方面的應(yīng)用。它曾被IEEE科學(xué)與工程計算期刊列入20世紀(jì)十大算法。
軟件驅(qū)動的生物數(shù)據(jù)庫(1865)
數(shù)據(jù)庫已經(jīng)成為當(dāng)今科學(xué)研究的一個重要組成部分,以至于很少有人注意到它其實是由軟件驅(qū)動的。
在過去十幾年中,數(shù)據(jù)庫以肉眼可見的速度影響了很多領(lǐng)域,但也許沒有什么地方可以比生物學(xué)更為顯著。
不管是從蛋白質(zhì)序列發(fā)現(xiàn)癌癥致病因子,還是合成生物學(xué)等領(lǐng)域都少不了龐大基因組和蛋白質(zhì)數(shù)據(jù)庫的工作。
上個世紀(jì)60年代初,當(dāng)生物學(xué)家還在努力拆解蛋白質(zhì)的氨基酸序列時,Margaret Dayhoff(生物信息學(xué)先驅(qū))則開始默默整理這些蛋白質(zhì)信息,創(chuàng)建蛋白質(zhì)和核酸數(shù)據(jù)庫以及查詢數(shù)據(jù)庫的工具。
她的《蛋白質(zhì)序列和結(jié)構(gòu)圖譜》在1965年首次出版,描述了當(dāng)時已知的65種蛋白質(zhì)的序列、結(jié)構(gòu)和相似性。而且她還將其數(shù)據(jù)編碼在打孔卡中,這使得擴大數(shù)據(jù)庫并進行搜索成為可能。
之后,更多計算機化的生物數(shù)據(jù)庫也隨之而來,蛋白質(zhì)數(shù)據(jù)庫于1971年上線,今天它詳細(xì)記錄了17萬多個大分子結(jié)構(gòu)。
天氣預(yù)報員:一般流通模型(1969年)
“螞蟻搬家蛇過道,明天必有大雨到。”
以前的天氣預(yù)報都是依靠人們的經(jīng)驗和直覺,直到這個模型——一般流通模型的出現(xiàn),根據(jù)物理定律進行氣候建模的工作,由此開啟了計算機預(yù)測天氣的時代。
在20世紀(jì)40年代末,現(xiàn)代計算機之父約翰·馮·諾依曼便成立了他的天氣預(yù)測小組。
1955年,第二個團隊—地球物理流體動力學(xué)實驗室也開始了所謂的 “無限預(yù)報”—即氣候建模的工作。
直到1969年,這其中才有人真正做出了天氣預(yù)測模型,使其首次能夠在硅片中測試二氧化碳水平上升的影響。,創(chuàng)造了2006年Nature形容的科學(xué)計算的“里程碑”。
今天的模型可以將地球表面劃分為25×25公里的方塊,將大氣層劃分為幾十個層次。
相比之下,Manabe和Bryan的海洋-大氣組合模型,使用的是500公里的方塊和9個層次,只覆蓋了全球的六分之一。
除此之外,還有數(shù)字處理者BLAS,顯微鏡必不可少的NIH Image,序列搜索器BLAST,數(shù)據(jù)瀏覽器IPython Notebook。
好了,你Pick哪一款?如果其他心儀的代碼,歡迎與我們分享。